

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
Se você é alguém como eu, gosta de estrutura, organização e simplicidade.
Mas, em alguns casos, é melhor dar um passo atrás e permitir que o caos organizado se desenrole. Esta é a base de algo chamado data lake.
O que é um data lake?
Definição de data lake
Um data lake é um repositório para dados estruturados, não estruturados e semiestruturados. Os data lakes são muito diferentes dos data warehouses, pois permitem que os dados estejam em sua forma mais bruta, sem precisar ser convertidos e analisados primeiro.
Em termos mais simples, todos os tipos de dados gerados por humanos e máquinas podem ser carregados em um data lake para classificação e análise posteriormente.
Os data warehouses, por outro lado, exigem que os dados sejam devidamente estruturados antes que qualquer trabalho possa ser realizado.
Para entender melhor os data lakes e por que eles são a escolha ideal para abrigar big data, é importante mergulhar no que os torna tão diferentes dos data warehouses.
Quer aprender mais sobre Soluções de Data Warehouse? Explore os produtos de Armazém de Dados.
Data lake vs. data warehouse
Tanto os data lakes quanto os data warehouses são repositórios de dados. Essa é praticamente a única semelhança entre os dois. Agora, vamos abordar algumas das principais diferenças:
- Os data lakes são projetados para suportar todos os tipos de dados, enquanto os data warehouses utilizam dados altamente estruturados – na maioria dos casos.
- Os data lakes armazenam todos os dados que podem ou não ser analisados em algum momento no futuro. Este princípio não se aplica aos data warehouses, já que dados irrelevantes são tipicamente eliminados devido ao armazenamento limitado.
- A escala entre data lakes e data warehouses é drasticamente diferente devido aos nossos pontos anteriores. Apoiar todos os tipos de dados e armazenar esses dados (mesmo que não sejam imediatamente úteis) significa que os data lakes precisam ser altamente escaláveis.
