

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
La scienza dei dati unisce il mondo e concentra informazioni distribuite casualmente in piccole unità.
Con tutto il clamore sui big data, dati strutturati vs dati non strutturati e su come le aziende li utilizzano, potresti chiederti: "A quali tipi di dati ci riferiamo?"
La prima cosa da capire è che non tutti i dati sono creati uguali. Questo significa che i dati generati dalle app di social media sono completamente diversi dai dati generati dai sistemi di punto vendita o di catena di approvvigionamento.
Alcuni dati sono strutturati, ma la maggior parte non lo è. Nel backend, un software di gestione di database (DBMS) è un sistema di gestione delle query che autentica l'accesso dell'utente a questi dati e la capacità di memorizzarli, gestirli e recuperarli tramite query utente.
Per chiarire, analizziamo le differenze uniche tra dati strutturati e non strutturati.
Qual è la differenza tra dati strutturati e non strutturati?
I dati strutturati sono altamente organizzati e formattati in modo che siano facilmente ricercabili nei database relazionali. I dati non strutturati non hanno un formato o un'organizzazione predefiniti, rendendoli molto più difficili da raccogliere, elaborare e analizzare. I dati strutturati sono più finiti e ordinati in array di dati, mentre i dati non strutturati sono sparsi e variabili.
Oltre ad essere raccolti, raccolti e scalati in modi diversi, i dati strutturati e non strutturati risiederanno in database completamente separati.
Cosa sono i dati strutturati?
I dati strutturati sono più spesso categorizzati come dati quantitativi, ed è il tipo di dati con cui la maggior parte di noi è abituata a lavorare. Pensa a dati che si adattano perfettamente a campi e colonne fissi nei database relazionali e nei fogli di calcolo.
Esempi di dati strutturati includono nomi, date, indirizzi, numeri di carte di credito, informazioni sulle azioni, geolocalizzazione e altro.
I dati strutturati sono altamente organizzati e facilmente comprensibili dal linguaggio macchina. Coloro che lavorano all'interno di database relazionali possono rapidamente inserire, cercare e manipolare i dati strutturati utilizzando un sistema di gestione di database relazionali (RDBMS). Questa è la caratteristica più attraente dei dati strutturati.
Il linguaggio di programmazione per la gestione dei dati strutturati si chiama linguaggio di query strutturato, noto anche come SQL. IBM ha sviluppato questo linguaggio nei primi anni '70, ed è particolarmente utile per gestire le relazioni nei database.
