
Chayanika Sen
Chayanika is a B2B Tech and SaaS content writer. She specializes in writing data-driven and actionable content in the form of articles, guides, and case studies. She's also a trained classical dancer and a passionate traveler.
Imagine traduzir sem esforço um livro inteiro de uma língua para outra ou condensar páginas de texto denso em algumas frases claras – tudo com apenas alguns cliques.
Para os praticantes de aprendizado de máquina (ML), realizar tais tarefas é como navegar em um labirinto de complexidades. Dados sequenciais apresentam desafios únicos: entradas ruidosas, dependências ocultas e previsões que falham quando o contexto é perdido.
Modelos Seq2Seq são projetados para enfrentar esses desafios exatos.
O que é Seq2Seq?
Seq2Seq (sequência para sequência) é um modelo de aprendizado de máquina projetado para mapear uma sequência de entrada para uma sequência de saída. Essa abordagem é amplamente utilizada em tarefas onde a entrada e a saída diferem em comprimento, como tradução de idiomas, sumarização de texto ou conversão de fala para texto.
Modelos Seq2Seq são comumente integrados em plataformas de ciência de dados e ML e software de processamento de linguagem natural (NLP), fornecendo soluções robustas para aplicações do mundo real, como tradução automática. Eles são particularmente eficazes em tarefas de tradução automática neural, permitindo uma conversão de texto fluente e gramaticalmente precisa entre idiomas como inglês e francês.
Ao contrário dos algoritmos tradicionais, os modelos Seq2Seq são projetados para lidar com sequências mantendo o contexto e a ordem. Isso os torna altamente adequados para tarefas onde o significado da entrada depende da ordem dos pontos de dados, como frases ou dados de séries temporais.
Vamos explorar como o Seq2Seq funciona e por que é uma ferramenta essencial para aplicações de redes neurais. Se você está ansioso para enfrentar desafios do mundo real com ML, você está no lugar certo!
Como funciona o modelo Seq2Seq?
Os modelos Seq2Seq dependem de uma estrutura bem definida para processar sequências e gerar saídas significativas. Através de uma arquitetura cuidadosamente projetada, eles garantem que tanto as sequências de entrada quanto de saída sejam tratadas com precisão e coerência.
Vamos explorar os componentes principais dessa arquitetura e como eles contribuem para a eficácia do modelo.
Arquitetura do modelo Seq2Seq
A arquitetura do modelo Seq2Seq geralmente inclui:
- Camada de entrada. Esta camada recebe a sequência de entrada e a converte em embeddings para processamento posterior. Em implementações práticas, os embeddings geralmente representam sequências de palavras, tokens ou outros pontos de dados, dependendo da tarefa, como sumarização de texto ou tradução de idiomas.
- Codificador. O codificador geralmente consiste em uma rede neural recorrente (RNN), memória de longo curto prazo (LSTM) ou unidade recorrente com portas (GRU), que processa a sequência de entrada e produz um vetor de contexto que resume a sequência.
- Decodificador. Assim como o codificador, um decodificador também é construído usando arquiteturas RNN, LSTM ou GRU. Ele gera a sequência de saída baseando-se no vetor de contexto.
- Mecanismo de atenção (se usado). O mecanismo de atenção é frequentemente implementado como parte do decodificador, onde seleciona dinamicamente partes relevantes da sequência de entrada durante o processo de decodificação para melhorar a precisão.
1. O papel do codificador
O trabalho do codificador é entender e resumir a sequência de entrada, muitas vezes mapeando a sequência em um embedding de tamanho fixo. Esses embeddings ajudam a preservar características críticas, especialmente para tarefas como tradução automática de inglês para francês. O codificador atualiza seu estado de contexto oculto a cada passo de tempo para reter dependências essenciais.
Equação de atualização do estado oculto do codificador:
ht=tanh(W_h*h_(t-1)+W_x*x_t+b_h)Onde:
- ht é o estado oculto no tempo t
- h_(t-1) é o estado oculto anterior
- x_t é a entrada no tempo t
- W_h e W_x são matrizes de pesos
- b_h é o termo de viés
- tanh é a função de ativação
Pontos-chave sobre o codificador:
- Ele processa entradas um elemento de cada vez (por exemplo, palavra por palavra ou caractere por caractere).
- A cada passo, ele atualiza o estado interno do codificador com base no elemento atual e nos estados anteriores.
- Ele produz um vetor de contexto contendo as informações que o decodificador precisa para gerar a saída.
2. O papel do decodificador
O decodificador começa com o vetor de contexto do codificador e prevê a sequência de saída um passo de cada vez. Ele atualiza seu estado oculto com base no estado anterior, no vetor de contexto e na última palavra prevista.
