

Keerthi Rangan
Keerthi Rangan is a Senior SEO Specialist with a sharp focus on the IT management software market. Formerly a Content Marketing Specialist at G2, Keerthi crafts content that not only simplifies complex IT concepts but also guides organizations toward transformative software solutions. With a background in Python development, she brings a unique blend of technical expertise and strategic insight to her work. Her interests span network automation, blockchain, infrastructure as code (IaC), SaaS, and beyond—always exploring how technology reshapes businesses and how people work. Keerthi’s approach is thoughtful and driven by a quiet curiosity, always seeking the deeper connections between technology, strategy, and growth.
Las interrupciones son implacables y ocurren con demasiada frecuencia.
Cuando suceden, generalmente es en los momentos más inesperados. Tal vez alguien tropieza con un cable de alimentación, ocurre un problema en la red o los ingenieros mueven un disco y se corrompe.
Sea lo que sea, la interrupción ocurre y nos apresuramos a analizar qué salió mal y a restablecer los servidores lo antes posible.
El tiempo de actividad es el rey. Aumentar el tiempo de inactividad del servicio puede afectar negativamente los ingresos, la confianza en la marca, la pérdida de datos y los rankings de búsqueda.
Una forma de manejar fallos repentinos es usar un componente de reserva o conmutación por error. La conmutación por error proporciona los medios para responder proactivamente en lugar de reactivamente cuando ocurren interrupciones inesperadas.
Con las organizaciones avanzando hacia la continuidad del negocio en la nube con software de recuperación ante desastres como servicio (DRaaS), es imperativo entender cómo la conmutación por error apoya las estrategias de recuperación ante desastres (DR) y los planes de continuidad del negocio.
¿Qué es la conmutación por error?
La conmutación por error es un modo operativo de respaldo en el que un sistema secundario asume las funciones del sistema primario cuando este último se vuelve inaccesible. La unidad de respaldo se activa automáticamente y sin problemas, con poca o ninguna interrupción del servicio para los usuarios. La conmutación por error se emplea generalmente para sistemas críticos y tolerantes a fallos.
La conmutación por error es una parte integral de DRaaS para la continuidad del negocio en la nube. El software DRaaS proporciona esta capacidad de conmutación por error al ofrecer una transferencia rápida de la carga de trabajo si un servicio falla.
La conmutación por error se implementa en sistemas críticos para la misión donde la integridad de los datos y el tiempo de actividad son vitales. En caso de fallo, un sistema o solución alternativa está inmediatamente listo para tomar el control con poca interrupción en la operación regular.
En resumen, la conmutación por error es crítica para mantenerte en línea y funcionando. Por ejemplo, durante una falla del centro de datos primario, la conmutación por error debe transferir el control de los sistemas críticos para la misión al centro de datos secundario con mínima interrupción de los servicios o pérdida de datos.
La conmutación por error puede ocurrir en cualquier parte de un sistema:
- Un disparador de hardware o software en una computadora personal o dispositivo móvil puede proteger el dispositivo cuando un componente, como una CPU o una celda de batería, falla.
- La conmutación por error puede aplicarse a cualquier componente de red individual o un sistema de componentes, como un canal de conexión, dispositivo de almacenamiento o servidor web, dentro de una red.
- La conmutación por error permite que muchos servidores locales o basados en la nube mantengan una conexión constante y segura con poca o ninguna interrupción del servicio mientras usan una base de datos o aplicación web alojada.
Las empresas establecen redundancia en un fallo inesperado utilizando una computadora, sistema o servidor de respaldo que siempre está listo para entrar en acción automáticamente.
Los diseñadores de sistemas implementan la funcionalidad de conmutación por error en servidores, soporte de base de datos de backend o redes que requieren disponibilidad constante y excelente confiabilidad. La conmutación por error puede:
- Proteger tu base de datos durante el mantenimiento o una interrupción del sistema. Por ejemplo, si el servidor primario en el sitio falla debido a un fallo de hardware, el servidor de respaldo (en el sitio o en la nube) puede rápidamente asumir las tareas de alojamiento sin intervención administrativa.
- Puede adaptarse a tus configuraciones específicas de hardware y red. Mientras se gestiona una base de datos, un administrador puede emplear no solo un sistema A o B de dos servidores funcionando en paralelo para protegerse mutuamente, sino también un servidor en la nube para proporcionar solución de problemas, mantenimiento y parcheo en el sitio, todo sin afectar la conectividad.