Esempi di dati strutturati
Se questo sembra confuso, ecco un esempio di un comando DDL (linguaggio di definizione dei dati) eseguito per tabulare dati strutturati. I dati sono memorizzati in una tabella SQL, ogni riga e colonna contribuisce a un tipo di dato specifico.
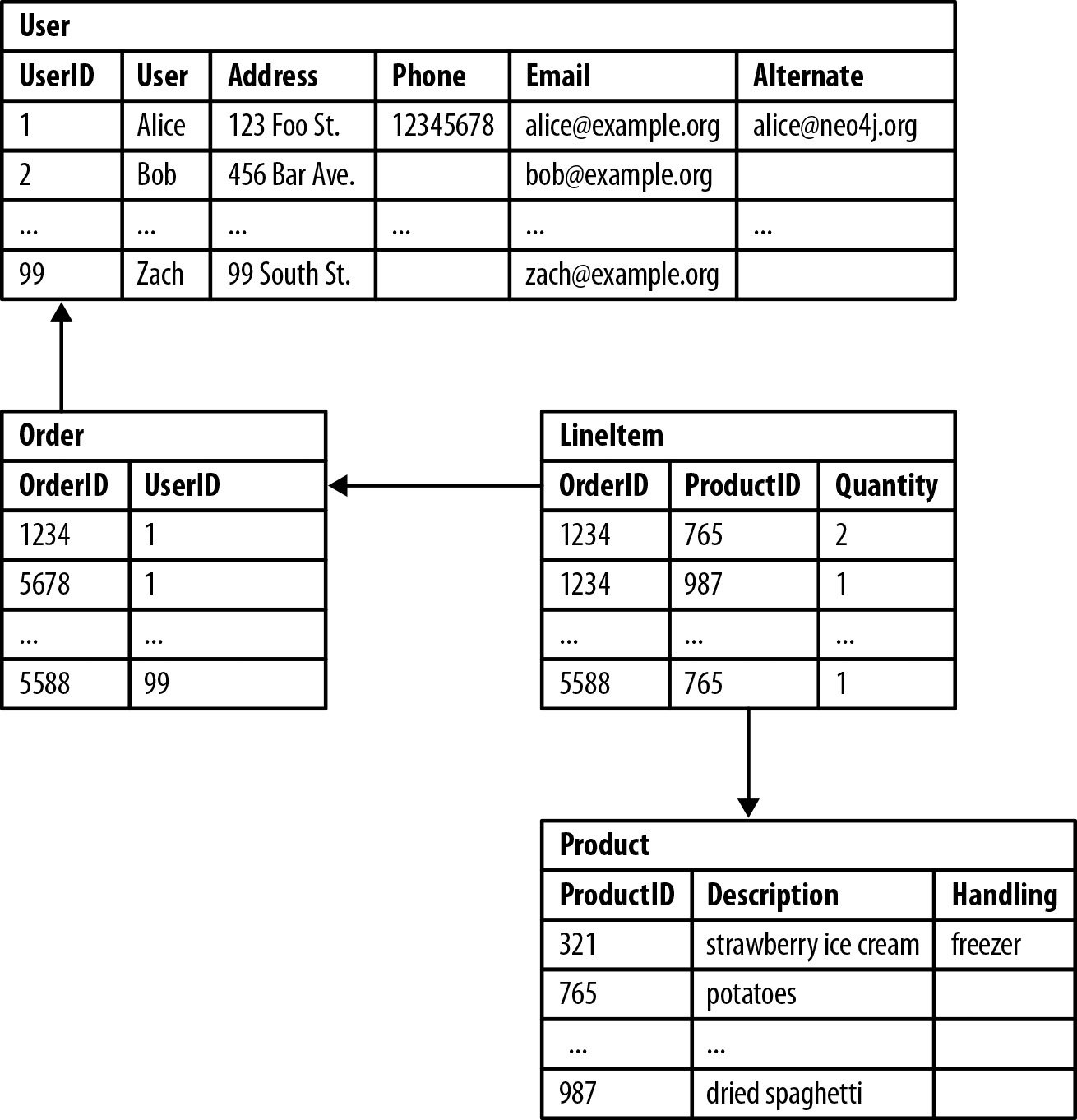
Dall'alto verso il basso, possiamo vedere che UserID 1 si riferisce al cliente Alice, che aveva due Order IDs di '1234' e '5678'. Successivamente, Alice aveva due ProductIDs di '765' e '987'. Infine, possiamo vedere che Alice ha acquistato due pacchetti di patate e un pacchetto di spaghetti secchi.
I dati strutturati sono utilizzati anche nei sistemi di prenotazione aerea, nei sistemi di ridesharing elettronico, nelle app di cibo e consegna e nell'ottimizzazione dei motori di ricerca (dati SEO). In ciascuno di questi casi, i dati sono memorizzati in database relazionali e possono essere memorizzati, recuperati o gestiti in grandi forme.
I dati strutturati hanno rivoluzionato i sistemi basati su carta su cui le aziende si affidavano per business intelligence decenni fa. Mentre i dati strutturati sono ancora utili, più aziende stanno cercando di decostruire i dati non strutturati per opportunità future.

Fonte: Fivetran
Esempi di dati strutturati
I dati strutturati sono utilizzati in molteplici database aziendali orientati al consumatore o ERP, come:
- E-commerce: Dati di recensione, dati di prezzo e numero SKU delle merci
- Sanità: amministrazione ospedaliera, farmacia e dati dei pazienti e storia medica dei pazienti.
- Bancario: Dettagli delle transazioni finanziarie come nome del beneficiario, dettagli del conto, informazioni sul mittente o ricevente e dettagli bancari.
- Software di gestione delle relazioni con i clienti (CRM): dati di acquisizione lead, fonte, attività e così via dei lead nel database CRM.
- Industria dei viaggi: Dati dei passeggeri, informazioni sui voli e transazioni di viaggio.
Dati strutturati vs. dati non strutturati
I dati non strutturati sono l'opposto polare dei dati strutturati. Ecco un riassunto delle differenze notevoli tra i due.

I dati strutturati sono dati preformattati puliti disposti ordinatamente in blocchi di memoria. Il suo formato è predefinito in righe e colonne e memorizzato in sistemi di database relazionali (RDBMS) o Microsoft Excel. I dati sono conosciuti come "schema on write", rappresentando dati per uno schema di database ampio o un progetto. È altamente scalabile e sicuro e richiede meno gestione.
