

Aayushi Sanghavi
Aayushi Sanghavi is a Campaign Coordinator at G2 for the Content and SEO teams at G2 and is exploring her interests in project management and process optimization. Previously, she has written for the Customer Service and Tech Verticals space. In her free time, she volunteers at animal shelters, dances, or attempts to learn a new language.
Ho usato Grammarly per aiutarmi a scrivere questo pezzo. Grammarly ha utilizzato l'elaborazione del linguaggio naturale per aiutarmi a rendere questo articolo eccezionale.
È così che sono diventati diffusi i casi d'uso dell'elaborazione del linguaggio naturale. Le tecnologie NLP hanno percorso una lunga strada, dalla scrittura di un articolo e dalla trascrizione delle chiamate di vendita al recupero di grandi quantità di informazioni rilevanti e alla vera comprensione di ciò che l'utente intende.
L'evoluzione della linguistica computazionale ha reso facile per le macchine comprendere le lingue umane, riducendo i divari tra le interazioni uomo-computer. Il software di elaborazione del linguaggio naturale migliora l'esperienza del cliente, automatizza l'inserimento dei dati, migliora le raccomandazioni di ricerca e rafforza gli sforzi di sicurezza in tutti i settori.
Cos'è l'elaborazione del linguaggio naturale?
L'elaborazione del linguaggio naturale (NLP) è una tecnologia di intelligenza artificiale (AI) che consente ai programmi informatici di interpretare il testo e le parole pronunciate per comprendere meglio il linguaggio umano.
L'NLP utilizza algoritmi di apprendimento automatico (ML), modellazione basata su regole e modelli di apprendimento profondo per aiutare i computer a elaborare i dati linguistici per analizzare l'intento e il sentimento dei messaggi.
Se hai usato la navigazione GPS per orientarti in una nuova città o hai urlato a un assistente vocale di accendere le luci – congratulazioni, hai incontrato un programma NLP!
Grazie all'elaborazione del linguaggio naturale, le applicazioni informatiche possono rispondere ai comandi vocali e riassumere grandi quantità di testo in tempo reale per interagire con gli esseri umani in modo significativo ed espressivo.
Come funziona l'NLP?
L'NLP è tutto intorno a noi, anche se non ce ne accorgiamo necessariamente. Assistenti virtuali, chatbot per il servizio clienti, modelli transformer, testo predittivo – tutto è reso possibile con la tecnologia NLP che comprende e filtra le nostre richieste. I programmi fanno da ponte tra computer e umani per organizzare le operazioni aziendali, rivitalizzando la produttività attraverso interazioni finemente sintonizzate.
Le tecniche di addestramento NLP si basano sull'apprendimento profondo e sugli algoritmi per interpretare e dare un senso al linguaggio umano.
I modelli di apprendimento profondo elaborano dati non strutturati o dati qualitativi che non possono essere analizzati utilizzando strumenti convenzionali come voce e testo. Li trasformano in dati strutturati che possono essere inseriti nei database che conosciamo per fornire informazioni utilizzabili.
L'elaborazione del linguaggio naturale estrae informazioni contestuali scomponendo il linguaggio in singole parole e identificando le loro relazioni. Facendo ciò, consente un processo di indicizzazione e segmentazione più accurato – uno basato su sentimento e intento.
Prima che un modello possa elaborare qualsiasi dato testuale, deve preelaborarlo in un formato che la macchina possa comprendere. Sono disponibili diverse tecniche di elaborazione dei dati.
Tokenizzazione
La tokenizzazione, il primo passo per convertire i dati grezzi in un formato comprensibile dalla macchina, consiste nel dividere il testo in unità più piccole note come token. La macchina comprende facilmente il testo una volta che è stato scomposto in parole o frasi. Poiché le macchine comprendono solo dati numerici, il testo tokenizzato è rappresentato come token numerici per i programmi.
Esempio:
Considera il seguente testo inserito da un utente:
"C'è una banca oltre il ponte."
Testo compreso dalla macchina dopo la tokenizzazione:
["C'è", "una", "banca", "oltre", "il", "ponte", "."]
