
Interrupções são implacáveis e acontecem com muita frequência.
Quando ocorrem, geralmente é nos momentos mais inesperados. Talvez alguém tropece em um cabo de energia, ocorra uma falha na rede ou os engenheiros movam um disco e ele seja corrompido.
Seja o que for que aconteça, a interrupção ocorre, e nós nos apressamos para analisar o que deu errado e colocar os servidores de volta em funcionamento o mais rápido possível.
O tempo de atividade é rei. Aumentar o tempo de inatividade do serviço pode impactar negativamente a receita, a confiança na marca, a perda de dados e os rankings de busca.
Uma maneira de lidar com falhas repentinas é usar um componente de espera ou failover. O failover fornece os meios para responder proativamente em vez de reativamente quando ocorrem interrupções inesperadas.
Com as organizações se movendo em direção à continuidade dos negócios na nuvem com software de recuperação de desastres como serviço (DRaaS), é imperativo entender como o failover apoia estratégias de recuperação de desastres (DR) e planos de continuidade de negócios.
O que é failover?
Failover é um modo operacional de backup no qual um sistema secundário assume as funções do sistema primário quando este se torna indisponível. A unidade de backup é ativada automaticamente e de forma contínua, com pouca ou nenhuma interrupção do serviço para os usuários. O failover é geralmente empregado para sistemas críticos e tolerantes a falhas.
O failover é uma parte integral do DRaaS para continuidade de negócios na nuvem. O software DRaaS fornece essa capacidade de failover ao proporcionar uma rápida transferência da carga de trabalho se um serviço cair.
O failover é implementado em sistemas críticos para a missão onde a integridade dos dados e o tempo de atividade são vitais. Em caso de falha, um sistema ou solução alternativa está imediatamente pronto para assumir com pouca interrupção na operação regular.
Em resumo, o failover é crítico para mantê-lo online e em funcionamento. Por exemplo, durante uma falha no data center primário, o failover deve transferir o controle dos sistemas críticos para o data center secundário com mínima interrupção dos serviços ou perda de dados.
O failover pode ocorrer em qualquer parte de um sistema:
- Um gatilho de hardware ou software em um computador pessoal ou dispositivo móvel pode proteger o dispositivo quando um componente, como uma CPU ou uma célula de bateria, falha.
- O failover pode se aplicar a qualquer componente individual de rede ou a um sistema de componentes, como um canal de conexão, dispositivo de armazenamento ou servidor web, dentro de uma rede.
- O failover permite que muitos servidores locais ou baseados na nuvem mantenham uma conexão constante e segura com pouca ou nenhuma interrupção do serviço enquanto usam um banco de dados ou aplicativo web hospedado.
As empresas estabelecem redundância em uma falha inesperada usando um computador, sistema ou servidor de backup que está sempre pronto para entrar em ação automaticamente.
Os designers de sistemas implementam a funcionalidade de failover em servidores, suporte de banco de dados de backend ou redes que requerem disponibilidade consistente e excelente confiabilidade. O failover pode:
- Proteger seu banco de dados durante a manutenção ou uma interrupção do sistema. Por exemplo, se o servidor primário no local cair devido a uma falha de hardware, o servidor de backup (no local ou na nuvem) pode rapidamente assumir as tarefas de hospedagem sem intervenção administrativa.
- Pode ser adaptado às suas configurações específicas de hardware e rede. Enquanto gerencia um banco de dados, um administrador pode empregar não apenas um sistema A ou B de dois servidores funcionando em paralelo para proteger um ao outro, mas também um servidor na nuvem para fornecer solução de problemas, manutenção e correção no local, tudo sem afetar a conectividade.
- Permitir que operações de manutenção ocorram automaticamente sem monitoramento. Uma troca automática durante atualizações periódicas de software fornece proteção contínua contra riscos de segurança cibernética.
Você sabia? Uma troca é essencialmente o mesmo que um failover; no entanto, ao contrário de um failover, não é automatizada e requer interação humana. Soluções de failover automatizadas protegem a maioria dos sistemas.
Por que o failover é importante?
Meramente tolerar ou suportar o tempo de inatividade ou interrupções não é suficiente no mercado global competitivo de hoje. Graças ao failover e suas tecnologias, os clientes podem ter confiança de que podem contar com uma conexão segura sem interrupções inesperadas.