I dati non strutturati sono altamente complessi, qualitativi e disorganizzati. Sono anche noti come big data, che non si conformano a uno standard particolare. Questi dati possono essere numerici, alfabetici, booleani o un mix di tutti. Sono memorizzati utilizzando un database NoSQL. Non possono essere memorizzati in un database relazionale o RDBMS poiché le stringhe di dati hanno tipi di dati misti che non possono adattarsi né a una riga né a una colonna. Tipi comuni di dati non strutturati sono dati clickstream, dati dei social media, testo e multimedia.
Correlato: Esplora SQL vs. NoSQL per vedere quale database è giusto per te.
Benefici dei dati strutturati
È facile memorizzare, recuperare e gestire i dati strutturati poiché ha un meccanismo di backend organizzato. Utilizzare dati strutturati in azienda può portare ai seguenti benefici.
- I dati strutturati possono essere facilmente inseriti nei modelli di machine learning come set di dati di input senza alcuna modifica.
- Lavorare con dati strutturati non richiede competenze in AI o ML. Chiunque con buone informazioni sul prodotto e conoscenze di base sulla scienza dei dati può farlo.
- I dati strutturati sono memorizzati uniformemente in data warehouse o fogli di calcolo. La sua natura specifica e organizzata lo rende facile da manipolare e interrogare.
- I dati strutturati precedono i dati non strutturati, quindi sono disponibili più strumenti di analisi per misurarli e analizzarli.
- I dati sono di qualità superiore, consistenza e usabilità rispetto ai dati non strutturati.
- Ci sono meccanismi di fallback per adattarsi se l'utente incontra un errore durante la gestione dei dati strutturati.
- È anche noto come dati quantitativi, poiché le aziende utilizzano le loro metriche per prevedere le tendenze aziendali e l'impatto strategico.
- È mantenuto in un repository stabile e centralizzato che migliora il flusso dei processi aziendali e il processo decisionale per ottimizzare il ROI.
Sfide dei dati strutturati
La maggior parte dei problemi dei dati strutturati evidenzia la sua inflessibilità e rigidità nel scalare schemi di database più grandi. I dati strutturati sono "schema on write" o "fortemente dipendenti dallo schema" per le operazioni. Le sfide comuni dei dati strutturati sono elencate di seguito:
- Poiché i dati strutturati sono dipendenti dallo schema, è un po' difficile scalarli per grandi database.
- Il tempo necessario per caricare i dati strutturati è a volte sottovalutato. Identificare problemi nascosti nel sistema sorgente e aggiornarli, recuperarli e ripristinarli può consumare il tuo spazio di archiviazione cloud.
- Non si adatta bene al cambiamento dello scenario aziendale. È difficile determinare quale query porterebbe a un risultato aziendale specifico. La natura delle query e delle transazioni cambia man mano che un'azienda sposta il suo focus sui consumatori.
- I dati strutturati sono inseriti manualmente nel sistema di gestione dei database. L'utente deve digitare un comando DDL (linguaggio di definizione dei dati) come Create, Insert e Select per ordinare, gestire e recuperare i dati dal sistema.
Strumenti per i dati strutturati
Oltre a utilizzare un linguaggio di query strutturato (SQL) o Microsoft Excel per gestire le manipolazioni dei dati strutturati, ci sono alcune estensioni di strumenti che puoi utilizzare.
- PL SQL: Procedural Query Language o PL SQL è una versione esistente di SQL che si occupa delle transazioni di lavoro. Le query transazionali comuni sono "commit" o "rollback".
- Postgre SQL: Postgre SQL è un sistema di gestione di database relazionale open-source che gestisce grandi volumi di dati. Supporta anche query SQL e JSON insieme a linguaggi di alto livello.
-
SQLite: È un database di alto livello, autonomo e senza server che gli sviluppatori di software utilizzano per estrarre dati strutturati per integrazioni di app aziendali,
- My SQL è un ambiente di dati integrato standard che utilizza l'autenticazione dell'utente per inserire record di dati tramite query in un database distribuito in massa.
- OLAP: Comprende una categoria più ampia di gestione dei database che include data mining, report mining e business intelligence.

Cosa sono i dati non strutturati?
I dati non strutturati sono spesso categorizzati come qualitativi e non possono essere elaborati e analizzati utilizzando strumenti e metodi di dati convenzionali. Sono anche noti come dati "schema independent" o "schema on read".