- Permitir que las operaciones de mantenimiento se ejecuten automáticamente sin supervisión. Un cambio automático durante las actualizaciones periódicas de software proporciona protección sin interrupciones contra los peligros de ciberseguridad.
¿Sabías que? Un cambio es esencialmente lo mismo que una conmutación por error; sin embargo, a diferencia de una conmutación por error, no es automatizado y requiere interacción humana. Las soluciones de conmutación por error automatizadas protegen la mayoría de los sistemas.
¿Por qué es importante la conmutación por error?
Simplemente tolerar o soportar el tiempo de inactividad o las interrupciones no es suficiente en el competitivo mercado global de hoy. Gracias a la conmutación por error y sus tecnologías, los clientes pueden estar seguros de que pueden confiar en una conexión segura sin interrupciones inesperadas.
La integración de la conmutación por error puede ser una carga no deseada y costosa, pero es una póliza de seguro vital que garantiza seguridad y protección.
Entonces, ¿cuál es la razón principal por la que una empresa tiene un sistema de conmutación por error? El objetivo principal de la conmutación por error es prevenir o reducir el fallo total del sistema. La conmutación por error es un componente esencial del plan de DR de cada empresa. Si la arquitectura de la red está configurada adecuadamente, la conmutación por error y la recuperación proporcionarán protección completa contra la mayoría, si no todas, las interrupciones del servicio.
Cualquier problema legítimo se debe principalmente a la cantidad de datos que se cambian, el ancho de banda disponible y cómo se mueven, reflejan o copian los datos al segundo sitio. La prioridad de un ingeniero de sistemas debe ser reducir la transferencia de datos mientras mejora la calidad de sincronización entre dos sitios.
Después de asegurar la calidad de la transmisión de datos, el siguiente problema es determinar cómo activar la conmutación por error mientras se minimiza el tiempo de cambio.
Los administradores de TI también pueden activar una conmutación por error para facilitar el mantenimiento y la actualización del sistema primario. Esto se conoce como una conmutación por error planificada.
¿Quieres aprender más sobre Soluciones de Recuperación ante Desastres como Servicio (DRaaS)? Explora los productos de Recuperación de Desastres como Servicio (DRaaS).
¿Cómo funciona la conmutación por error?
La conmutación por error implica la restauración de datos, configuraciones de aplicaciones y soporte de infraestructura a un componente del sistema en espera. Para el usuario final, la operación es sin problemas. El funcionamiento normal continúa a pesar de las interrupciones inevitables inducidas por fallos de equipo debido a la capacidad de conmutación por error automatizada.
Un sistema de conmutación por error requiere un enlace directo al sistema primario para funcionar con éxito. Esto se conoce como un "latido". El latido envía un pulso desde el sistema primario al sistema de conmutación por error cada pocos minutos. La solución de conmutación por error permanecerá inactiva mientras el pulso se mantenga estable.
Un sistema de latido es común en la automatización de conmutación por error. En su forma más básica, este método vincula dos sitios ya sea físicamente a través de un cable o de forma inalámbrica a través de una red. Cuando se interrumpe la regularidad del enlace de latido, el sistema de conmutación por error se activará y asumirá todas las funciones del sistema primario. Generalmente, puedes diseñar tus soluciones de conmutación por error para alertar inmediatamente a tu personal de TI de una falla para que puedan trabajar en restaurar el sistema primario lo más rápido posible.