A integração do failover pode ser um fardo indesejado e caro, mas é uma apólice de seguro vital que garante segurança e proteção.
Então, qual é a principal razão para uma empresa ter um sistema de failover? O objetivo principal do failover é prevenir ou reduzir a falha total do sistema. O failover é um componente essencial do plano de DR de cada empresa. Se a arquitetura de rede estiver configurada adequadamente, o failover e o failback fornecerão proteção completa contra a maioria, senão todas, as interrupções de serviço.
Qualquer falha legítima é principalmente causada pela quantidade de troca de dados, a largura de banda disponível e como os dados são movidos, espelhados ou copiados para o segundo site. A prioridade de um engenheiro de sistemas deve ser reduzir a transferência de dados enquanto melhora a qualidade da sincronização entre dois sites.
Depois de garantir a qualidade da transmissão de dados, a próxima questão é determinar como acionar o failover enquanto minimiza o tempo de troca.
Os administradores de TI também podem acionar um failover para facilitar a manutenção e atualização do sistema primário. Isso é conhecido como failover planejado.
Quer aprender mais sobre Soluções de Recuperação de Desastres como Serviço (DRaaS)? Explore os produtos de Recuperação de Desastres como Serviço (DRaaS).
Como o failover funciona?
O failover envolve a restauração de dados, configurações de aplicativos e suporte de infraestrutura para um componente de sistema de espera. Para o usuário final, a operação é contínua. O funcionamento normal continua apesar das interrupções inevitáveis induzidas por falhas de equipamento devido à capacidade de failover automatizado.
Um sistema de failover requer uma ligação direta ao sistema primário para funcionar com sucesso. Isso é conhecido como "batimento cardíaco". O batimento cardíaco envia um pulso do sistema primário para o sistema de failover a cada poucos minutos. A solução de failover permanecerá inativa enquanto o pulso permanecer estável.
Um sistema de batimento cardíaco é comum na automação de failover. Em sua forma mais básica, esse método liga dois sites fisicamente via cabo ou sem fio por meio de uma rede. Quando a regularidade do link de batimento cardíaco é interrompida, o sistema de failover será ativado e assumirá todas as funções do sistema primário. Você pode geralmente projetar suas soluções de failover para alertar imediatamente sua equipe de TI sobre uma falha para que possam trabalhar na restauração do sistema primário o mais rápido possível.
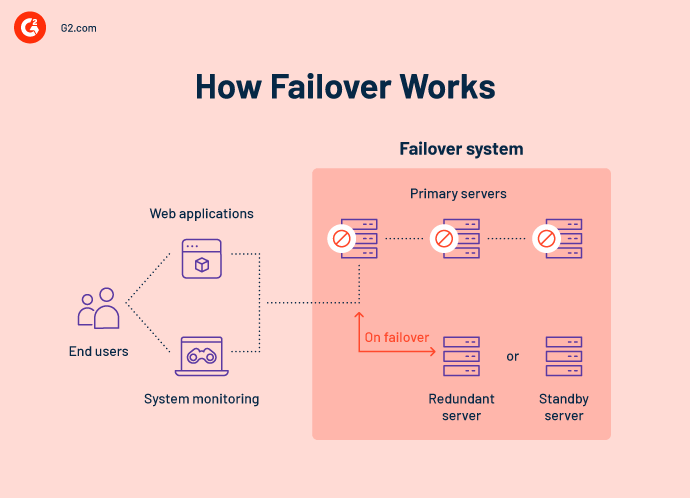
Com base na complexidade do serviço, um sistema pode até ter um terceiro site executando os componentes fundamentais necessários para evitar tempo de inatividade ao mudar. Múltiplos caminhos, componentes redundantes e suporte remoto ou baseado na nuvem fornecem um caminho seguro e sempre conectado.
A virtualização replica um ambiente de computador executando software host em uma VM. Portanto, o mecanismo de failover pode ser independente de hardware.
Esse procedimento é geralmente realizado por um software ou hardware específico que permite essa função complexa. As melhores soluções oferecem automação e orquestração para facilitar os processos de recuperação. Esses sistemas também podem restaurar dados de momentos em vez de horas ou até dias atrás.