Esempi di dati non strutturati includono testo, file video, file audio, attività mobile, post sui social media, immagini satellitari, immagini di sorveglianza – l'elenco continua.
I dati non strutturati sono difficili da decostruire perché non hanno un modello di dati predefinito, il che significa che non possono essere organizzati in database relazionali. Invece, i database non relazionali o NoSQL sono la soluzione migliore per gestire i dati non strutturati.
Un altro modo per gestire i dati non strutturati è farli fluire in un data lake o pool, permettendo loro di essere nel loro formato grezzo e non strutturato.
Trovare l'intuizione nascosta nei dati non strutturati non è un compito facile. Richiede analisi avanzate e alta competenza tecnica per fare la differenza. L'analisi dei dati può essere un cambiamento costoso per molte aziende.
95%
delle aziende cita la necessità di gestire i dati non strutturati come un problema per il loro business.
Fonte: Techjury
Esempi di dati non strutturati
Coloro che sono in grado di sfruttare i dati non strutturati, tuttavia, hanno un vantaggio competitivo. Mentre i dati strutturati ci danno una visione d'insieme dei clienti, i dati non strutturati o big data possono darci informazioni dettagliate sulle azioni quotidiane dei consumatori.
Ad esempio, le tecniche di data mining applicate ai dati non strutturati da un sito web di vendita al dettaglio possono aiutare le aziende a conoscere le abitudini di acquisto dei clienti e il tempismo, i modelli di acquisto, il sentimento verso un prodotto specifico e molto altro.
I dati non strutturati sono anche fondamentali per il software di analisi predittiva. Ad esempio, i dati dei sensori collegati a macchinari industriali possono avvisare i produttori di attività strane in anticipo. Con queste informazioni, una riparazione può essere effettuata prima che la macchina subisca un guasto costoso.
Altri esempi di dati non strutturati:
I dati non strutturati sono qualsiasi evento o avviso inviato e ricevuto da qualsiasi utente all'interno di un'organizzazione senza una formattazione di file adeguata o una co-dipendenza aziendale diretta.
- Media ricchi: Social media, intrattenimento, sorveglianza, informazioni satellitari, dati geospaziali, previsioni meteorologiche, podcast
- Documenti: Fatture, registri, cronologia web, email, applicazioni di produttività
- Dati dei media e dell'intrattenimento, dati di sorveglianza, dati geospaziali, audio, dati meteorologici
- Internet delle cose: dati dei sensori, dati ticker
- Analisi: Machine learning, intelligenza artificiale (AI)
Benefici dei dati non strutturati
I dati non strutturati, noti anche come big data al giorno d'oggi, sono liberi e nativi di ciascuna azienda specifica. Sono schema independent e sono noti come "schema on read". Personalizzare questi dati in base alle tue strategie aziendali può darti un vantaggio competitivo rispetto ai concorrenti ancora bloccati nei processi decisionali tradizionali. Ecco perché.
- I dati non strutturati sono facilmente disponibili e hanno abbastanza intuizioni che le aziende possono raccogliere per conoscere la risposta del loro prodotto.
- I dati non strutturati sono schema-independent. Pertanto, piccole modifiche al database non influiscono su costi, tempo o risorse.
- I dati non strutturati possono essere memorizzati su server cloud condivisi o ibridi con una spesa minima per la gestione del database.
- I dati non strutturati sono nel loro formato nativo, quindi i data scientist o gli ingegneri non li definiscono fino a quando non sono necessari. Ciò apre l'espandibilità dei formati di file, poiché sono disponibili in diversi formati come .mp3, .opus, .pdf, .png e così via.
- I data lake offrono prezzi "pay-as-you-use", che aiutano le aziende a ridurre i costi e il consumo di risorse.
Sfide dei dati non strutturati
I dati non strutturati sono il metodo di raccolta e manipolazione dei dati più in voga oggi. Molte aziende stanno passando a modelli di business più "customer-centric" e puntano sui dati dei consumatori. Tuttavia, lavorare sui dati non strutturati comporta le seguenti sfide.
- I dati non strutturati non sono i più facili da comprendere. Gli utenti richiedono una solida formazione in scienza dei dati e machine learning per prepararli, analizzarli e integrarli con algoritmi di machine learning.
- I dati non strutturati si trovano su server condivisi meno autentici e crittografati, che sono più soggetti a ransomware e attacchi informatici.
- Attualmente, non ci sono molti strumenti che possono manipolare i dati non strutturati a parte i server di commodity cloud e i DBMS NoSQL open-source.
