

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.
Vladimir N. Vapnik desarrolló algoritmos de máquinas de vectores de soporte (SVM) para abordar problemas de clasificación en la década de 1990. Estos algoritmos encuentran un hiperplano óptimo, que es una línea en un plano 2D o 3D, entre dos categorías de conjuntos de datos para distinguir entre ellas.
Las SVM facilitan el proceso del algoritmo de aprendizaje automático (ML) para generalizar nuevos datos mientras realizan predicciones de clasificación precisas.
Muchos software de reconocimiento de imágenes y plataformas de clasificación de texto utilizan SVM para clasificar imágenes o documentos textuales. Pero el alcance de las SVM va más allá de esto. Después de cubrir los fundamentos, exploremos algunos de sus usos más amplios.
¿Qué son las máquinas de vectores de soporte?
Las máquinas de vectores de soporte (SVM) son algoritmos de aprendizaje automático supervisado que desarrollan métodos de clasificación de objetos en un espacio n-dimensional. Las coordenadas de estos objetos suelen llamarse características.
Las SVM trazan un hiperplano para separar dos categorías de objetos de modo que todos los puntos de una categoría de objetos estén en un lado del hiperplano. El objetivo es encontrar el mejor plano, que maximice la distancia (o margen) entre dos puntos en cada categoría. Los puntos que caen en este margen se llaman vectores de soporte. Estos vectores de soporte son críticos para definir el hiperplano óptimo.
Entendiendo las máquinas de vectores de soporte en detalle
Las SVM requieren entrenamiento en puntos etiquetados de categorías específicas para encontrar el hiperplano, lo que las convierte en un algoritmo de aprendizaje supervisado. El algoritmo resuelve un problema de optimización convexa en el fondo para maximizar el margen con cada punto de categoría en el lado correcto. Basado en este entrenamiento, puede asignar una nueva categoría a un objeto.

Fuente: Visually Explained
Las máquinas de vectores de soporte son fáciles de entender, implementar, usar e interpretar. Sin embargo, su simplicidad no siempre les beneficia. En algunas situaciones, es imposible separar dos categorías con un simple hiperplano. Para resolver esto, el algoritmo encuentra un hiperplano en el espacio de mayor dimensión con una técnica conocida como truco del núcleo y lo proyecta de nuevo al espacio original.
Es el truco del núcleo lo que te permite realizar estos pasos de manera eficiente.
¿Quieres aprender más sobre Software de reconocimiento de imágenes? Explora los productos de Reconocimiento de imágenes.
¿Qué es un truco del núcleo?
En el mundo real, separar la mayoría de los conjuntos de datos con un simple hiperplano es un desafío ya que el límite entre dos clases rara vez es plano. Aquí es donde entra el truco del núcleo. Permite a las SVM manejar eficientemente límites de decisión no lineales sin alterar significativamente el algoritmo en sí.
Sin embargo, elegir esta transformación no lineal es complicado. Para obtener un límite de decisión sofisticado, necesitas aumentar la dimensión de la salida, lo que incrementa los requisitos computacionales.
El truco del núcleo resuelve estos dos desafíos de un solo golpe. Se basa en un enfoque donde el algoritmo SVM no necesita saber cuándo cada punto se mapea bajo transformación no lineal. Puede trabajar con cómo cada punto de datos se compara con otros.
Al aplicar la transformación no lineal, tomas el producto interno entre F(x) y F(x) prima, conocido como la función del núcleo.
