

Samudyata Bhat
Samudyata Bhat is a former Content Marketing Specialist at G2. With a Master's degree in digital marketing, she specializes her content around SaaS, hybrid cloud, network management, and IT infrastructure. She aspires to connect with present-day trends through data-driven analysis and experimentation and create effective and meaningful content. In her spare time, she can be found exploring unique cafes and trying different types of coffee.
Supponiamo che tu gestisca una libreria online di grandi dimensioni. È sempre aperta. Ogni minuto o secondo, i clienti effettuano e pagano ordini. Il tuo sito web deve eseguire rapidamente numerose transazioni utilizzando dati modesti, come ID utente, numeri di carte di pagamento e informazioni sugli ordini.
Oltre a svolgere le attività quotidiane, devi anche valutare le tue prestazioni. Ad esempio, analizzi le vendite di un libro o autore specifico del mese precedente per decidere se ordinarne di più per questo mese. Ciò comporta la raccolta di dati transazionali e il loro trasferimento da un database che supporta le transazioni a un altro sistema che gestisce grandi quantità di dati. E, come è comune, i dati devono essere trasformati prima di essere caricati in un altro sistema di archiviazione.
Solo dopo questi set di azioni puoi esaminare i dati con software dedicati. Ma come sposti i dati? Se non conosci la risposta, probabilmente hai bisogno di una migliore infrastruttura software, come soluzioni di scambio dati, strumenti di estrazione, trasformazione e caricamento (ETL), o soluzioni DataOps.
Probabilmente hai bisogno di imparare cosa può fare una pipeline di dati per te e la tua azienda. Probabilmente hai bisogno di continuare a leggere.
Cos'è una pipeline di dati?
Una pipeline di dati è un processo che coinvolge l'acquisizione di dati grezzi da numerose fonti di dati e il loro trasferimento in un repository di dati, come un data lake o un data warehouse, per l'analisi.
Una pipeline di dati è un insieme di passaggi per l'elaborazione dei dati. Se i dati devono ancora essere importati nella piattaforma dati, vengono acquisiti all'inizio della pipeline. Segue una successione di fasi, ciascuna delle quali produce un output che serve come input per il passaggio successivo. Questo continua fino a quando l'intera pipeline è costruita. In alcuni casi, i passaggi indipendenti possono coincidere.
Componenti della pipeline di dati
Prima di immergerci nel funzionamento interno delle pipeline di dati, è essenziale comprendere i loro componenti.
- L'origine è il punto di ingresso per i dati da tutte le fonti di dati nella pipeline. La maggior parte delle pipeline ha origine da applicazioni di elaborazione transazionale, interfacce di programmazione delle applicazioni (API), o sensori di dispositivi Internet delle Cose (IoT) o sistemi di archiviazione come data warehouse o data lake.
- La destinazione è l'ultimo luogo in cui i dati vanno. Il caso d'uso determina la destinazione finale.
- Flusso di dati è il trasporto dei dati dalla fonte alla destinazione e le modifiche apportate ad essi. ETL è una delle metodologie di flusso di dati più spesso utilizzate.
- Archiviazione si riferisce ai sistemi che mantengono i dati in varie fasi mentre si muovono attraverso la pipeline.
- Elaborazione comprende tutte le attività e le fasi coinvolte nel consumo, archiviazione, modifica e posizionamento dei dati. Mentre l'elaborazione dei dati è correlata al flusso di dati, questa fase si concentra sull'implementazione.
- Flusso di lavoro specifica una serie di processi e le loro dipendenze l'uno dall'altro.
- Monitoraggio garantisce che la pipeline e le sue fasi funzionino correttamente ed eseguano le funzioni necessarie.
- Tecnologia si riferisce all'infrastruttura e agli strumenti che supportano la trasmissione dei dati, l'elaborazione, l'archiviazione, il flusso di lavoro e il monitoraggio.
Vuoi saperne di più su Strumenti ETL? Esplora i prodotti Strumenti ETL.
Come funziona la pipeline di dati?
I dati vengono generalmente elaborati prima di fluire in un repository. Questo inizia con la preparazione dei dati, in cui i dati vengono puliti e arricchiti, seguiti dalla trasformazione dei dati per filtrare, mascherare e aggregare i dati per la loro integrazione e uniformità. Questo è particolarmente significativo quando la destinazione finale del dataset è un database relazionale. I database relazionali hanno uno schema predefinito che deve essere allineato per abbinare colonne e tipi di dati per aggiornare i vecchi dati con i nuovi.