Strumenti per i dati non strutturati
Oltre a utilizzare un NoSQL per gestire le manipolazioni dei dati non strutturati, ci sono alcuni altri strumenti che puoi utilizzare.
- Hadoop: Un framework di calcolo distribuito per elaborare grandi quantità di dati non strutturati.
- Apache Spark: Un framework di calcolo a cluster veloce e generico per elaborare dati strutturati e non strutturati.
- Strumenti di elaborazione del linguaggio naturale (NLP): Per estrarre informazioni dai dati di testo non strutturati.
- Librerie di machine learning: Per costruire modelli per analizzare e prevedere modelli nei dati non strutturati.
Altri tipi di dati
Oltre ai tipi di dati sopra menzionati, i dati semi-strutturati e i metadati sono cruciali nella gestione della crescente complessità e diversità delle moderne fonti di dati.
Cosa sono i dati semi-strutturati?
I dati semi-strutturati sono un tipo di dati strutturati che si collocano a metà strada tra i dati strutturati e non strutturati. Non hanno un modello di dati relazionale o tabulare specifico, ma includono tag e marcatori semantici che scalano i dati in record e campi in un set di dati.
Esempi comuni di dati semi-strutturati sono JSON e XML. I dati semi-strutturati sono più complessi dei dati strutturati ma meno complessi dei dati non strutturati. Sono anche relativamente più facili da memorizzare rispetto ai dati non strutturati, colmando il divario tra i due tipi di dati.
Una sitemap XML contiene informazioni sulle pagine di un sito web. Incorpora URL, punteggi di dominio, pagine do-follow e meta tag.
Cosa sono i metadati?
I metadati sono spesso utilizzati nell'analisi dei big data e sono un set di dati master che descrive altri tipi di dati. Hanno campi preimpostati che contengono informazioni aggiuntive su un set di dati specifico.
I metadati hanno una struttura definita identificata da uno schema di markup dei metadati che include modelli e standard di metadati. Contengono dettagli preziosi per aiutare gli utenti ad analizzare meglio i dati e prendere decisioni informate.
Ad esempio, un articolo online può visualizzare metadati come un titolo, un frammento, un'immagine in evidenza, un testo alternativo dell'immagine, uno slug e altre informazioni correlate. Queste informazioni aiutano a differenziare un contenuto da diversi altri contenuti simili sul web. Pertanto, i metadati sono un set di dati utile che funge da cervello per tutti i tipi di dati.
Strumenti di gestione dei database
Gli strumenti di gestione dei database forniscono l'infrastruttura per memorizzare, gestire, e analizzare i dati in modo efficace, garantendo una gestione efficiente dei dati e intuizioni preziose. Utilizzare lo strumento di gestione dei database giusto permetterà alle aziende di:
- Ridurre i costi operativi
- Monitorare le metriche attuali e crearne di nuove
- Comprendere i propri clienti a un livello molto più profondo
- Svelare campagne di marketing più intelligenti e mirate
- Trovare nuove opportunità e offerte di prodotti
I 5 migliori strumenti di gestione dei dati:
*Qui sopra sono elencate le cinque principali soluzioni software di gestione dei dati dal report Grid® Summer 2024 di G2.
Come i dati, come le decisioni
Il volume dei big data continua a crescere, ma l'importanza dell'archiviazione dei big data cesserà presto di esistere.
Che i dati siano strutturati o non strutturati, avere le fonti di dati più accurate e rilevanti sarà fondamentale per le aziende che cercano di ottenere un vantaggio sui loro concorrenti.
Più varietà di dati create dai data scientist, più nuovi e avanzati algoritmi verranno creati, il che faciliterà la linea di conformità GDPR.
I dati stanno penetrando in ogni settore importante del mondo. I marchi si stanno allontanando da espedienti di marketing non essenziali per un marketing dei consumatori basato sui dati. Le informazioni che i dati ci forniscono vengono apprese e analizzate in tandem con l'intelligenza artificiale e il calcolo di rete per creare soluzioni robuste e iperconnesse.
Alla fine della giornata, spetta al consumatore determinare quanto si senta a suo agio con i modi in cui i suoi dati vengono utilizzati.
Nuovo all'analisi dei big data ma vuoi saperne di più? Scopri come ottenere informazioni in tempo reale dai tuoi dati con il giusto software di analisi dei big data.
Questo articolo è stato originariamente pubblicato nel 2021. È stato aggiornato con nuove informazioni.