Equação de atualização do estado oculto do decodificador:
st=tanh(W_s*s_(t-1)+ W_y*y_(t-1)+ W_c*c_t+b_s)Onde:
- st: Estado oculto do decodificador no tempo t
- s_(t-1): Estado oculto anterior do decodificador
- y_(t-1): Saída anterior ou token previsto
- c_t: Vetor de contexto (da saída do codificador)
- W_s, W_y, W_c: Matrizes de pesos
- b_s: Termo de viés
- tanh: Função de ativação
Pontos-chave sobre o decodificador:
- O decodificador gera saída um passo de cada vez, prevendo o próximo elemento com base no vetor de contexto e nas previsões anteriores.
- Ele continua até que emita um token único (por exemplo, <END>) que sinaliza a conclusão da sequência.
3. O mecanismo de atenção
A atenção é um aprimoramento poderoso frequentemente adicionado aos modelos Seq2Seq, especialmente ao lidar com frases mais longas. Em vez de depender apenas de um vetor de contexto, a atenção permite que o decodificador olhe para diferentes partes da sequência de entrada enquanto gera cada palavra.
Seq2Seq com atenção calcula pontuações de atenção para focar dinamicamente em diferentes partes da sequência de entrada durante a decodificação.
Fórmula do peso de atenção:
α_ij = exp(e_ij) / Σ_k exp(e_ik)Onde:
- αij: Peso de atenção para a consulta i e chave j
- e_ij: Pontuação de atenção bruta entre a consulta i e chave j
- exp: Função exponencial
- Σ_k exp(e_ik): Soma das pontuações exponenciais para todas as chaves k (termo de normalização)
Esta operação softmax garante que os pesos de atenção somem 1 em todas as chaves.
Por que a atenção é crítica para modelos Seq2Seq
A adição do mecanismo de atenção tornou o Seq2Seq mais robusto e escalável. Veja como:
- Melhor manuseio de sequências longas: Vetores de contexto podem ter dificuldades para reter todas as informações relevantes sem atenção. Isso pode levar a uma qualidade de saída ruim em textos longos.
- Foco adaptativo: A atenção permite que o modelo ajuste o foco em elementos específicos de entrada a cada passo de decodificação, ajudando a criar traduções ou resumos mais precisos.
- Fundamento dos transformadores: A atenção também é um conceito central em arquiteturas modernas de transformadores como BERT, GPT e T5, que se baseiam em modelos Seq2Seq para lidar com tarefas de NLP ainda mais complexas.
4. Treinamento do modelo Seq2Seq
Treinar modelos Seq2Seq requer um grande conjunto de dados de sequências emparelhadas (por exemplo, pares de frases em dois idiomas). O modelo aprende comparando sua saída com a produção correta e ajustando até minimizar os erros. Com o tempo, ele melhora na transformação de sequências.
Quer aprender mais sobre Software de Processamento de Linguagem Natural (PLN)? Explore os produtos de Processamento de Linguagem Natural (PLN).
Como implementar um modelo Seq2Seq no PyTorch
PyTorch é uma estrutura popular de aprendizado profundo para implementar modelos Seq2Seq porque oferece flexibilidade e facilidade de uso.
Aqui está um guia passo a passo para construir uma arquitetura de codificador-decodificador no PyTorch que processa dados sequenciais e produz saídas significativas.
Passo 1: Importar bibliotecas
Para definir e treinar o modelo, importe as bibliotecas necessárias, como PyTorch, NumPy e outras utilidades.

Fonte: ChatGPT
Passo 2: Definir hiperparâmetros
Defina os parâmetros-chave para o modelo, incluindo tamanho de entrada (número de características na entrada), tamanho de saída (características na saída), dimensões ocultas (tamanho das camadas ocultas) e taxa de aprendizado (controla a velocidade de treinamento do modelo).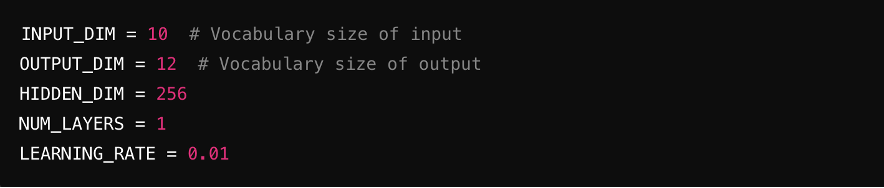
Fonte: ChatGPT
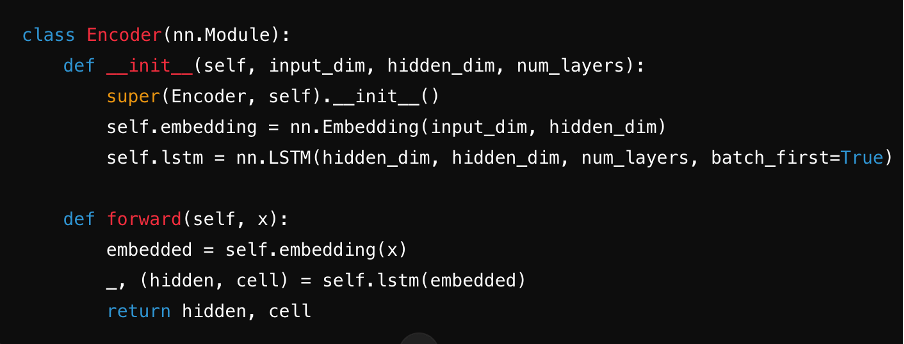
Passo 3: Definir o codificador
Crie o codificador, geralmente usando uma RNN, LSTM ou GRU. Ele processa a frase de entrada passo a passo, resumindo as informações em um vetor de contexto armazenado em seu estado oculto.