Immagina di raccogliere informazioni su come le persone interagiscono con il tuo marchio. Questo potrebbe includere la loro posizione, dispositivo, registrazioni delle sessioni, acquisti e cronologia delle interazioni con il servizio clienti. Poi metti tutte queste informazioni in un magazzino per creare un profilo per ciascun consumatore.
Come suggerisce il nome, le pipeline di dati servono come "tubo" per progetti di data science o dashboard di business intelligence. I dati provengono da varie fonti, comprese API, linguaggio di query strutturato (SQL) o database NoSQL; tuttavia, non sono sempre adatti per un uso immediato.
Gli scienziati o ingegneri dei dati di solito svolgono compiti di preparazione dei dati. Formattano i dati per soddisfare i requisiti del caso d'uso aziendale. Una combinazione di analisi esplorativa dei dati e esigenze aziendali stabilite spesso decide il tipo di elaborazione dei dati che una pipeline richiede. I dati possono essere conservati e visualizzati quando correttamente filtrati, combinati e riassunti.
Le pipeline di dati ben organizzate sono la base per varie iniziative, tra cui analisi esplorativa dei dati, visualizzazione e attività di apprendimento automatico (ML).
Tipi di pipeline di dati
Elaborazione batch e streaming di dati in tempo reale sono i due tipi di base di pipeline di dati.
Elaborazione batch dei dati
Come indica il nome, l'elaborazione batch carica "batch" di dati in un repository a intervalli predeterminati, spesso pianificati durante le ore non di punta. Altri carichi di lavoro non sono disturbati poiché i lavori di elaborazione batch operano tipicamente con enormi quantità di dati, che potrebbero sovraccaricare l'intero sistema. Quando non c'è un bisogno urgente di esaminare un dataset specifico (ad esempio, contabilità mensile), l'elaborazione batch è la migliore pipeline di dati. È associata al processo di integrazione dei dati ETL.
ETL ha tre fasi:
- Estrazione: ottenere dati grezzi da una fonte, come un database, un file XML o una piattaforma cloud contenente dati per strumenti di marketing, sistemi CRM o sistemi transazionali.
- Trasformazione: cambiare il formato o la struttura del dataset per adattarlo al sistema di destinazione.
- Caricamento: trasferire il dataset al sistema di destinazione, che potrebbe essere un'applicazione o un database, data lakehouse, data lake o data warehouse.
Streaming di dati in tempo reale
A differenza dell'elaborazione batch, lo streaming di dati in tempo reale indica che i dati devono essere continuamente aggiornati. App e sistemi di punto vendita (PoS), ad esempio, richiedono dati in tempo reale per aggiornare l'inventario degli articoli e la cronologia delle vendite; questo consente ai commercianti di informare i consumatori se un prodotto è disponibile. Un'azione singola, come una vendita di un prodotto, è indicata come "evento", e eventi correlati, come l'aggiunta di un articolo al carrello, sono solitamente raggruppati come "argomento" o "flusso". Questi eventi sono successivamente instradati attraverso sistemi di messaggistica o broker di messaggi, come Apache Kafka, un prodotto open-source.
Le pipeline di dati in streaming offrono una latenza inferiore rispetto ai sistemi batch perché gli eventi di dati vengono gestiti immediatamente dopo che si verificano. Tuttavia, sono meno affidabili dei sistemi batch poiché i messaggi potrebbero essere persi involontariamente o trascorrere molto tempo in coda. I broker di messaggi aiutano a risolvere questo problema con gli ack, il che significa che un consumatore verifica l'elaborazione del messaggio al broker in modo che possa essere rimosso dalla coda.