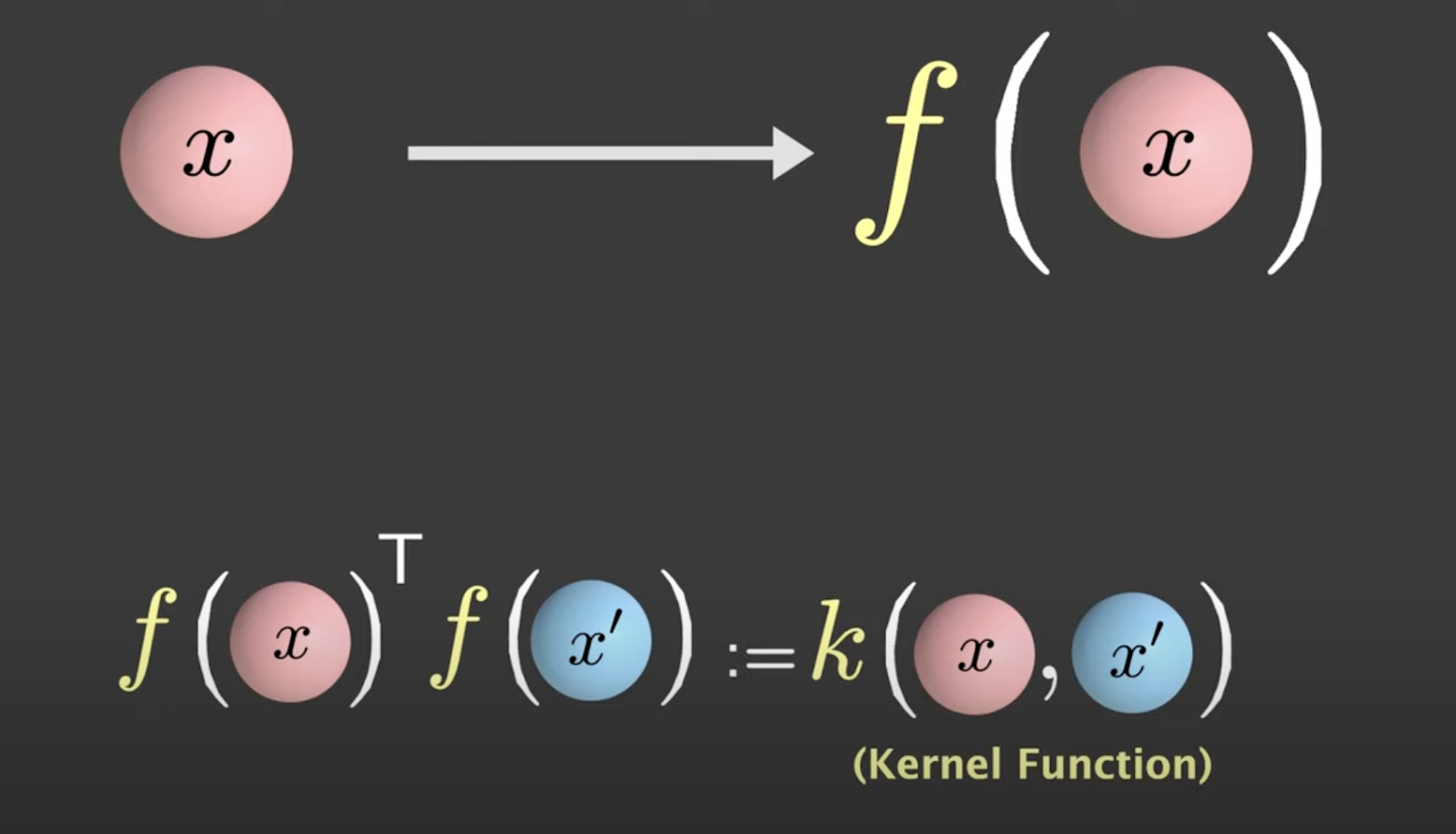
Fuente: Visually Explained
Sin embargo, este núcleo lineal da un límite de decisión que puede o no ser lo suficientemente bueno para separar los datos. En tales casos, optas por una transformación polinómica correspondiente a un núcleo polinómico. Este enfoque toma en cuenta las características originales del conjunto de datos y considera sus interacciones para obtener un límite de decisión más sofisticado y curvado.

Fuente: Visually Explained
El truco del núcleo es beneficioso y se siente como un código de trampa de videojuego. Es fácil de ajustar y ser creativo con los núcleos.
Tipos de clasificadores de máquinas de vectores de soporte
Hay dos tipos de SVM clasificadas: lineales y de núcleo.
1. SVM lineales
Las SVM lineales son cuando los datos no necesitan someterse a ninguna transformación y son linealmente separables. Una sola línea recta puede segregar fácilmente los conjuntos de datos en categorías o clases.