Rimozione delle parole di stop
Il prossimo passo di preelaborazione nell'NLP rimuove le parole comuni con poco o nessun significato specifico nel testo. Queste parole, note come parole di stop, includono articoli (il/un/una), "è," "e," "sono," e così via. Questo passaggio elimina le parole non utili e fornisce una comprensione significativa, efficiente e accurata del testo.
Esempio:
Considera lo stesso testo di esempio inserito da un utente:
"C'è una banca oltre il ponte."
Testo compreso dalla macchina dopo la rimozione delle parole di stop:
["C'è", "banca", "oltre", "ponte", "."]
Stemming e lemmatizzazione
Lo stemming e la lemmatizzazione si riferiscono alle tecniche che le applicazioni NLP utilizzano per semplificare le parole e l'analisi del testo riducendole alla loro forma base.
Lo stemming è un approccio basato su regole che rimuove prefissi e suffissi per riportare le parole alle loro forme fondamentali o radici. Il processo non richiede molta potenza computazionale e le parole base risultanti potrebbero non avere sempre senso, ma aiutano il programma a facilitare l'analisi del testo.
Ad esempio, la parola "condivisione" risulterà in una radice "condiv".
Una limitazione dello stemming è che diverse parole semanticamente non correlate possono azionista condividere una radice.
La lemmatizzazione è un approccio basato su dizionario per convertire le parole nella loro forma morfologica, ovvero lemma. Il processo richiede un elevato sforzo computazionale a causa della necessità di consultare il dizionario. Il lemma risultante sarà sempre una parola valida contestualmente e come parte del discorso.
Ad esempio, la parola "condivisione" risulterà in un lemma "condividere".
Estrazione delle caratteristiche
Poiché i nostri amici macchine comprendono solo numeri e algoritmi, il testo grezzo che inseriamo deve essere convertito in rappresentazioni numeriche. L'estrazione delle caratteristiche aiuta a mantenere le informazioni rilevanti e contemporaneamente riduce la complessità dei dati per catturare solo i modelli e le relazioni più necessari.
Diverse tecniche possono essere utilizzate per ottenere questo risultato in base al compito NLP.
- Bag-of-Words considera solo la presenza o l'assenza di parole creando uno spazio vettoriale del testo. La rappresentazione del testo viene effettuata attraverso la frequenza delle parole piuttosto che l'ordine delle parole.
- Term Frequency-Inverse Document Frequency (TF-IDF) tiene conto dell'importanza di ogni parola nel dataset. Le parole che si verificano frequentemente ricevono più valore.
- Word embeddings catturano le relazioni semantiche tra le parole, creando una rappresentazione vettoriale densa. Esempi includono Word2Vec e GloVe.
- Topic modeling estrae argomenti simili dal testo per rappresentare documenti distribuiti per argomento. Un esempio di questa tecnica include Latent Dirichlet Allocation (LDA).
Gli algoritmi NLP sono generalmente basati su regole o addestrati su modelli di apprendimento automatico. L'addestramento continuo e i cicli di feedback possono creare grandi riserve di conoscenza, prevedere meglio l'intenzione umana e ridurre al minimo le risposte false.
Quali sono i compiti comuni dell'NLP?
L'elaborazione del linguaggio naturale utilizza tecniche o compiti di intelligenza artificiale per elaborare, comprendere e generare il linguaggio naturale (umano). Migliorano l'interazione uomo-computer e facilitano una comunicazione efficace attraverso applicazioni basate sul linguaggio.
Tagging delle parti del discorso
Chi non ha dimenticato le lezioni di grammatica della sesta elementare? L'NLP.
Il tagging delle parti del discorso (POS), o tagging grammaticale, consente alle applicazioni NLP di identificare le singole parole in una frase per determinare il loro significato nel contesto di quella frase. Ciò consente ai computer di distinguere tra nomi, verbi, aggettivi e avverbi e di comprendere le loro relazioni.
Come mostrato nell'esempio seguente, il tagging POS significa che i programmi NLP hanno il potere di contestualizzare il verbo "piace" nella frase "Mi piace la spiaggia" e identificare "piace" come avverbio nella frase "Sono come Mark."
.png)
Disambiguazione del senso delle parole
Il concetto non è così complicato come sembra; significa solo che i programmi NLP possono identificare il significato inteso della stessa parola quando viene utilizzata in contesti diversi.
