A tecnologia está avançando em um ritmo acelerado e, embora às vezes possa parecer avassaladora, está tornando nossas tarefas diárias mais fáceis.
Desde pedir nosso café da manhã com um comando de voz até encontrar a rota mais rápida para o escritório, essas conveniências se tornaram uma segunda natureza. Mas e se seus dispositivos pudessem entender e interagir com o mundo ao nosso redor da mesma forma que um humano poderia?
Com o poder da inteligência artificial (IA) e da tecnologia de visão computacional, agora podemos.
O que é "you only look once" (YOLO)?
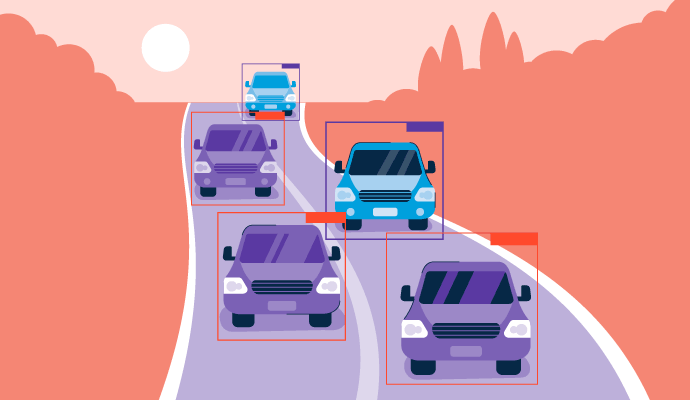
"You only look once", ou YOLO, é um algoritmo de detecção de objetos em tempo real desenvolvido pela primeira vez em 2015. Ele prevê a probabilidade de que um objeto esteja presente em uma imagem ou vídeo. É um algoritmo específico que aprimora o campo atual de detecção de objetos na tecnologia de visão computacional, onde objetos em imagens são localizados e identificados.
O YOLO só precisa revisar o visual uma vez para fazer essas previsões, daí seu nome, e também pode ser referido como detecção de objetos de tiro único (SSD). É uma parte importante do processo de detecção de objetos que muitos softwares de reconhecimento de imagem usam para entender o que a mídia visual está retratando.
Usando redes neurais de ponta a ponta, este algoritmo pode prever simultaneamente a localização (caixas delimitadoras) e a identidade (classificação) de objetos em uma imagem. Isso foi um salto em relação aos algoritmos tradicionais de detecção de objetos, que reutilizavam classificadores existentes para prever essas informações.
Como funciona o You Only Look Once
O YOLO se baseia em uma única rede neural convolucional (CNN), um componente chave do aprendizado profundo e um tipo de rede de IA que filtra entradas de modelo para procurar padrões reconhecíveis. As camadas nessas redes são formatadas para detectar os padrões mais simples primeiro, antes de passar para os mais complexos.
Embora as CNNs sejam usadas para mais do que processamento de imagens, elas são uma parte fundamental da arquitetura YOLO. Quando uma imagem é inserida em um modelo baseado em YOLO, ela passa por várias etapas para detectar objetos dentro desse visual. Aqui está um resumo:
- Imagem de entrada: A imagem inteira, seja uma foto estática, gráfico ou formato de vídeo, é passada pelo modelo. As características da imagem são extraídas e passadas por camadas conectadas para prever as classificações e coordenadas das caixas delimitadoras.
- Divisão em grade: A imagem de entrada é então dividida em caixas em uma formação de grade. Cada pequeno quadrado ou célula da grade é responsável por detectar objetos dentro de sua seção, além de fornecer um valor de probabilidade ou confiança para qualquer objeto detectado.
- Detecção de objetos: Se uma grade for prevista para conter um objeto, ela será destacada como células significativas. O modelo então determina o tipo de objeto e sua localização dentro da grade em uma única passagem.
- Pontuação da caixa delimitadora: O modelo desenha caixas ao redor dos objetos detectados, conhecidas como caixas delimitadoras. Cada célula da grade pode gerar várias caixas delimitadoras se houver mais de um objeto nessa célula. As caixas delimitadoras também podem sobrepor células para abranger completamente cada objeto na imagem inteira. Uma pontuação de confiança é atribuída a cada caixa delimitadora que representa a probabilidade de a previsão estar correta.