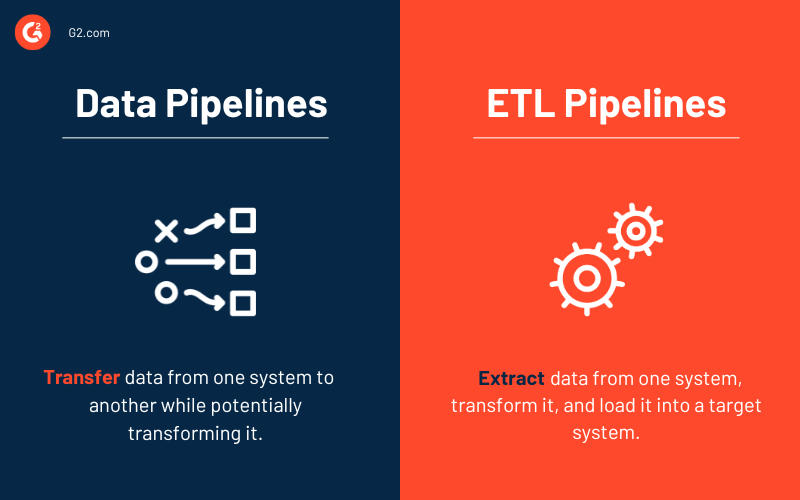
Pipeline di dati vs. pipeline ETL
Alcune parole, come pipeline di dati e pipeline ETL, possono essere usate in modo intercambiabile. Tuttavia, considera una pipeline ETL un sottotipo della pipeline di dati. Tre caratteristiche fondamentali separano i due tipi di pipeline.
- Le pipeline ETL seguono un ordine prestabilito. Come suggerisce l'acronimo, estraggono, convertono, caricano e memorizzano i dati in un repository. Questo ordine non è richiesto per tutte le pipeline di dati. Infatti, l'emergere di soluzioni cloud-native ha aumentato l'uso delle pipeline ETL. L'acquisizione dei dati viene ancora prima con questo tipo di pipeline, ma eventuali trasformazioni avvengono dopo che i dati sono stati caricati nel data warehouse cloud.
- Sebbene l'ambito delle pipeline di dati sia maggiore, le pipeline ETL coinvolgono frequentemente l'elaborazione batch. Potrebbero anche includere l'elaborazione in streaming.
- Infine, a differenza delle pipeline ETL, le pipeline di dati nel loro insieme potrebbero non richiedere sempre trasformazioni dei dati. Quasi ogni pipeline di dati utilizza trasformazioni per facilitare l'analisi.
Architettura della pipeline di dati
Il design di una pipeline di dati comprende tre fasi chiave.
- Acquisizione dei dati. I dati vengono acquisiti da molte fonti, inclusi dati strutturati e non strutturati. Queste fonti di dati grezzi sono comunemente chiamate produttori, editori o mittenti nel contesto dei dati in streaming. Mentre le organizzazioni potrebbero scegliere di estrarre i dati solo quando sono pronte ad analizzarli, è meglio prima depositare i dati grezzi in un fornitore di data warehouse cloud. Questo consente all'azienda di modificare eventuali dati passati se devono cambiare le operazioni di elaborazione dei dati.
- Trasformazione dei dati. Durante questa fase, viene condotta una serie di attività per convertire i dati nel formato richiesto dal repository di dati di destinazione. Queste attività incorporano automazione e governance per flussi di lavoro ripetuti, come i report aziendali, garantendo che i dati siano costantemente puliti e convertiti. Un flusso di dati, ad esempio, potrebbe essere in formato JavaScript Object Notation (JSON) stratificato, e il passaggio di trasformazione dei dati tenterà di srotolare quel JSON per estrarre i campi essenziali per l'analisi.
- Repository di dati. I dati trasformati vengono successivamente memorizzati in un repository e resi disponibili a più stakeholder. I dati alterati sono talvolta chiamati consumatori, abbonati o ricevitori.
Vantaggi delle pipeline di dati
Le aziende tendono a conoscere le pipeline di dati e come aiutano le imprese a risparmiare tempo e mantenere i loro dati strutturati quando stanno crescendo o cercando soluzioni migliori. Di seguito sono riportati alcuni vantaggi delle pipeline di dati che le aziende potrebbero trovare attraenti.
- Qualità dei dati si riferisce a quanto sia facile per gli utenti finali monitorare e accedere ai dati rilevanti mentre si spostano dalla fonte alla destinazione.
- Le pipeline consentono agli utenti di generare flussi di dati iterativamente. Puoi prendere una piccola fetta di dati dalla fonte di dati e presentarla all'utente.
- Replicabilità dei modelli può essere riutilizzata e riproposta per nuovi flussi di dati. Sono una rete di pipeline che genera un metodo di pensiero in cui le singole pipeline sono viste come esempi di modelli in un design più ampio.
Sfide con le pipeline di dati
Costruire una pipeline di dati ben architettata e ad alte prestazioni richiede pianificazione e progettazione di molteplici aspetti dell'archiviazione dei dati, come la struttura dei dati, il design dello schema, la gestione dei cambiamenti dello schema, l'ottimizzazione dell'archiviazione e la rapida scalabilità per soddisfare aumenti imprevisti del volume dei dati dell'applicazione. Questo spesso richiede l'uso di una tecnica ETL per organizzare la trasformazione dei dati in molte fasi. Devi anche garantire che i dati acquisiti siano controllati per la qualità o la perdita dei dati e che i fallimenti dei lavori e le eccezioni siano monitorati.