Attraverso l'analisi semantica (cioè, estrarre significato dal testo e fare il parsing) i computer possono interpretare le frasi e le relazioni tra le singole parole per avere più senso in un contesto particolare.

La parola "bark" nell'esempio sopra ha due significati diversi.
Le applicazioni NLP distinguono tra il latrato di un cane e la corteccia di un albero attraverso la disambiguazione del senso delle parole.
Riconoscimento delle entità nominate
Le applicazioni di elaborazione del linguaggio naturale possono identificare parole per categorie specifiche, come i nomi delle persone, i luoghi e i nomi delle organizzazioni. Attraverso il riconoscimento delle entità nominate (NER), il software NLP estrae entità e comprende la loro relazione con il resto del testo.
.png)
Nell'esempio sopra, il compito NLP di riconoscimento delle entità nominate identifica "Microsoft" e "Bill Gates" rispettivamente come un'organizzazione e una persona.
Applicazioni del riconoscimento delle entità nominate
- Estrazione di fatti dalle fake news: NER può identificare entità importanti che possono aiutare a verificare le fonti delle notizie.
- Recupero delle informazioni: Per assistere nella creazione di sistemi di recupero in cui gli utenti possono cercare informazioni specifiche per accedere a documenti rilevanti.
Risoluzione della co-referenza
Compiti NLP di alto livello come la risposta alle domande e il recupero delle informazioni (di cui parleremo più avanti) richiedono ai computer di identificare tutte le parole che si riferiscono alla stessa entità. Questo processo, noto come risoluzione della co-referenza, aiuta i programmi a determinare persone/oggetti collegati a pronomi specifici.
La risoluzione della co-referenza è anche il motivo per cui i computer sanno quando un'espressione idiomatica fa parte di un testo.
Riconoscimento vocale
I programmi NLP beneficiano della comprensione del processo di conversione del linguaggio parlato in – più o meno – linguaggio informatico. Il riconoscimento vocale è essenziale per facilitare interazioni uomo-computer naturali e intuitive.
Vediamo un paio di esempi di riconoscimento vocale come parte dell'elaborazione del linguaggio naturale.
- Assistenti vocali: I nostri migliori amici virtuali Siri, Alexa e Google Assistant rispondono ai nostri comandi utilizzando tecniche di riconoscimento vocale per fornire risposte pertinenti.
- Trascrizione e dettatura: Le trascrizioni delle registrazioni audio e le conversioni del linguaggio parlato in testo sono fondamentali per i settori della creazione di contenuti, legale e dell'istruzione.
- Preelaborazione dei dati: Il riconoscimento vocale è importante nella trasformazione dei dati grezzi in una forma più comprensibile. La preelaborazione può essere effettuata per dati audio e dati testuali.
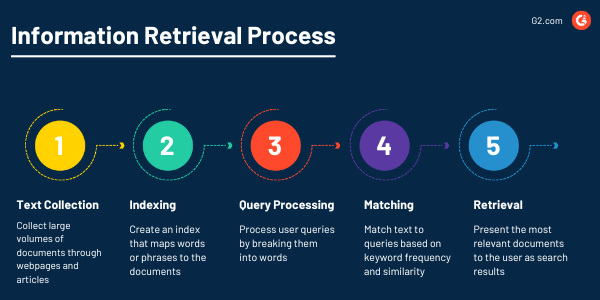
Recupero delle informazioni
I programmi NLP troveranno sempre quel documento importante proprio quando ne hai bisogno grazie alla loro potente capacità di recuperare informazioni da grandi set di dati. L'obiettivo del recupero delle informazioni come compito NLP è offrire agli utenti informazioni accurate e utili dalla raccolta di testi attraverso l'estrazione di testo.
Analisi del sentimento
Ti sei mai chiesto come i bot del servizio clienti riescano quasi sempre a capire come ti senti? È tutto grazie all'analisi del sentimento – un processo automatizzato che riconosce il tono emotivo e i sentimenti espressi in vari casi d'uso.
I modelli di apprendimento automatico possono essere addestrati sull'analisi del sentimento utilizzando la classificazione dell'etichettatura del sentimento (positivo, negativo, neutro), il post-processing e la valutazione del sentimento.