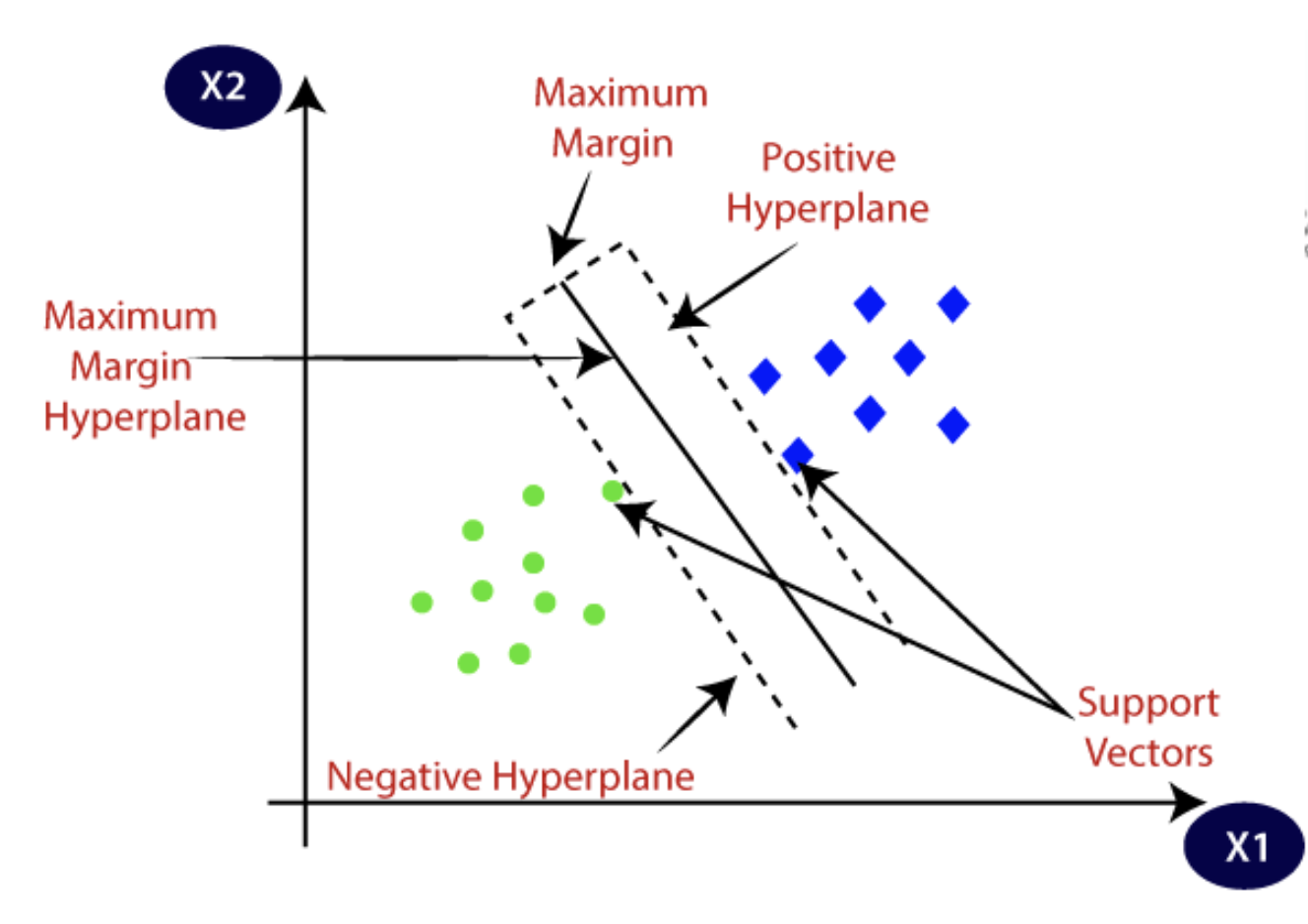
Fuente: Javatpoint
Dado que estos datos son linealmente distintos, el algoritmo aplicado se conoce como SVM lineal, y el clasificador que produce es el clasificador SVM. Este algoritmo es efectivo tanto para problemas de clasificación como de análisis de regresión.
2. SVM no lineales o de núcleo
Cuando los datos no son linealmente separables por una línea recta, se utiliza un clasificador SVM no lineal o de núcleo. Para datos no lineales, la clasificación se realiza agregando características en dimensiones más altas en lugar de depender del espacio 2D.