Di seguito sono riportati alcuni dei problemi più comuni che sorgono lavorando con le pipeline di dati.
- Aumento del volume di dati elaborati
- Cambiamenti nella struttura dei dati di origine
- Dati di scarsa qualità
- Insufficiente integrità dei dati nei dati di origine
- Duplicazione dei dati
- Ritardo dei file di dati di origine
- Mancanza di un'interfaccia per sviluppatori per i test
Casi d'uso delle pipeline di dati
La gestione dei dati sta diventando una preoccupazione sempre più importante man mano che i dati estesi crescono. Mentre le pipeline di dati servono a vari scopi, di seguito sono riportate tre principali applicazioni commerciali.
- Analisi esplorativa dei dati (EDA) valuta e indaga i set di dati e riporta le loro proprietà principali, utilizzando tipicamente approcci di visualizzazione dei dati. Aiuta a determinare come modificare le fonti di dati per ottenere le risposte necessarie, rendendo più semplice per gli scienziati dei dati scoprire modelli, rilevare anomalie, testare ipotesi e convalidare assunzioni.
- Visualizzazioni dei dati utilizzano visuali popolari per descrivere i dati: grafici, diagrammi, infografiche e animazioni. Queste visualizzazioni delle informazioni spiegano complesse relazioni tra dati e intuizioni basate sui dati in un modo facile da comprendere.
- Apprendimento automatico è un sottocampo dell'intelligenza artificiale (AI) e della scienza informatica che utilizza dati e algoritmi per imitare il modo in cui le persone apprendono, migliorando gradualmente la sua accuratezza. Gli algoritmi sono addestrati a generare classificazioni o previsioni utilizzando approcci statistici, rivelando intuizioni cruciali nelle iniziative di data mining.
Esempi reali di pipeline di dati
Di seguito sono riportati alcuni esempi IRL di pipeline di dati di aziende che hanno creato pipeline moderne per la loro applicazione.
- Uber ha bisogno di dati in tempo reale per implementare prezzi dinamici, calcolare il tempo di arrivo più probabile e anticipare la domanda e l'offerta. Implementano pipeline di streaming che acquisiscono dati attuali dalle app di conducenti e passeggeri utilizzando tecnologie come Apache Flink. Questi dati in tempo reale sono incorporati in algoritmi di apprendimento automatico, che forniscono previsioni minuto per minuto.
- Hewlett Packard Enterprise sperava di migliorare l'esperienza del cliente con la sua capacità di manutenzione predittiva. Hanno costruito una pipeline di dati efficiente con motori di streaming come Akka Streams, Apache Spark e Apache Kafka.
- Dollar Shave Club richiedeva dati in tempo reale per interagire con ciascun consumatore separatamente. Dopo aver alimentato le informazioni nel suo sistema di raccomandazione, il programma sceglieva quali prodotti promuovere per l'inclusione in un'email mensile indirizzata a singoli clienti. Hanno creato una pipeline di dati automatizzata utilizzando Apache Spark per questa pratica.
Migliori pratiche per le pipeline di dati
Puoi evitare i pericoli significativi delle pipeline di dati mal costruite seguendo le pratiche consigliate di seguito.
- Risoluzione dei problemi semplice: Rimuovendo le dipendenze non necessarie tra i componenti della pipeline di dati, devi solo risalire al sito del fallimento. Semplificare le cose migliora la prevedibilità della pipeline di dati.
- Scalabilità: Man mano che i carichi di lavoro e i volumi di dati crescono esponenzialmente, un design ideale della pipeline di dati dovrebbe essere in grado di scalare ed espandersi.
- Visibilità end-to-end: Puoi garantire coerenza e sicurezza proattiva con monitoraggio continuo e ispezioni di qualità.
- Test: Dopo aver regolato in base ai test di qualità, ora hai un set di dati affidabile da far passare attraverso la pipeline. Dopo aver definito un set di test, puoi eseguirlo in un ambiente di test separato; quindi confrontarlo con la versione di produzione della tua pipeline di dati e la nuova versione.
- Manutenibilità: Procedure ripetibili e rigorosa aderenza ai protocolli supportano una pipeline di dati a lungo termine.