L'analisi del sentimento è un ottimo modo per le aziende di ottenere informazioni sui clienti attraverso le recensioni dei prodotti e monitorare i loro marchi in base ai sentimenti sui social media.
Traduzione automatica
Il compito NLP di tradurre automaticamente testo o contenuti parlati da una lingua all'altra è ampiamente utilizzato nel software di traduzione automatica. La traduzione automatica mira a fornire traduzioni accurate e coerenti mantenendo la precisione contestuale.
I modelli di traduzione utilizzano anche il riconoscimento vocale. Sono costruiti per migliorare la comunicazione globale e abbattere le barriere linguistiche nel business, nell'istruzione, nella sanità e nelle relazioni internazionali.
Rilevamento dello spam
Hai mai pensato che un'email fosse legittima e hai risposto, ma era solo spam? Anche io.
Il compito NLP di riconoscere automaticamente i messaggi irrilevanti da un grande gruppo di messaggi, come email e post sui social media, e rimuoverli si chiama rilevamento dello spam.
Il processo aiuta a distinguere i messaggi fraudolenti da quelli genuini e garantisce la sicurezza degli utenti sulle piattaforme di comunicazione.
Librerie e framework NLP
I linguaggi di programmazione sono per l'NLP ciò che una falena è per una fiamma. Sebbene molti linguaggi e librerie supportino i compiti di elaborazione del linguaggio naturale, ne esistono alcuni popolari.
Python
Il linguaggio di programmazione più utilizzato per i compiti NLP, le librerie e i framework di apprendimento profondo è scritto per Python.
- Natural Language Toolkit (NLTK): Una delle prime librerie NLP mai scritte in Python, il NLTK è noto per le sue interfacce facili da usare e le librerie di elaborazione del testo per il tagging, lo stemming e l'analisi semantica.
- spaCy: Una libreria NLP open-source, spaCy fornisce vettori pre-addestrati. Puoi usarla per NER, tagging delle parti del discorso, classificazione e analisi morfologica.
- Librerie di apprendimento profondo: PyTorch e TensorFlow sono strumenti comuni per sviluppare modelli di dati NLP.
R
Il linguaggio di programmazione è ampiamente utilizzato dagli statistici per i modelli NLP di calcolo statistico e grafica scritti in R. Questo include Word2Vec e TidyText.
Applicazioni aziendali dell'NLP
Le tecniche di elaborazione del linguaggio naturale sono utilizzate in molti casi aziendali per migliorare l'efficienza operativa, la produttività e i processi critici per la missione.
Chatbot e assistenti virtuali
L'ascesa dell'IA conversazionale ha trasformato il modo in cui i chatbot e gli assistenti virtuali interagiscono con gli esseri umani, specialmente nel servizio clienti.
L'NLP alimenta le capacità simili a quelle umane dei chatbot per scalare il supporto clienti automatizzato mantenendo operazioni economiche. I bot di chat e voce possono offrire raccomandazioni personalizzate e funzionalità di chat localizzate per aiutare nel processo di acquisto, rispondere a domande frequenti e assistere gli utenti in tempo reale.
Le funzionalità di riconoscimento vocale sono anche utili nel monitoraggio delle analisi dei call center per trascrivere i dati vocali in testo.
Monitoraggio dei social media
L'analisi del sentimento sulle piattaforme social aiuta a valutare il feedback e le recensioni dei clienti per comprendere la soddisfazione dei consumatori attraverso preziose informazioni sui dati.
Gli strumenti di monitoraggio dei social media sono alimentati dall'elaborazione del linguaggio naturale per concedere funzionalità di ascolto, tracciamento e raccolta di contenuti. Queste applicazioni vedono un ampio utilizzo nella realizzazione di ricerche di mercato, nel tracciamento dell'analisi delle tendenze e nell'identificazione di modelli su diverse reti sociali.
Estrazione di informazioni e rilevamento delle frodi
I settori sanitario e legale utilizzano la tecnologia NLP per estrarre dati di alta qualità e rilevanti da grandi volumi di dati di trial clinici, letteratura scientifica e contratti legali.