A integridade do serviço é crítica para minimizar o tempo de inatividade durante o failover. Você precisará de uma solução DRaaS que conheça seus serviços e possa restaurá-los como um todo (em vez de simplesmente os componentes), resultando em um retorno mais rápido às operações normais de TI.
O que é um cluster de failover?
Um cluster de failover é uma coleção de servidores de computador que trabalham juntos para oferecer disponibilidade contínua (CA), tolerância a falhas (FT) ou alta disponibilidade (HA). As empresas podem construir topologias de rede de cluster de failover inteiramente em hardware físico ou incorporar máquinas virtuais (VMs).
Quando um dos servidores em um cluster de failover quebra, o mecanismo de failover é acionado. Isso reduz o tempo de inatividade transferindo instantaneamente a carga de trabalho do elemento com defeito para outro nó no cluster.
Disponibilidade contínua vs. tolerância a falhas vs. alta disponibilidade
- Disponibilidade contínua é proativa. Enfatiza a redundância, detecção de falhas e prevenção de erros. Tais sistemas permitem planejamento de manutenção e atualizações durante o horário comercial regular sem interromper o serviço.
- Um sistema tolerante a falhas não tem interrupção de serviço, mas custa um pouco mais. Ele depende de hardware dedicado que detecta uma falha e muda instantaneamente para um componente de hardware redundante. Embora a transição pareça suave e forneça serviço contínuo, um preço significativo é pago pelo custo e desempenho do hardware. Isso ocorre porque os componentes redundantes não executam nenhum processamento. Mais importante ainda, o paradigma FT ignora erros de software, a causa mais comum de tempo de inatividade.
- Um sistema de alta disponibilidade (HA) causa interrupção mínima do serviço. HA combina software com hardware padrão da indústria para reduzir o tempo de inatividade restaurando serviços quando os sistemas falham. Tais sistemas são uma excelente solução para serviços que devem ser rapidamente restaurados e suportar uma curta interrupção durante a falha.
O objetivo principal de um cluster de failover é fornecer HA ou CA para aplicativos e serviços. Clusters CA, muitas vezes conhecidos como clusters tolerantes a falhas, reduzem o tempo de inatividade quando um sistema primário falha, permitindo que os usuários finais continuem acessando serviços e aplicativos sem interrupção.
Por outro lado, clusters HA fornecem recuperação automatizada, pouco tempo de inatividade e zero perda de dados, apesar do risco de uma leve interrupção na operação. A maioria das soluções de cluster de failover fornece ferramentas de gerenciamento de cluster de failover que permitem aos administradores controlar o processo.
Um cluster é geralmente dois ou mais servidores ou nós que são comumente ligados programaticamente e fisicamente usando cabos. Alguns sistemas de failover usam tecnologias de cluster adicionais, como balanceamento de carga, processamento paralelo ou simultâneo e soluções de armazenamento.
O que é teste de failover?
O teste de failover confirma a capacidade de um sistema de dedicar recursos adequados à recuperação após uma falha do sistema. Em outras palavras, o teste de failover avalia a capacidade de failover do sistema. O teste verificará se o sistema pode gerenciar recursos adicionais e migrar atividades para sistemas de backup no caso de uma rescisão ou falha inesperada.
Por exemplo, o teste de failover e recuperação verifica a capacidade do sistema de gerenciar e alimentar uma CPU adicional ou muitos servidores uma vez que atinge um limite de desempenho que é frequentemente excedido durante falhas significativas. Isso destaca a ligação crítica entre o teste de failover, resiliência e segurança.
O teste de failover é o processo de simular uma falha em um servidor ou sistema primário para avaliar a eficácia de seus mecanismos de failover. Os aspectos principais incluem:
- Propósito: Verificar se os sistemas de backup podem assumir sem problemas durante falhas inesperadas.
- Cenários: Envolve testar vários cenários de falha, como falhas de servidor ou interrupções de rede.
- Automatizado vs. manual: Isso pode ser feito manualmente ou com ferramentas automatizadas.
- Objetivo de tempo de recuperação (RTO): Mede quão rapidamente o sistema se recupera
- Integridade dos dados: Garante que os dados permaneçam intactos durante o processo de failover.