Strumenti per le pipeline di dati
Gli strumenti per le pipeline di dati supportano il flusso, l'archiviazione, l'elaborazione, il flusso di lavoro e il monitoraggio dei dati. Molti fattori influenzano la loro selezione, tra cui la dimensione e il settore dell'azienda, le quantità di dati, i casi d'uso dei dati, il budget e le esigenze di sicurezza.
Di seguito sono riportati i gruppi di soluzioni comunemente utilizzati per costruire pipeline di dati.
Strumenti ETL
Gli strumenti ETL includono soluzioni di preparazione dei dati e integrazione dei dati. Sono principalmente utilizzati per spostare i dati tra database. Replicano anche i dati, che vengono poi memorizzati nei sistemi di gestione dei database e nei data warehouse.
I 5 migliori strumenti ETL:
* Sopra sono riportate le cinque principali soluzioni ETL dal Grid® Report di G2 dell'estate 2023.
Piattaforme DataOps
Le piattaforme DataOps orchestrano persone, processi e tecnologia per fornire una pipeline di dati affidabile ai loro utenti. Questi sistemi integrano tutti gli aspetti della creazione e delle operazioni dei processi di dati.
Le 5 migliori piattaforme DataOps:
* Sopra sono riportate le cinque principali soluzioni DataOps dal Grid® Report di G2 dell'estate 2023.
Soluzioni di scambio dati
Le aziende utilizzano strumenti di scambio dati durante l'acquisizione per inviare, acquisire o arricchire i dati senza alterarne lo scopo principale. I dati vengono trasferiti in modo che possano essere semplicemente acquisiti da un sistema ricevente, spesso normalizzandoli completamente.
41,8%
delle piccole imprese nel settore IT utilizzano soluzioni di scambio dati.
Fonte: dati delle recensioni dei clienti di G2
Varie soluzioni di dati possono lavorare con gli scambi di dati, inclusi piattaforme di gestione dei dati (DMP), software di mappatura dei dati quando si spostano i dati acquisiti nell'archiviazione, e software di visualizzazione dei dati per convertire i dati in dashboard e grafici leggibili.
I 5 migliori strumenti software di scambio dati:
* Sopra sono riportate le cinque principali soluzioni di scambio dati dal Grid® Report di G2 dell'estate 2023.
Altri gruppi di soluzioni per le pipeline di dati includono quanto segue.
- Data warehouse sono repository centrali per l'archiviazione dei dati convertiti per uno scopo specifico. Tutte le principali soluzioni di data warehouse ora caricano dati in streaming e consentono operazioni ETL e trasmettitore di localizzazione di emergenza (ELT).
- Gli utenti memorizzano dati grezzi in data lake fino a quando non ne hanno bisogno per l'analisi dei dati. Le aziende sviluppano pipeline di Big Data basate su ELT per iniziative di apprendimento automatico utilizzando data lake.
- Le aziende possono utilizzare scheduler di flussi di lavoro batch per dichiarare programmaticamente i flussi di lavoro come attività con dipendenze e automatizzare queste operazioni.
- Software di streaming di dati in tempo reale elabora dati continuamente creati da fonti come sensori meccanici, dispositivi IoT e Internet delle cose mediche (IoMT), o sistemi transazionali.
- Strumenti di Big Data includono soluzioni di streaming di dati e altre tecnologie che consentono il flusso di dati end-to-end.

Dati dettagliati datano profondamente
In passato, volumi di dati provenienti da varie fonti erano archiviati in silos separati che non potevano essere accessibili, compresi o analizzati in transito. Per peggiorare le cose, i dati erano lontani dall'essere in tempo reale.
Ma oggi? Man mano che la quantità di fonti di dati cresce, la velocità con cui le informazioni attraversano le organizzazioni e interi settori è più rapida che mai. Le pipeline di dati sono lo scheletro dei sistemi digitali. Trasferiscono, trasformano e memorizzano i dati, fornendo alle aziende come la tua intuizioni significative. Tuttavia, le pipeline di dati devono essere aggiornate per tenere il passo con la crescente complessità e il numero di set di dati.
La modernizzazione richiede tempo e sforzo, ma pipeline di dati efficienti e contemporanee ti permetteranno di prendere decisioni migliori e più rapide, dandoti un vantaggio competitivo.
Vuoi saperne di più sulla gestione dei dati? Scopri come puoi comprare e vendere dati di terze parti!