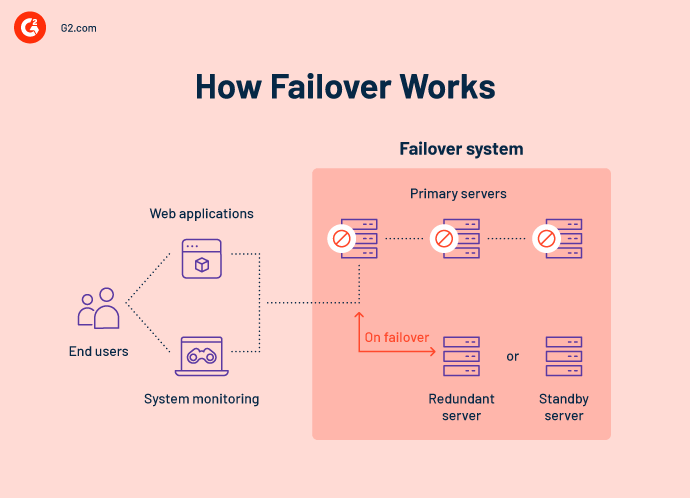
Dependiendo de la complejidad del servicio, un sistema puede incluso tener un tercer sitio ejecutando los componentes fundamentales necesarios para evitar el tiempo de inactividad al cambiar. Múltiples caminos, componentes redundantes y soporte remoto o basado en la nube proporcionan un camino seguro y siempre conectado.
La virtualización replica un entorno informático ejecutando software anfitrión en una máquina virtual. Por lo tanto, el mecanismo de conmutación por error puede ser independiente del hardware.
Este procedimiento generalmente se lleva a cabo mediante un software o hardware particular que permite esta función compleja. Las mejores soluciones ofrecen automatización y orquestación para facilitar los procesos de recuperación. Estos sistemas también pueden restaurar datos de momentos en lugar de horas o incluso días atrás.
La integridad del servicio es crítica para minimizar el tiempo de inactividad durante la conmutación por error. Necesitarás una solución DRaaS que conozca tus servicios y pueda restaurarlos como un todo (en lugar de simplemente los componentes), resultando en un retorno más rápido a las operaciones normales de TI.
¿Qué es un clúster de conmutación por error?
Un clúster de conmutación por error es una colección de servidores informáticos que trabajan juntos para ofrecer disponibilidad continua (CA), tolerancia a fallos (FT) o alta disponibilidad (HA). Las empresas pueden construir topologías de red de clústeres de conmutación por error completamente en hardware físico o incorporar máquinas virtuales (VMs).
Cuando uno de los servidores en un clúster de conmutación por error se descompone, se activa el mecanismo de conmutación por error. Esto reduce el tiempo de inactividad al transferir instantáneamente la carga de trabajo del elemento defectuoso a otro nodo en el clúster.
Disponibilidad continua vs. tolerancia a fallos vs. alta disponibilidad
- La disponibilidad continua es proactiva. Enfatiza la redundancia, la detección de fallos y la prevención de errores. Dichos sistemas permiten planificación de mantenimiento y actualizaciones durante el horario laboral regular sin interrumpir el servicio.
- Un sistema tolerante a fallos no tiene interrupción del servicio pero cuesta un poco más. Se basa en hardware dedicado que detecta un fallo y cambia instantáneamente a un componente de hardware redundante. Aunque la transición parece fluida y proporciona un servicio continuo, se paga un precio significativo por el costo y el rendimiento del hardware. Esto se debe a que los componentes redundantes no ejecutan ningún procesamiento. Más importante aún, el paradigma FT ignora los errores de software, la causa más común de tiempo de inactividad.
- Un sistema de alta disponibilidad (HA) causa una interrupción mínima del servicio. HA combina software con hardware estándar de la industria para reducir el tiempo de inactividad al restaurar servicios cuando los sistemas fallan. Dichos sistemas son una excelente solución para servicios que deben ser restaurados rápidamente y soportar una interrupción corta durante el fallo.
El propósito principal de un clúster de conmutación por error es proporcionar ya sea HA o CA para aplicaciones y servicios. Los clústeres CA, a menudo conocidos como clústeres tolerantes a fallos, reducen el tiempo de inactividad cuando un sistema primario falla, permitiendo que los usuarios finales continúen accediendo a servicios y aplicaciones sin interrupción.
Por otro lado, los clústeres HA proporcionan recuperación automatizada, poco tiempo de inactividad y cero pérdida de datos a pesar del riesgo de una ligera interrupción en la operación. La mayoría de las soluciones de clúster de conmutación por error proporcionan herramientas de gestión de clúster de conmutación por error que permiten a los administradores controlar el proceso.
Un clúster generalmente consiste en dos o más servidores o nodos que están comúnmente vinculados programáticamente y físicamente usando cables. Algunos sistemas de conmutación por error utilizan tecnologías de clúster adicionales, como balanceo de carga, procesamiento paralelo o concurrente y soluciones de almacenamiento.