- Graças aos metadados (dados sobre dados), os usuários que trabalham com um data lake podem obter rapidamente uma visão básica sobre os dados. Nos data warehouses, muitas vezes é necessário que um membro da equipe de desenvolvimento acesse os dados – o que pode criar um gargalo.
- Por último, o intenso gerenciamento de dados exigido pelos data warehouses significa que eles são tipicamente mais caros de manter em comparação com os data lakes.
James Dixon, fundador e Diretor de Tecnologia da Pentaho, cunhou o termo “data lake” após fornecer uma analogia diferenciando data lakes de data warehouses.
“Se você pensar em um datamart como uma loja de água engarrafada – limpa, embalada e estruturada para fácil consumo – o data lake é um grande corpo de água em um estado mais natural”, disse Dixon. “O conteúdo do data lake flui de uma fonte para encher o lago, e vários usuários do lago podem vir para examinar, mergulhar ou tirar amostras.”
James Dixon
fundador e Diretor de Tecnologia da Pentaho
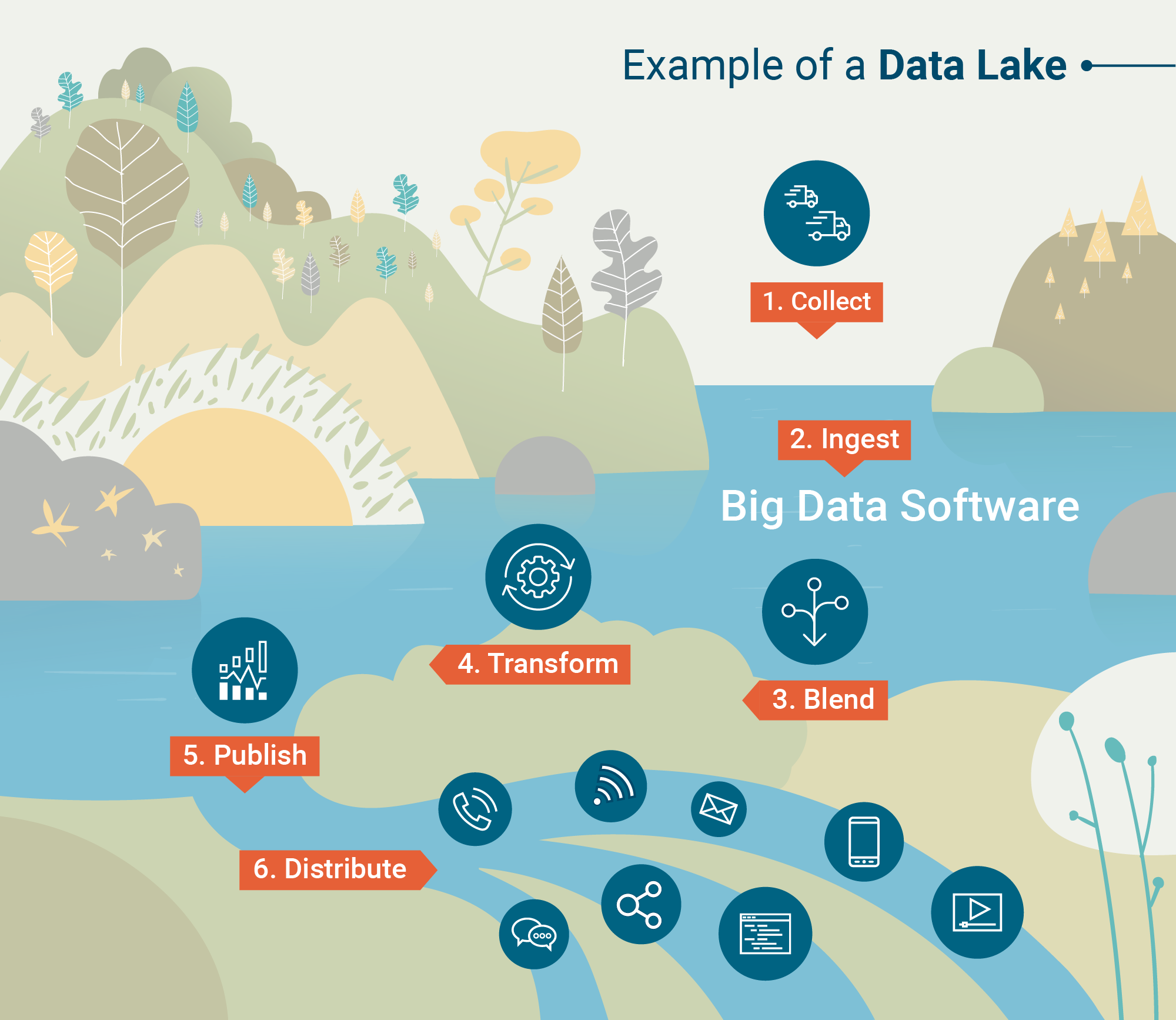
Arquitetura de data lake
Então, como os data lakes são capazes de armazenar quantidades tão vastas e diversificadas de dados? Qual é a arquitetura subjacente desses repositórios massivos?
Os data lakes são construídos sobre um modelo de dados schema-on-read. Um esquema é essencialmente o esqueleto de um banco de dados que descreve seu modelo e como os dados serão estruturados dentro dele. Pense em um projeto.
O modelo de dados schema-on-read significa que você pode carregar seus dados no lago como estão, sem precisar se preocupar com sua estrutura. Isso permite muito mais flexibilidade.
Data warehouses, por outro lado, são compostos por modelos de dados schema-on-write. Este é um modelo muito mais tradicional para bancos de dados.
Cada conjunto de dados, cada relacionamento e cada índice no modelo de dados schema-on-write deve ser claramente definido com antecedência. Isso limita a flexibilidade, especialmente ao adicionar novos conjuntos de dados ou recursos que poderiam potencialmente criar lacunas dentro do banco de dados.