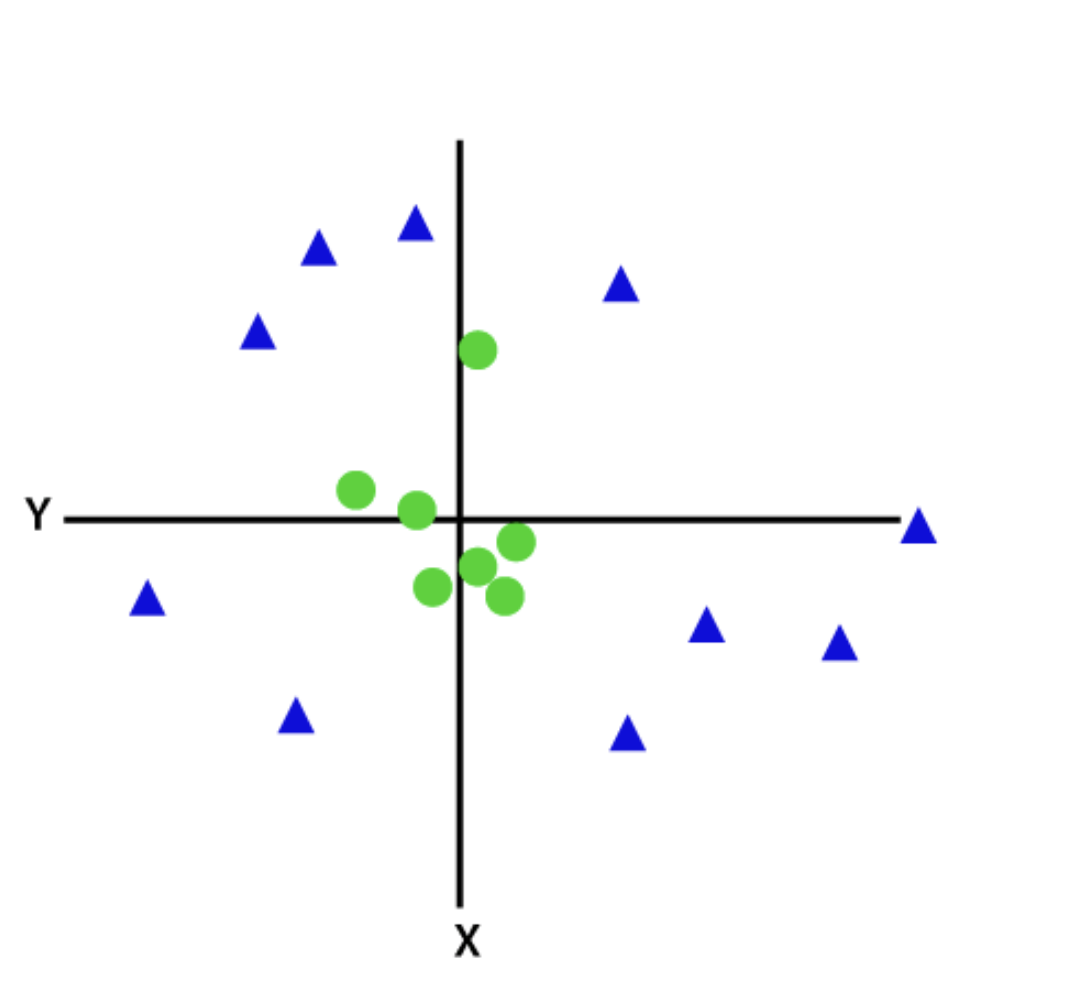
Fuente: Javatpoint
Después de la transformación, agregar un hiperplano que separe fácilmente las clases o categorías se vuelve fácil. Estas SVM se utilizan generalmente para problemas de optimización con varias variables.
La clave de las SVM no lineales es el truco del núcleo. Al aplicar diferentes funciones de núcleo como lineal, polinómica, función de base radial (RDF) o núcleo sigmoide, las SVM pueden manejar una amplia variedad de estructuras de datos. La elección del núcleo depende de las características de los datos y del problema que se está resolviendo.
¿Cómo funciona una máquina de vectores de soporte?
El algoritmo de máquina de vectores de soporte tiene como objetivo identificar un hiperplano para separar puntos de datos de diferentes clases. Fueron diseñados potencialmente para problemas de clasificación binaria, pero evolucionaron para resolver problemas de múltiples clases.
Basado en las características de los datos, las SVM emplean funciones de núcleo para transformar características de datos a dimensiones más altas, facilitando la adición de un hiperplano que separe diferentes clases de conjuntos de datos. Esto ocurre a través de la técnica del truco del núcleo, donde la transformación de datos se logra de manera eficiente y rentable.