Fonte: ChatGPT
Passo 4: Definir o decodificador
Projete o decodificador, que gera a sequência de saída. Ele usa o vetor de contexto do codificador e seus estados ocultos para prever cada saída passo a passo.
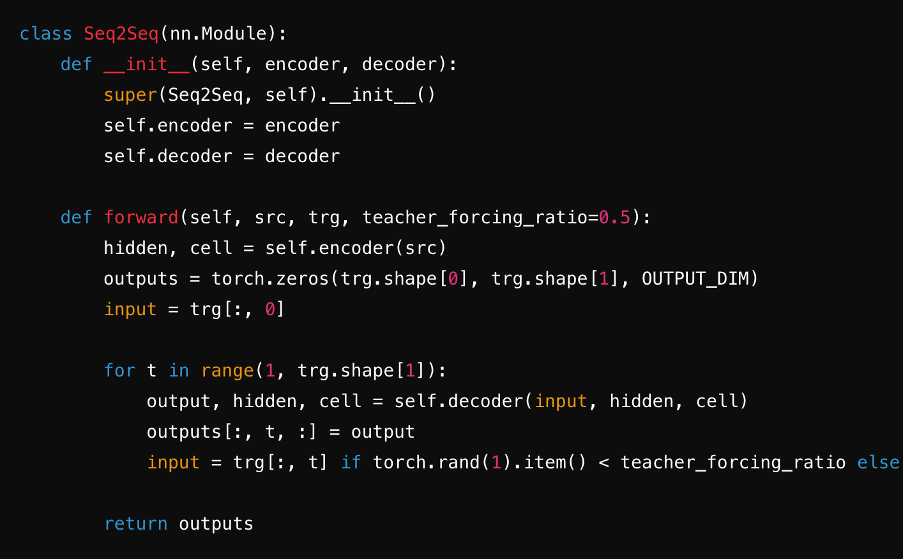
Passo 5: Combinar em um Modelo Seq2Seq
Integre o codificador e o decodificador em um único modelo Seq2Seq. Durante esta etapa, você frequentemente usará camadas lineares e funções softmax para gerar previsões para cada passo de tempo da sequência alvo. Isso garante uma transferência perfeita do vetor de contexto, embeddings e estados ocultos entre os componentes, otimizando a eficiência do modelo.
Fonte: ChatGPT
Passo 6: Treinar o modelo
Implemente um loop de treinamento onde o modelo aprende comparando suas previsões com a verdade do terreno. Otimize os parâmetros usando uma função de perda e um algoritmo como Adam ou SGD. Itere através de épocas, atualizando pesos para minimizar a perda e melhorar o desempenho ao longo do tempo.

Fonte: ChatGPT
Principais aplicações de modelos Seq2Seq em NLP
Seq2Seq é um dos principais algoritmos de aprendizado de máquina para NLP devido à sua flexibilidade e precisão no tratamento de tarefas complexas de linguagem. Ao empregar aprendizado de sequência para sequência com redes neurais, esses modelos se destacam em aplicações como:
- Tradução de idiomas. Seq2Seq se destaca na tradução de texto entre idiomas. Sua capacidade de capturar nuances gramaticais e manter a fluência os torna ideais para alimentar serviços como o Google Tradutor.
- Sumarização de texto. Identificando e condensando informações essenciais, os modelos Seq2Seq criam resumos concisos de artigos, relatórios ou outros textos longos sem perder o significado.
- IA conversacional e chatbots. Modelos Seq2Seq geram respostas naturais e conscientes do contexto, o que os torna essenciais para chatbots, assistentes virtuais e sistemas automatizados de atendimento ao cliente. Sua capacidade de produzir texto coerente e semelhante ao humano também é benéfica para respostas automáticas de e-mail ou geração de histórias.