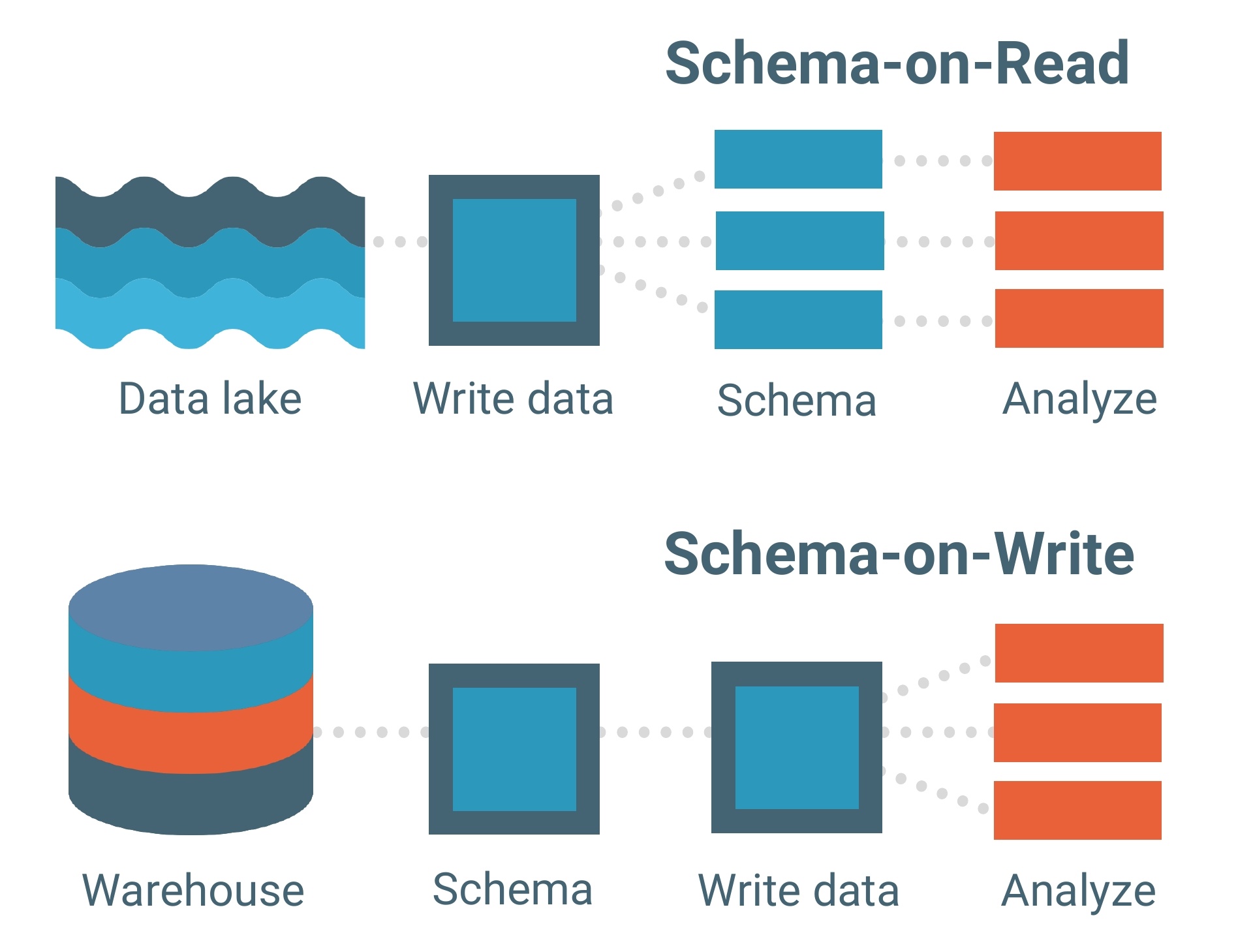
O modelo de dados schema-on-read atua como a espinha dorsal de um data lake, mas a estrutura de processamento (ou motor) é como os dados realmente são carregados em um.
Abaixo estão as duas estruturas de processamento que “ingerem” dados em data lakes:
- Processamento em lote – Milhões de blocos de dados processados ao longo de longos períodos de tempo (de horas a dias). O método menos sensível ao tempo para processar big data.
- Processamento em fluxo – Pequenos lotes de dados processados em tempo real. O processamento em fluxo está se tornando cada vez mais valioso para empresas que utilizam análises em tempo real.

Hadoop, Apache Spark e Apache Storm estão entre as ferramentas de processamento de big data mais comumente usadas, capazes de realizar processamento em lote ou em fluxo.