Para entender cómo funcionan las SVM, debemos observar cómo se construye un clasificador SVM. Comienza dividiendo los datos. Divide tus datos en un conjunto de entrenamiento y un conjunto de prueba. Esto te ayudará a identificar valores atípicos o datos faltantes. Aunque no es técnicamente necesario, es una buena práctica.
A continuación, puedes importar un módulo SVM para cualquier biblioteca. Scikit-learn es una biblioteca popular de Python para máquinas de vectores de soporte. Ofrece una implementación efectiva de SVM para tareas de clasificación y regresión. Comienza entrenando tus muestras en el clasificador y prediciendo respuestas. Compara el conjunto de prueba y los datos predichos para comparar la precisión para la evaluación del rendimiento.
Hay otras métricas de evaluación que puedes usar, como:
- Puntuación F1 calcula cuántas veces un modelo hizo una predicción correcta en todo el conjunto de datos. Combina las puntuaciones de precisión y recuerdo de un modelo.
- Puntuación de precisión mide con qué frecuencia un modelo de aprendizaje automático predice correctamente la clase positiva.
- Recuerdo evalúa con qué frecuencia un modelo de ML identifica verdaderos positivos de todas las muestras positivas reales en el conjunto de datos.
Luego, puedes ajustar los hiperparámetros para mejorar el rendimiento de un modelo SVM. Obtienes los hiperparámetros iterando sobre diferentes núcleos, valores gamma y regularización, lo que te ayuda a localizar la combinación más óptima.
Aplicaciones de las máquinas de vectores de soporte
Las SVM encuentran aplicaciones en varios campos. Veamos algunos ejemplos de SVM aplicadas a problemas del mundo real.
- Estimación de la resistencia de la superficie del suelo: Calcular la licuefacción del suelo es crítico en el diseño de estructuras de ingeniería civil, especialmente en zonas propensas a terremotos. Las SVM ayudan a predecir si ocurre o no licuefacción en el suelo creando modelos que incluyen múltiples variables para evaluar la resistencia del suelo.
- Problema de sondeo geológico: Las SVM ayudan a rastrear la estructura en capas del planeta. Las propiedades de regularización de la formulación de vectores de soporte se aplican al problema inverso de sondeo geológico. Aquí, los resultados estiman las variables o parámetros que los produjeron. El proceso involucra funciones lineales y modelos algorítmicos de vectores de soporte que separan datos electromagnéticos.
- Detección de homología remota de proteínas: Los modelos SVM utilizan funciones de núcleo para detectar similitudes en secuencias de proteínas basadas en las secuencias de aminoácidos. Esto ayuda a categorizar proteínas en parámetros estructurales y funcionales, lo cual es importante en biología computacional.
- Detección facial y clasificación de expresiones: Las SVM clasifican estructuras faciales de las no faciales. Estos modelos analizan los píxeles y clasifican las características en faciales o no faciales. Al final, el proceso crea un límite de decisión cuadrado alrededor de la estructura facial basado en la intensidad de los píxeles.
- Categorización de texto y reconocimiento de escritura a mano: Aquí, cada documento lleva una puntuación comparada con un valor umbral, lo que facilita clasificarlo en la categoría relevante. Para reconocer la escritura a mano, los modelos SVM se entrenan primero con datos de entrenamiento sobre escritura a mano, y luego segregan la escritura humana y la de computadora basada en la puntuación.
- Detección de esteganografía: Las SVM ayudan a garantizar que las imágenes digitales no estén contaminadas o manipuladas por nadie. Separa cada píxel y los almacena en diferentes conjuntos de datos que las SVM analizan más tarde.
Resolviendo problemas de clasificación con precisión
Las máquinas de vectores de soporte ayudan a resolver problemas de clasificación mientras realizan predicciones precisas. Estos algoritmos pueden manejar fácilmente datos lineales y no lineales, lo que los hace adecuados para diversas aplicaciones, desde la clasificación de texto hasta el reconocimiento de imágenes.
Además, las SVM reducen el sobreajuste, que ocurre cuando el modelo aprende demasiado de los datos de entrenamiento, afectando su rendimiento en nuevos datos. Se centran en puntos de datos importantes, llamados vectores de soporte, ayudándoles a ofrecer resultados confiables y precisos.
Aprende más sobre modelos de aprendizaje automático y cómo entrenarlos.
Editado por Monishka Agrawal