- Adaptável para dados de comprimento variável. A estrutura codificador-decodificador permite que o Seq2Seq lide com dados de comprimentos variados, tornando-o adequado para tarefas como resposta a perguntas ou geração de código.
Vantagens dos modelos Seq2Seq
Modelos de sequência para sequência oferecem flexibilidade e precisão únicas. Vamos examinar as principais vantagens que tornam o Seq2Seq uma ferramenta poderosa.
- Versatilidade: Modelos Seq2Seq podem lidar com diversas tarefas como tradução de idiomas, sumarização, geração de texto e mais. Sua arquitetura codificador-decodificador os torna adaptáveis a vários desafios de dados sequenciais.
- Preservação de contexto: Esses modelos mantêm o contexto das sequências de entrada, o que os torna especialmente úteis para tarefas que envolvem frases longas ou parágrafos onde o significado depende de partes anteriores da sequência.
- Precisão: Como os modelos Seq2Seq são altamente escaláveis e podem ser treinados em grandes conjuntos de dados, sua precisão e confiabilidade são aprimoradas ao longo do tempo.
- Robustez a dados ruidosos: Capturando efetivamente dependências sequenciais, os modelos Seq2Seq mitigam erros decorrentes de dados ruidosos ou incompletos.
Desvantagens dos modelos Seq2Seq
Entender as limitações dos modelos Seq2Seq é crucial para determinar quando e como implementá-los de forma eficaz. Vamos explorar algumas das possíveis desvantagens.
- Altos requisitos computacionais: Implementar modelos Seq2Seq em dispositivos de poucos recursos é difícil, pois eles exigem muita memória e capacidade de processamento, especialmente quando combinados com mecanismos de atenção.
- Dificuldade em lidar com sequências muito longas: Mesmo com recursos como atenção, os modelos Seq2Seq podem ter dificuldades para processar sequências de entrada prolongadas. Isso pode resultar em perda de contexto ou desempenho ruim em tarefas que envolvem múltiplas dependências.
- Dependência de dados extensivos de treinamento: Para treinar modelos Seq2Seq de forma eficaz, são necessários grandes conjuntos de dados de alta qualidade. Na ausência de dados confiáveis ou dados insuficientes, você pode obter saída de baixa qualidade e resultados não confiáveis.
- Risco de viés de exposição: Modelos Seq2Seq são guiados pelas respostas corretas (dados forçados por professor) durante o treinamento. No entanto, o modelo precisa confiar em suas previsões durante o uso real. Se cometer um erro no início, os erros podem se acumular e afetar a saída final.
O futuro dos modelos Seq2Seq em linguagem e IA
Modelos Seq2Seq têm um futuro promissor em linguagem e IA, particularmente como elementos fundamentais para modelos de linguagem modernos como GPT e BERT.
Com avanços em técnicas de embedding, treinamento adaptativo com otimização de gradiente e tradução automática neural, o Seq2Seq está pronto para enfrentar desafios de NLP ainda mais complexos.
- Expansão de aplicações: Seq2Seq provavelmente se expandirá para mais áreas, como atendimento ao cliente automatizado, escrita criativa e chatbots avançados, tornando as interações mais suaves e intuitivas.
- Melhor manuseio de contextos complexos: Mecanismos de atenção aprimorados e inovações baseadas em transformadores estão ajudando os modelos Seq2Seq a entender nuances mais profundas da linguagem.
- Adaptabilidade a idiomas de poucos recursos: Com mais pesquisas, os modelos Seq2Seq podem ser capazes de suportar uma gama mais ampla de idiomas, incluindo aqueles com menos dados de treinamento.
- Integração com IA avançada: Seq2Seq é fundamental para modelos mais novos como GPT e BERT, que continuarão a expandir os limites no processamento de linguagem natural.
Desbloqueando novos horizontes com modelos Seq2Seq
Modelos Seq2Seq revolucionaram a forma como processamos e entendemos a linguagem em IA, oferecendo versatilidade e precisão incomparáveis. Desde traduzir idiomas de forma fluente até gerar texto semelhante ao humano, eles são a espinha dorsal das aplicações modernas de NLP.
À medida que avanços como mecanismos de atenção e transformadores evoluem, os modelos Seq2Seq se tornarão ainda mais poderosos e eficientes, enfrentando desafios cada vez mais complexos em linguagem e redes neurais. Seja um entusiasta de ML ou um praticante experiente, explorar o Seq2Seq abre a porta para criar soluções mais inovadoras e conscientes do contexto.
O futuro da IA é sequencial – você está pronto para entrar nele?
Descubra as melhores soluções LLM para construir e escalar seus modelos de aprendizado de máquina.