Tipos de configurações de failover
A técnica de sistema de failover usa tecnologias de cluster existentes para permitir execuções redundantes, aumentando a confiabilidade e acessibilidade dos recursos de TI.
Existem duas configurações básicas para sistemas de failover de alta disponibilidade: ativo-ativo e ativo-passivo. Embora ambas as técnicas de implementação melhorem a confiabilidade, elas alcançam o failover de maneiras diferentes.
1. Configuração ativo-ativo
Uma configuração de alta disponibilidade ativo-ativo geralmente consiste em pelo menos dois nós que estão ativamente e simultaneamente executando o mesmo tipo de serviço. O cluster ativo-ativo realiza balanceamento de carga distribuindo cargas de trabalho uniformemente por todos os nós, limitando qualquer nó de sobrecarregar. À medida que mais nós estão disponíveis, os tempos de resposta e rendimento melhoram.
As configurações e especificações de nós individuais devem ser idênticas para garantir que o cluster HA funcione sem problemas e alcance a redundância. Os balanceadores de carga alocam usuários para nós do cluster com base em um algoritmo. Por exemplo, um algoritmo round-robin distribui usuários uniformemente para servidores com base em quando eles se juntam.
O uso de ambos os nós é dividido em cerca de 50/50, embora cada nó possa gerenciar a carga inteira independentemente. No entanto, se um nó de configuração ativo-ativo rotineiramente gerenciar mais da metade da carga, a perda de nó pode causar uma diminuição no desempenho.
Como ambos os caminhos estão ativos, o tempo de interrupção durante uma falha é quase insignificante com um sistema HA ativo-ativo.
2. Configuração ativo-passivo
Em uma configuração ativo-passivo, também conhecida como configuração de espera ativa, há pelo menos dois nós, mas nem todos estão ativos. Em uma configuração de dois nós, o primeiro nó está operacional, e o segundo nó permanece passivo ou em espera como o sistema de failover.
Este estado operacional de espera pode ser apoiado se o nó primário ativo falhar. Por outro lado, os usuários só se conectam ao servidor ativo até que haja uma falha. O nó inativo é acionado para assumir o processamento de um recurso de TI offline, e a carga de trabalho relacionada é direcionada para o nó secundário, que assume a operação.
O tempo de interrupção é maior em uma configuração ativo-passivo porque o sistema deve se mover de um nó para outro.