Come con il rilevamento dello spam, la tecnologia NLP può rilevare attività fraudolente percependo modelli nei dati. Questo è particolarmente utile nel settore finanziario per monitorare le transazioni.
NLP vs. NLU vs. NLG
Sebbene ci sia solo un termine differenziante nell'elaborazione del linguaggio naturale (processing), nella comprensione del linguaggio naturale (understanding) e nella generazione del linguaggio naturale (generation), esistono alcune differenze tra i tre concetti.
Elaborazione del linguaggio naturale
L'NLP è un ramo dell'IA che aiuta i computer a comprendere, interpretare e generare il linguaggio umano. I compiti comuni dell'NLP includono il riconoscimento vocale, l'analisi del sentimento e il riconoscimento delle entità nominate.
L'NLP è ampiamente utilizzato nell'assistenza vocale per riassumere grandi quantità di testo e nei servizi di traduzione.
Comprensione del linguaggio naturale (NLU)
Un sottoinsieme dell'NLP, il software NLU si concentra sulla comprensione del testo per estrarre significato dai dati. Combina logica software, linguistica, ML e AI per dare un senso al linguaggio naturale.
I compiti comuni dell'NLU includono:
- Riconoscimento dell'intento. I modelli NLU sono utilizzati per identificare l'intento di diverse entità per scopi di classificazione e categorizzazione del testo. Ad esempio, creare diverse sezioni per le notizie, l'intrattenimento e gli affari di un'azienda.
- Analisi dei contenuti. Comprendendo le connessioni tra i pezzi di contenuto, l'NLU può condurre un'analisi approfondita delle entità per evidenziare sentimenti e relazioni complesse.
- Ricerca cognitiva. L'NLU analizza ed estrae dati non strutturati, consentendogli di estrarre informazioni rilevanti da set di dati diversi. Questo migliora i risultati delle query di ricerca e fornisce informazioni rilevanti sull'intento utilizzando l'analisi predittiva.
I 5 migliori software NLU
1. Amazon Comprehend2. IBM Watson Natural Language Classifier
3. Azure Translator Speech API
4. Azure Translator Text API
5. Apace cTAKES
*Questi dati sono stati estratti dal G2 Summer Grid Report il 19 luglio 2023, basato sulla nostra metodologia di punteggio.
Generazione del linguaggio naturale (NLG)
Dall'altra parte dell'NLU c'è la tecnologia NLG, il ramo dell'IA che genera testo scritto o parlato da un set di dati. Permette ai computer di fornire feedback agli esseri umani in un linguaggio che è comprensibile per noi, non per le macchine.
I compiti comuni dell'NLG includono:
- Conversione dei dati. I modelli NLG convertono i dati strutturati in testi leggibili dagli esseri umani.
- Interazioni con i clienti. Queste forniscono risposte che suonano come linguaggio naturale, corrispondenza dei sentimenti e comunicazioni personalizzate con i clienti.
I 5 migliori software NLG
1. Anyword2. Quill
3. AX Semantics
4. Wordsmith
5. Phrazor by vPhrase
*Questi dati sono stati estratti dal G2 Summer Grid Report il 19 luglio 2023, basato sulla nostra metodologia di punteggio.

Svelare il mistero del linguaggio naturale
Sebbene l'NLP possa sembrare un mago, non lo è. Combina varie potenti capacità computazionali rendendolo utile in molti compiti che rendono i compiti umani più efficienti.
Che sia attraverso i saluti dei chatbot o la sintesi del testo, il mondo dell'NLP continua a sforzarsi di fornire preziose informazioni da grandi set di dati di linguaggio umano. Le tecnologie NLP stanno rendendo le nostre vite personali e professionali più coinvolgenti, personalizzate e interattive mentre navighiamo nel nostro nuovo mondo centrato sui dati.
Una delle funzionalità NLP più popolari è il suo utilizzo negli assistenti vocali. Scopri di più su come funziona il riconoscimento vocale e le funzionalità che offre che ti permettono di urlare comandi ad esso.
Questo articolo è stato originariamente pubblicato nel 2019. È stato aggiornato secondo le nuove linee guida editoriali, con nuove risorse ed esempi recenti.