- Saída: Após a avaliação dos quadrados da grade, a saída final listará todos os objetos dentro da imagem, juntamente com cada caixa delimitadora e seu rótulo. Como parte do pós-processamento, ocorrerá a supressão não máxima (NMS) para remover caixas sobrepostas, garantindo que cada objeto seja representado por apenas uma caixa com a maior pontuação de confiança. Esta etapa melhora a precisão da detecção de objetos e torna todo o processo mais eficiente ao filtrar ruídos adicionais para criar uma saída mais limpa.
Quer aprender mais sobre Software de Reconhecimento de Imagem? Explore os produtos de Reconhecimento de Imagem.
Tipos de YOLO na detecção de objetos
Desde seu desenvolvimento, o YOLO passou por várias iterações que incorporaram tecnologia atualizada e criaram um fluxo de trabalho mais rápido e eficiente. Aqui está um breve resumo do YOLO v1-v6 e um olhar sobre onde estamos hoje:
- YOLOv1: O algoritmo original estava focado principalmente na detecção de objetos como um problema de regressão, em vez das abordagens tradicionais de classificação, o que foi inovador na época. Esta base ainda é usada em modelos YOLO hoje.
- YOLOv2: Também conhecido como YOLO 9000, esta versão construiu sobre os conceitos originais do YOLO e abordou algumas das limitações do primeiro modelo. Caixas âncora foram introduzidas como caixas pré-determinadas dentro da grade, com proporções e escalas únicas. Isso tornou a previsão de caixas delimitadoras mais fácil e melhor ajustada aos objetos reais na imagem. A versão também incluiu atualizações para lidar com imagens de alta resolução sem desacelerar os tempos de processamento.
- YOLOv3: Esta versão introduziu uma técnica conhecida como "rede de pirâmide de características" (FPN), que foi usada para detectar objetos de tamanhos diferentes dentro da imagem. A velocidade de processamento também foi aumentada na terceira versão do YOLO através do uso do Darknet-53.
- YOLOv4: Com uma versão atualizada do Darknet, CSPDarnet, a quarta versão do YOLO foi significativamente mais rápida e precisa do que as iterações anteriores. A precisão melhorou em cerca de 0,5% em média graças à introdução de uma técnica conhecida como "conexão parcial de estado cruzado" ou CSP, onde vários modelos foram introduzidos ao mesmo tempo para combinar suas habilidades de previsão.
- YOLOv5: Introduzido em 2020, a quinta versão do YOLO introduziu uma arquitetura de rede neural atualizada chamada EfficientDet. EfficientDet foi uma série de modelos de classificação de imagens projetados para melhorar a precisão computacional e o uso de memória, enquanto ainda alcançava os mais altos níveis de precisão de saída. Caixas âncora não eram mais necessárias com a versão 5, com uma única camada convolucional capaz de prever caixas delimitadoras de objetos diretamente, independentemente de sua forma ou tamanho.
- YOLOv6: A introdução de uma nova rede neural mais leve significou que a versão 6 do YOLO funcionava de forma mais eficiente e com menos recursos necessários. Aumentação de dados também foi introduzida durante o treinamento, o que permite que o modelo ainda reconheça objetos quando invertidos, rotacionados ou escalados na imagem de entrada.
As atualizações mais recentes do YOLO, versões 7 a 9, continuaram a ver melhorias em velocidade e precisão à medida que o algoritmo é adaptado com base nos avanços atuais do aprendizado profundo. A capacidade de aprendizado do algoritmo aumentou significativamente com esses modelos mais novos, permitindo que a detecção de objetos ainda seja possível com dados de imagem borrados ou incompletos.
Indústrias que usam You Only Look Once
Existem inúmeras maneiras de implementar o YOLO na vida cotidiana, mas algumas indústrias se beneficiam mais dessa tecnologia do que outras.
Segurança
Sistemas de vigilância se tornam mais complexos a cada ano, ajudando a nos manter seguros onde quer que estejamos. O YOLO é frequentemente usado para detectar indivíduos sendo monitorados por autoridades através de sistemas de câmeras de segurança e CCTV, além de monitorar crimes como furtos ou agressões ocorrendo em tempo real.