Failover vs. failback
Failover e failback são elementos de continuidade de negócios que permitem que as operações digitais regulares continuem mesmo se o site de produção primário estiver indisponível. Considere os procedimentos de failover e failback vitais para uma estrutura sólida de recuperação de desastres.
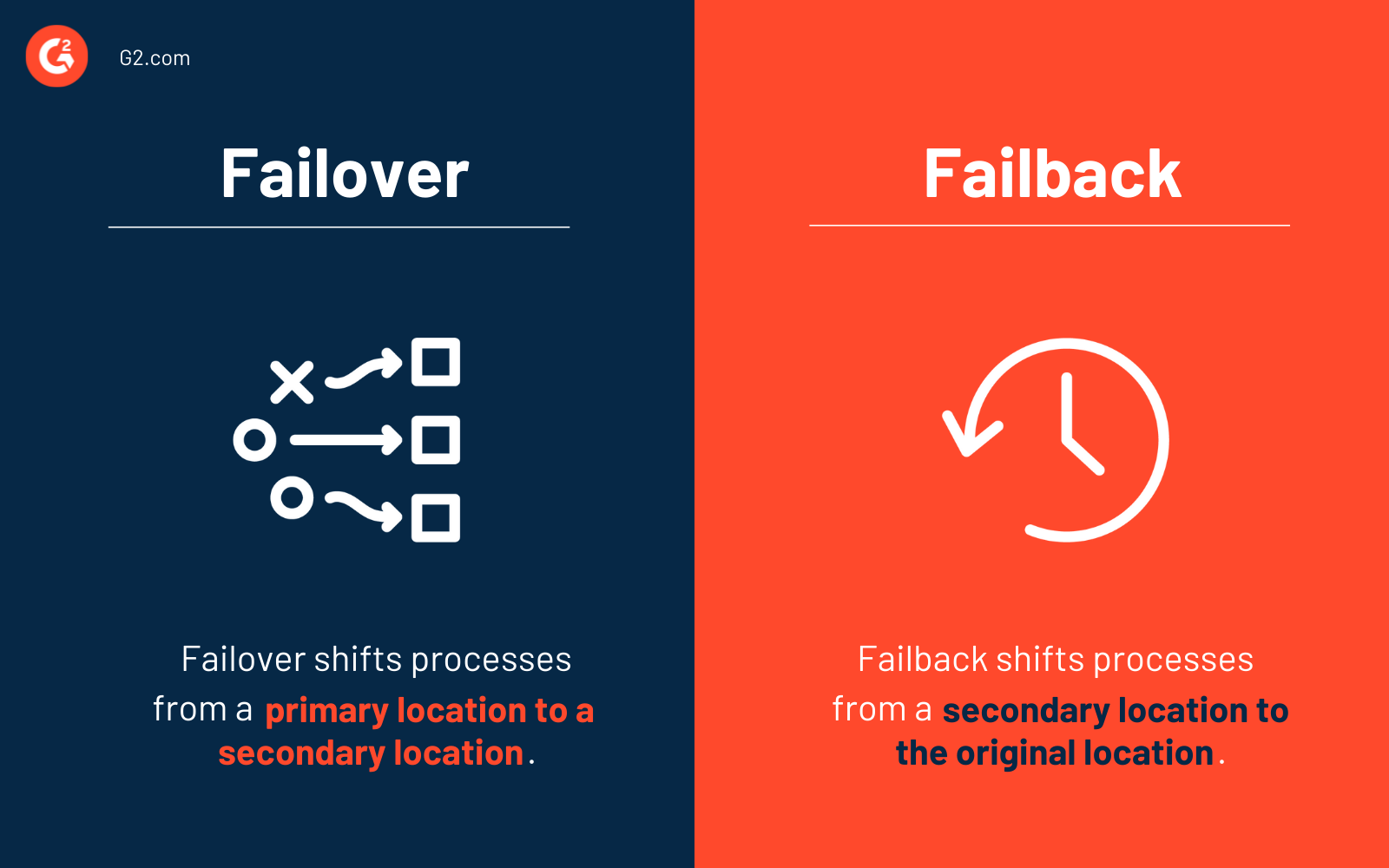
O processo de failover desloca a produção do site primário para um local secundário. Este site de recuperação geralmente contém uma cópia replicada de todos os sistemas e dados do seu site de produção primário. Durante um failover, todas as atualizações são armazenadas virtualmente.
O failback é uma medida de continuidade de negócios implantada quando o site de produção primário está de volta e operando após um desastre (ou um evento programado) ser resolvido. A produção é restaurada para seu antigo (ou novo) site durante um failback, e quaisquer modificações registradas no armazenamento virtual são sincronizadas.
Benefícios do failover
Para empresas centradas na web, o tempo de atividade do serviço é crítico, pois impacta todas as operações. Desde o crescimento organizacional até retenção de clientes e relacionamentos, a alta disponibilidade é o critério essencial que as empresas não podem ignorar. Os benefícios dos sistemas de failover incluem:
- Proteção contra tempo de inatividade: Implementar sistemas de failover eficazes para componentes críticos da pilha de TI de uma organização deve diminuir significativamente o tempo de inatividade causado por interrupções de serviço. Se mesmo um dos componentes críticos do sistema falhar, isso impedirá a operação adequada de cada componente que interage com ele.
- Previne perda de receita: Se uma ferramenta de negócios vital, como seu serviço de processamento de pagamentos, estiver indisponível por um longo tempo, a lucratividade da sua organização sofrerá. Como as ações dos consumidores são voláteis, mesmo uma experiência ruim pode fazer com que os clientes parem permanentemente de usar sua empresa.
Desafios do failover
Muitas vezes, o failover é uma reflexão tardia ou um último recurso. No entanto, ao planejar e testar procedimentos de failover antecipadamente, os gerentes de TI podem prevenir o tempo de inatividade e alcançar níveis consistentes de qualidade de serviço, especialmente quando o inesperado acontece.
