

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.
Che cos'è l'analisi di regressione?
L'analisi di regressione stima le relazioni o i collegamenti tra una variabile dipendente e una o più variabili indipendenti. Valuta la forza della connessione e il potenziale per relazioni future.
Comprende varie forme, tra cui la regressione lineare, la regressione lineare multipla e la regressione non lineare. I modelli più comuni sono la regressione lineare semplice e la regressione lineare multipla. La regressione non lineare, invece, viene applicata quando si trattano set di dati complessi che mostrano un'associazione non lineare tra le variabili dipendenti e indipendenti.
Molti professionisti preferiscono utilizzare l'analisi di regressione per prevedere risultati aziendali accurati quando una proposta aziendale si basa su più fattori. La maggior parte dei dirigenti si rivolge a software di analisi statistica per eseguire queste valutazioni.


Tipi di analisi di regressione
La tecnica di analisi di regressione e la selezione dell'approccio dipendono da diversi fattori, come il tipo di variabile dipendente e il numero di variabili indipendenti. Di seguito sono riportati alcuni tipi comuni di analisi di regressione.
- Analisi di regressione lineare semplice viene impiegata per prevedere il valore di una variabile dipendente basandosi sul valore noto di una variabile indipendente. Il metodo adatta una linea retta, permettendo di definire la relazione tra le due variabili stimando i coefficienti nell'equazione lineare.
- Analisi di regressione multipla descrive una variabile di risposta con l'aiuto di più variabili predittive quando le connessioni tra i dati sono più complesse. Questo approccio funziona meglio quando forti correlazioni tra le variabili indipendenti possono influenzare la variabile dipendente.
- Regressione dei minimi quadrati ordinari è un metodo che stima i parametri sconosciuti in un modello. Calcola il coefficiente di un'equazione di regressione lineare riducendo la somma degli errori quadrati tra i valori effettivi e quelli previsti rappresentati da una linea retta.
- Regressione polinomiale, una forma di regressione lineare multipla, entra in gioco quando la relazione tra i punti dati è non lineare. Determina la relazione curvilinea tra variabili indipendenti e dipendenti.
- Regressione logistica modella la probabilità della variabile dipendente basandosi su variabili indipendenti. Viene utilizzata quando la variabile dipendente può assumere uno di un insieme limitato di valori binari (0 e 1), rendendola adatta per l'analisi di dati binari.
- Regressione bayesiana viene applicata quando i set di dati sono limitati o mal distribuiti. Quando i dati non sono disponibili, utilizza una distribuzione di probabilità per derivare il risultato invece di stime puntuali.
- Regressione quantile stima percentili o quantili specifici di una variabile di risposta piuttosto che concentrarsi esclusivamente sulla media condizionale, come nella regressione lineare. Resiste all'influenza degli outlier e non si basa su assunzioni.
- Regressione ridge è una tecnica di regolarizzazione che mitiga la multicollinearità tra le variabili indipendenti o quando il numero di variabili indipendenti supera il numero di osservazioni. La multicollinearità è un concetto statistico in cui diverse variabili indipendenti in un modello sono correlate.
Vantaggi dell'analisi di regressione
L'utilizzo dell'analisi di regressione per valutare l'impatto delle variabili in cambiamento offre diversi vantaggi per le aziende.
- Prendere decisioni basate sui dati. Quando si pianifica per il futuro, le aziende si affidano all'analisi di regressione per determinare quali variabili influenzano significativamente i risultati.
- Riconoscere le opportunità di miglioramento. Le aziende possono osservare come l'aumento del numero di persone su un progetto influisce sulla crescita dei ricavi. L'analisi di regressione rivela le relazioni tra le variabili, consentendo alle aziende di identificare opportunità di miglioramento.
- Ottimizzare i processi aziendali. Le aziende utilizzano l'analisi di regressione per migliorare l'efficienza operativa. Ad esempio, condurre sondaggi sui consumatori prima di lanciare una nuova linea di prodotti le aiuta a comprendere come vari fattori influenzano la produzione.
Come condurre un'analisi di regressione
Condurre una regressione lineare implica diversi passaggi chiave per calcolare la relazione tra una variabile dipendente e una o più variabili indipendenti.