Saúde
Como outras formas de detecção de objetos e reconhecimento de imagem, o YOLO pode ser usado em cuidados médicos em tempo real e tratamento de imagens. Vários estudos encontraram uso generalizado do YOLO em toda esta indústria, incluindo procedimentos cirúrgicos onde a detecção de órgãos é necessária devido à diversidade biológica de diferentes pacientes.
Tanto varreduras 2D quanto 3D podem localizar rapidamente e com precisão a colocação de órgãos, fornecendo insights sobre possíveis problemas que a imagem médica é usada para detectar.
Agricultura
O desenvolvimento da IA ajudou significativamente a indústria agrícola, permitindo que os agricultores monitorem suas colheitas o tempo todo sem a necessidade de supervisão manual. O YOLO e a robótica agrícola substituíram a colheita e a colheita manuais em muitos casos. Também é usado para identificar quando as colheitas estão no auge da maturação para colheita com base nas características de cor ou tamanho dos objetos (colheitas) nas imagens.
Veículos autônomos
Para carros autônomos, o YOLO ajuda a identificar sinais de trânsito, pedestres e outros perigos na estrada com velocidade e precisão, muito parecido com um motorista humano.
Benefícios do YOLO
Existem inúmeros benefícios em usar algoritmos como o YOLO em modelos de IA para detecção de objetos, particularmente em velocidade e precisão.
- Aplicações em tempo real: Para indústrias onde a gestão do tempo e a reatividade rápida são essenciais, como carros autônomos e segurança, o YOLO é uma das melhores opções automatizadas para detectar objetos em uma imagem ou vídeo.
- Altos níveis de precisão: Com cada nova versão do YOLO, o algoritmo se torna mais preciso na detecção de objetos com confiança nas caixas delimitadoras de saída. Tanto as classificações quanto as localizações dos objetos nas imagens são mais precisas a cada vez.
- Eficiência de tiro único: Em vez de esperar que as imagens sejam passadas por várias camadas de uma rede neural, o YOLO pode processar informações em uma única etapa para melhorar sua eficiência e velocidade geral.
- Capacidade de avaliar imagens de diferentes escalas: O YOLO agora é capaz de processar imagens com diferentes proporções e determinar objetos de tamanhos diferentes dentro de modelos que usam caixas âncora, bem como aqueles sem.
Principais ferramentas de reconhecimento de imagem usadas para You Only Look Once
O YOLO pode ser usado apenas para um papel específico no reconhecimento de imagem, detecção de objetos, mas essas ferramentas podem ser adicionadas a fluxos de trabalho para completar muitas outras tarefas. A detecção de objetos é apenas uma parte de como as imagens são processadas usando IA, com aspectos como restauração de imagem e reconstrução de cena também possíveis com este software.
Para ser incluído na categoria de reconhecimento de imagem, as plataformas devem:
- Fornecer um algoritmo de aprendizado profundo especificamente para reconhecimento de imagem
- Conectar-se a pools de dados de imagem para aprender uma solução ou função específica
- Consumir os dados de imagem como uma entrada e fornecer uma saída
- Fornecer capacidades de reconhecimento de imagem para outras aplicações, processos ou serviços
* Abaixo estão as cinco principais soluções de software de reconhecimento de imagem do Relatório de Verão de 2024 da G2. Algumas avaliações podem ser editadas para clareza.
1. Google Cloud Vision API
Google Cloud Vision API é capaz de detectar e classificar múltiplos objetos dentro de imagens usando um algoritmo pré-treinado que pode ser adaptado aos seus próprios modelos. Este software ajuda os desenvolvedores a usar o poder do aprendizado de máquina com precisão de previsão líder na indústria.
O que os usuários mais gostam:
"A coisa mais útil que experimentei sobre esta ferramenta Vision API do Google é sua integração de recursos de detecção em nossos projetos de aprendizado profundo e de máquina. Sua API está nos ajudando a detectar quaisquer objetos e rotulá-los com compreensão humana e formar um modelo de aprendizado de máquina."
- Avaliação do Google Cloud Vision API, Kunal D.
O que os usuários não gostam:
"Para imagens de baixa qualidade, às vezes dá a resposta errada, pois alguns alimentos têm a mesma cor. Não nos fornece a opção de personalizar ou treinar o modelo para nosso caso de uso específico. A parte de configuração é complexa."