Um processo de failover bem lubrificado vem com altos custos e pode aumentar a probabilidade de erro humano no caso de falhas. No entanto, implementar procedimentos eficazes pode reduzir o risco de perda em sistemas críticos e minimizar possíveis interrupções na qualidade do serviço.
Embora o failover pareça um salvador em toda a sua glória, implementar uma estratégia de failover vem com desafios significativos.
Custo aumentado
Configurar, manter e monitorar uma estratégia de failover confiável e protegida é caro. Isso é especialmente verdadeiro se você quiser garantir que cada componente de um cenário complexo e interconectado tenha seu próprio mecanismo de failover exclusivo.
Para construir sistemas de failover confiáveis que funcionem automaticamente com pouco tempo de inatividade, você deve investir dinheiro em sistemas de alta largura de banda que possam lidar com trocas de dados síncronas. A maior parte das despesas gerais de linha para sistemas de failover pode ser atribuída à dependência de expertise de terceiros para instalar e administrar os sistemas.
Processos longos de gerenciamento de sistema e garantia de qualidade (QA)
Um sistema de failover precisa da mesma manutenção e validação de QA que os sistemas primários para proteger efetivamente a tecnologia da sua organização. Executar seus sistemas primários e de failover em versões separadas anula ter sistemas idênticos e sincronizados em primeiro lugar, exigindo mais esforço durante períodos de manutenção apertados.
Você também deve garantir que seus sistemas de failover possam interagir e se envolver frequentemente com os vários componentes do seu ambiente. Essas validações podem aumentar substancialmente o tempo alocado da sua equipe de TI para testes e QA.
Casos de uso de failover
O failover pode ocorrer em qualquer parte de um sistema, incluindo um computador, uma rede, um dispositivo de armazenamento ou um servidor web. Aqui estão algumas maneiras pelas quais o failover pode ajudar as organizações a criar uma infraestrutura resiliente.
- Failover de servidor de aplicativos protege vários servidores que executam aplicativos. Esses servidores de failover devem idealmente ser executados em hosts separados e todos devem ter nomes de domínio distintos.
- Failover de sistema de nomes de domínio (DNS) garante que serviços de rede ou sites permaneçam disponíveis durante uma interrupção. Ele gera um registro DNS para um sistema que inclui dois ou mais endereços IP ou conexões de failover. Isso permite que os usuários redirecionem o tráfego de um sistema falho para um site redundante e ativo.
- Failover de protocolo de configuração dinâmica de host (DHCP) implanta dois ou mais servidores DHCP para lidar com o mesmo pool de endereços. Isso permite que cada servidor DHCP faça backup do outro em caso de perda de rede. Eles compartilham a responsabilidade de atribuição de lease para esse grupo o tempo todo.
- Failover de servidor SQL remove qualquer ponto único de falha potencial empregando armazenamento de dados compartilhado e várias conexões de rede por meio de um armazenamento conectado à rede (NAS).
Failover com elegância
Embora a integração do failover possa ser cara, considere o enorme custo do tempo de inatividade. Pense no failover como uma apólice de seguro essencial de segurança e proteção.
O failover deve ser um componente chave da sua estratégia de recuperação de desastres. Sua prioridade deve ser limitar as transferências de dados para evitar gargalos enquanto mantém uma sincronização de alta qualidade entre os sistemas primário e de backup a partir de uma abordagem de engenharia de sistemas.
Descubra como criar um plano de recuperação de desastres robusto que proteja suas operações e proteja seus ativos valiosos.
Este artigo foi publicado originalmente em 2022. Foi atualizado com novas informações.

Keerthi Rangan
Keerthi Rangan is a Senior SEO Specialist with a sharp focus on the IT management software market. Formerly a Content Marketing Specialist at G2, Keerthi crafts content that not only simplifies complex IT concepts but also guides organizations toward transformative software solutions. With a background in Python development, she brings a unique blend of technical expertise and strategic insight to her work. Her interests span network automation, blockchain, infrastructure as code (IaC), SaaS, and beyond—always exploring how technology reshapes businesses and how people work. Keerthi’s approach is thoughtful and driven by a quiet curiosity, always seeking the deeper connections between technology, strategy, and growth.