Algumas ferramentas são particularmente úteis para processar dados não estruturados, como atividade de sensores, imagens, postagens em redes sociais e atividade de cliques na internet. Outras ferramentas priorizam a velocidade de processamento e a utilidade com programas de aprendizado de máquina.
Uma vez que os dados são processados e ingeridos no data lake, é hora de utilizá-los.
Para que são usados os data lakes?
Os data warehouses dependem de estrutura e dados limpos, enquanto os data lakes permitem que os dados estejam em sua forma mais natural. Isso ocorre porque ferramentas analíticas avançadas e software de mineração de dados ingerem dados brutos e os transformam em insights úteis.
Análise de big data
A análise de big data mergulhará em um data lake na tentativa de descobrir padrões, tendências de mercado e preferências dos clientes para ajudar as empresas a fazer previsões informadas mais rapidamente. Isso é feito por meio de quatro análises diferentes.
- Análise descritiva – Uma análise retrospectiva que examina “onde” um problema pode ter ocorrido para uma empresa. A maioria das análises de big data hoje são, na verdade, descritivas porque podem ser geradas rapidamente.
- Análise diagnóstica – Outra análise retrospectiva que examina “por que” um problema específico pode ter ocorrido para uma empresa. Isso é um pouco mais aprofundado do que a análise descritiva.
- Análise preditiva – Quando o software de IA e aprendizado de máquina é aplicado, essa análise pode fornecer a uma organização modelos preditivos do que pode ocorrer a seguir. Devido à complexidade de gerar análises preditivas, ainda não é amplamente adotada.
- Análise prescritiva – O futuro da análise de big data são as análises prescritivas, que não apenas auxiliam nos esforços de tomada de decisão, mas podem até ser capazes de fornecer a uma organização um conjunto de respostas. Há um uso muito elevado de aprendizado de máquina nessas análises.
Mineração de dados
A mineração de dados é definida como “descoberta de conhecimento em bancos de dados” e é como os cientistas de dados descobrem padrões e verdades anteriormente não vistos por meio de vários modelos.
Por exemplo, uma análise de agrupamento é um tipo de técnica de mineração de dados que pode ser aplicada a um conjunto dentro de um data lake. Isso agrupará grandes quantidades de dados com base em suas semelhanças.
Por meio de ferramentas de visualização de dados, a mineração de dados ajuda a esclarecer a natureza caótica dos dados não estruturados e brutos.
Desafios dos data lakes
Os data lakes podem ser flexíveis, escaláveis e rápidos de carregar, mas isso tem um preço.
Ingerir dados não estruturados requer uma falta de governança de dados e processos que garantam que os dados certos estejam sendo analisados. Para a maioria das empresas – especialmente aquelas que ainda não adotaram big data – ter dados desorganizados e não limpos não é uma opção.
O uso indevido de metadados ou processos para manter o data lake sob controle pode realmente levar a algo chamado pântano de dados. Você não iria nadar em um pântano, iria?
Há também a questão da segurança de dados.
Os data lakes são um conceito relativamente novo em TI, o que significa que algumas das ferramentas ainda estão resolvendo os problemas de segurança. Um desses problemas é garantir que apenas as pessoas certas tenham acesso aos dados sensíveis carregados no lago.
Mas, como qualquer nova tecnologia, esses problemas serão resolvidos com o tempo.
| DICA: Pronto para mergulhar mais fundo no mundo dos dados? Aprenda o básico sobre gerenciamento de dados mestres (MDM) e por que é importante para as empresas. |
O papel dos data lakes com big data
Apesar de alguns dos desafios dos data lakes, o fato é que mais de 80% de todos os dados são não estruturados. À medida que mais empresas recorrem ao big data para oportunidades futuras, a aplicação de data lakes aumentará.
Dados não estruturados, como postagens em redes sociais, gravações de chamadas telefônicas e atividade de cliques contêm informações valiosas que não podem ser retidas em data warehouses.
Enquanto os data warehouses são fortes em estrutura e segurança, o big data simplesmente precisa estar livre para fluir livremente em data lakes.
Confira nosso guia completo sobre dados estruturados vs. não estruturados para uma explicação mais detalhada ou leia sobre a importância da engenharia de big data.