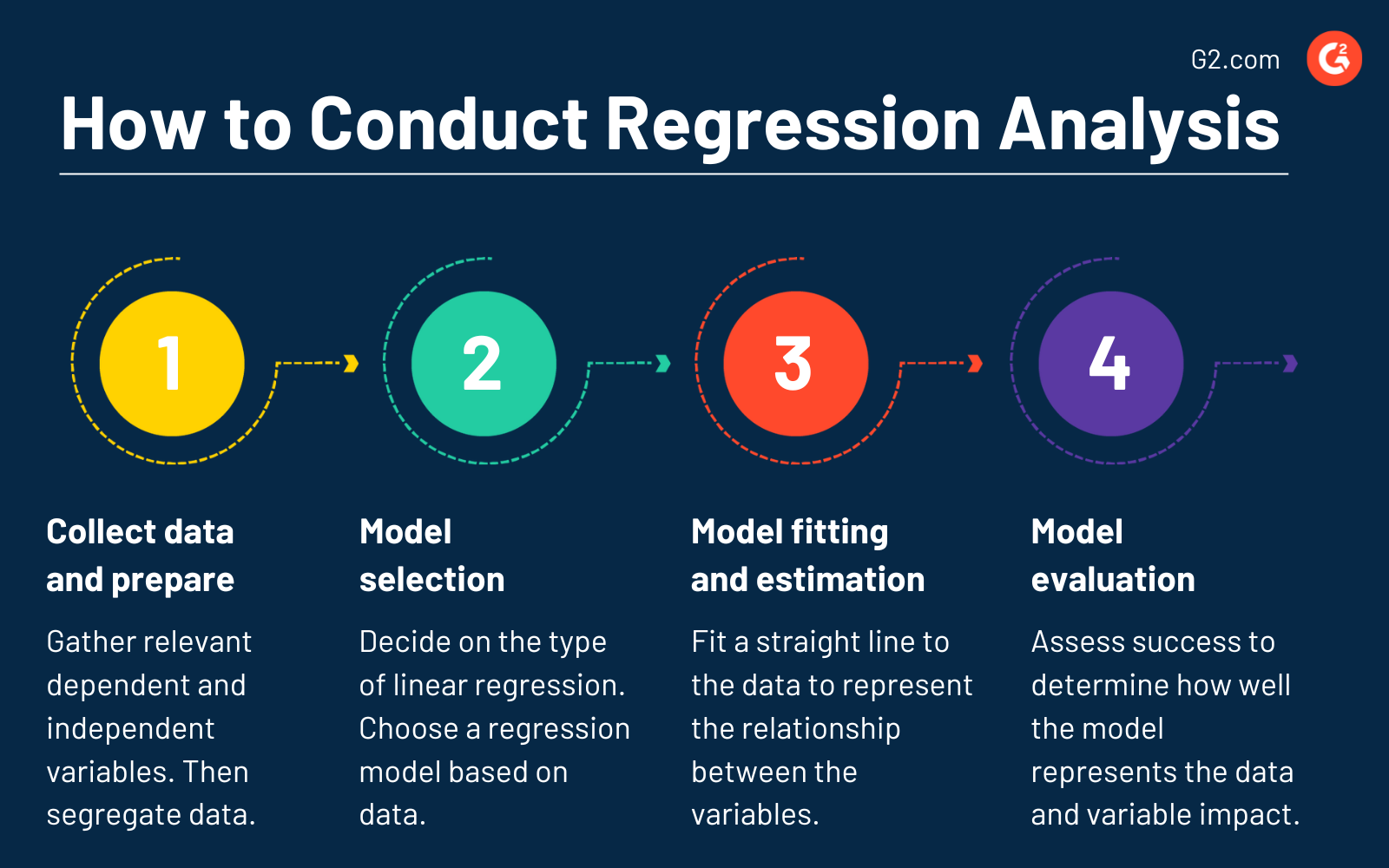
Ecco i punti principali da seguire:
- Raccolta e preparazione dei dati. Raccogliere variabili dipendenti e indipendenti pertinenti. Assicurarsi che non ci siano valori mancanti e controllare la presenza di outlier che potrebbero influenzare i risultati dell'analisi. Separare i dati in set di addestramento e di test per valutare le prestazioni del modello.
- Selezione del modello. Decidere il tipo di regressione lineare. Scegliere il modello di regressione appropriato basandosi sulle caratteristiche dei dati.
- Adattamento del modello e stima dei coefficienti. Nella regressione lineare semplice, adattare una linea retta ai dati che rappresenta al meglio la relazione tra le variabili dipendenti e indipendenti. Al contrario, stimare i coefficienti dell'equazione lineare per determinare l'influenza delle variabili indipendenti sulle variabili dipendenti per la regressione lineare multipla.
- Valutazione del modello. Valutare il successo per determinare quanto bene il modello rappresenta i dati. Analizzare la significatività dei coefficienti di regressione per comprendere l'impatto di ciascuna variabile indipendente sulla variabile dipendente.
Best practice per l'analisi di regressione
Di seguito sono riportate alcune best practice essenziali per garantire che le previsioni e i risultati siano vicini ai valori effettivi.
- Mantenere aggiornati i test suite. Assicurarsi di verificare la funzionalità delle vecchie funzionalità con i nuovi aggiornamenti.
- Utilizzare il framework di test di regressione. Impiegare framework di test di regressione per semplificare gli sforzi di manutenzione.
- Adattare i design dei test. Questo dovrebbe essere determinato dalle esigenze degli sviluppatori e dei tester.
- Implementare test di regressione automatizzati. Risparmiare risorse e accelerare la consegna attraverso test di regressione automatizzati.
- Identificare i bug prima del deployment. I test di regressione automatizzati aiutano a individuare i bug prima della scadenza del deployment.
- Scalare con infrastruttura di test basata su cloud. Man mano che le applicazioni diventano complesse, confermare che l'infrastruttura di test possa scalare per accogliere numeri in espansione.
Analisi di regressione vs. analisi di correlazione
L'analisi di regressione è una tecnica di modellazione predittiva utilizzata per esaminare la relazione tra una variabile target e variabili indipendenti in un set di dati. Vengono impiegate varie tecniche di analisi di regressione basate sul fatto che la relazione tra la variabile target e le variabili indipendenti sia lineare o non lineare e quando la variabile target comprende valori continui.
L'analisi di correlazione misura la relazione tra due variabili invece di valutare come due variabili numeriche si influenzano a vicenda.
Scopri di più sulla differenza tra regressione e correlazione e comprendi quando utilizzare quale.