- Avaliação do Google Cloud Vision API, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit é uma biblioteca de aprendizado de máquina de código aberto e multiplataforma. Atrai desenvolvedores e engenheiros de IA por suas opções de reconhecimento de gestos e imagens em tempo real que se integram aos seus próprios algoritmos e modelos.
O que os usuários mais gostam:
"Seu conjunto extenso de algoritmos e interface fácil de usar o tornam adequado tanto para iniciantes quanto para usuários avançados."
- Avaliação do Gesture Recognition Toolkit, Ram M.
O que os usuários não gostam:
"O Gesture Recognition Toolkit tem lag ocasional e um processo de implementação menos suave. Os tempos de resposta do suporte ao cliente poderiam ser mais rápidos."
- Avaliação do Gesture Recognition Toolkit, Civic V.
3. SuperAnnotate
SuperAnnotate é uma plataforma para construir, ajustar e gerenciar seus modelos de IA com os dados de treinamento de mais alta qualidade e líderes da indústria. Tecnologia avançada de anotação e ferramentas de garantia de qualidade permitem que você construa modelos de aprendizado de máquina bem-sucedidos e conjuntos de dados de alto nível.
O que os usuários mais gostam:
"Eu estava procurando uma ferramenta para anotar imagens biológicas. Depois de tentar muitas ferramentas, encontrei duas das melhores plataformas para mim. Uma delas é o Superannotate. Essas plataformas tinham o conjunto mais amplo de ferramentas de anotação, incluindo exatamente as que eu precisava. As ferramentas são convenientes de usar."
- Avaliação do SuperAnnotate, Artem M.
O que os usuários não gostam:
"Tivemos alguns problemas com fluxos de trabalho personalizados que a equipe implementou para projetos específicos em sua plataforma. Para certos fluxos de trabalho personalizados, notamos que a ferramenta de análise estava relatando incorretamente o tempo gasto para anotação."
- Avaliação do SuperAnnotate, Rohan K.
4. Syte
Syte é a primeira plataforma de descoberta de produtos com IA do mundo, ajudando tanto consumidores quanto varejistas a se conectarem com produtos. Pesquisa por câmera, personalização e ferramentas em loja, como reconhecimento de imagem, proporcionam uma experiência instantânea e intuitiva para os compradores.
O que os usuários mais gostam:
"A equipe oferece consistentemente insights valiosos e alternativas para melhorar a funcionalidade e a eficácia da Ferramenta Shop Similar. Trabalhar com a Syte facilita o alcance dos KPIs específicos do nosso site."
- Avaliação do Syte, Gabriella M.
O que os usuários não gostam:
"Houve alguma dificuldade em habilitar diferentes contas para o painel de análise. Seria bom não ter restrições nesses logins (diferentes usuários deveriam poder acessá-lo)."
- Avaliação do Syte, Antonio R.
5. Dataloop
Dataloop é uma plataforma de desenvolvimento de IA que permite que empresas construam suas próprias aplicações de IA facilmente e com conjuntos de dados intuitivos. Ferramentas dentro do software permitem que equipes otimizem a anotação de imagens, seleção de modelos e implantações de modelos para aplicação em larga escala.
O que os usuários mais gostam:
"O Dataloop também tem um grande número de recursos que o tornam conveniente para muitos usuários de diferentes projetos. Após cada atualização, são fornecidas instruções que explicam as mudanças, facilitando sua implementação."
- Avaliação do Dataloop, Mzamil J.
O que os usuários não gostam:
"Tive desafios com algumas curvas de aprendizado acentuadas, dependência de infraestrutura e limitações de personalização. Isso de certa forma me limitou em seu uso."
- Avaliação do Dataloop, Dennis R.

Comece a trabalhar com IA porque YOLO!
Em menos de uma década, o YOLO fez progressos significativos e se tornou o método preferido de detecção de objetos para muitas indústrias. Graças à sua abordagem eficiente e precisa para reconhecimento de imagem, é ideal para necessidades em tempo real enquanto você explora o mundo da IA.
Saiba mais sobre redes neurais artificiais e como os modelos são projetados para imitar o cérebro humano.
Editado por Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.