¿Qué es la prueba de conmutación por error?
La prueba de conmutación por error confirma la capacidad de un sistema para dedicar recursos adecuados a la recuperación tras un fallo del sistema. En otras palabras, la prueba de conmutación por error evalúa la capacidad de conmutación por error del sistema. La prueba verificará si el sistema puede gestionar recursos adicionales y migrar actividades a sistemas de respaldo en caso de una terminación o fallo inesperado.
Por ejemplo, las pruebas de conmutación por error y recuperación verifican la capacidad del sistema para gestionar y alimentar una CPU adicional o muchos servidores una vez que alcanza un umbral de rendimiento que se supera con frecuencia durante fallos significativos. Esto subraya el vínculo crítico entre la prueba de conmutación por error, la resiliencia y la seguridad.
La prueba de conmutación por error es el proceso de simular un fallo en un servidor o sistema primario para evaluar la efectividad de sus mecanismos de conmutación por error. Los aspectos clave incluyen:
- Propósito: Verificar que los sistemas de respaldo puedan asumir sin problemas durante fallos inesperados.
- Escenarios: Implica probar varios escenarios de fallo como caídas de servidores o interrupciones de red.
- Automatizado vs. manual: Esto se puede hacer manualmente o con herramientas automatizadas.
- Objetivo de tiempo de recuperación (RTO): Mide qué tan rápido se recupera el sistema
- Integridad de los datos: Asegura que los datos permanezcan intactos durante el proceso de conmutación por error.
Tipos de configuraciones de conmutación por error
La técnica del sistema de conmutación por error utiliza tecnologías de clúster existentes para permitir ejecuciones redundantes, aumentando la confiabilidad y accesibilidad de los recursos de TI.
Existen dos configuraciones básicas para sistemas de conmutación por error de alta disponibilidad: activa-activa y activa-pasiva. Aunque ambas técnicas de implementación mejoran la confiabilidad, logran la conmutación por error de diferentes maneras.
1. Configuración activa-activa
Una configuración de alta disponibilidad activa-activa generalmente consiste en al menos dos nodos que están ejecutando activamente y simultáneamente el mismo tipo de servicio. El clúster activa-activa realiza balanceo de carga distribuyendo las cargas de trabajo uniformemente entre todos los nodos, limitando que cualquier nodo se sobrecargue. A medida que hay más nodos disponibles, los tiempos de respuesta y rendimiento mejoran.
Las configuraciones y especificaciones de nodos individuales deben ser idénticas para asegurar que el clúster HA funcione sin problemas y logre redundancia. Los balanceadores de carga asignan usuarios a nodos del clúster basándose en un algoritmo. Por ejemplo, un algoritmo de round-robin distribuye uniformemente a los usuarios a los servidores basándose en cuándo se unen.
El uso de ambos nodos se divide aproximadamente 50/50, aunque cada nodo puede gestionar toda la carga de forma independiente. Sin embargo, si un nodo de configuración activa-activa maneja rutinariamente más de la mitad de la carga, la pérdida de nodo podría causar una disminución en el rendimiento.
Dado que ambos caminos están activos, el tiempo de interrupción durante un fallo es casi insignificante con un sistema HA activa-activa.
2. Configuración activa-pasiva
En una configuración activa-pasiva, también conocida como configuración de espera activa, hay al menos dos nodos, pero no todos están activos. En una configuración de dos nodos, el primer nodo está operativo y el segundo nodo permanece pasivo o en espera como el sistema de conmutación por error.
Este estado operativo de espera puede ser respaldado si el nodo primario en vivo falla. Por otro lado, los usuarios solo se conectan al servidor activo hasta que hay un fallo. El nodo inactivo se activa para asumir el procesamiento de un recurso de TI fuera de línea, y la carga de trabajo relacionada se dirige al nodo secundario, que asume la operación.
El tiempo de interrupción es más largo en una configuración activa-pasiva porque el sistema debe moverse de un nodo a otro.
Conmutación por error vs. recuperación
La conmutación por error y la recuperación son elementos de continuidad del negocio que permiten que las operaciones digitales regulares continúen incluso si el sitio de producción primario no está disponible. Considera los procedimientos de conmutación por error y recuperación como vitales para un marco sólido de recuperación ante desastres.
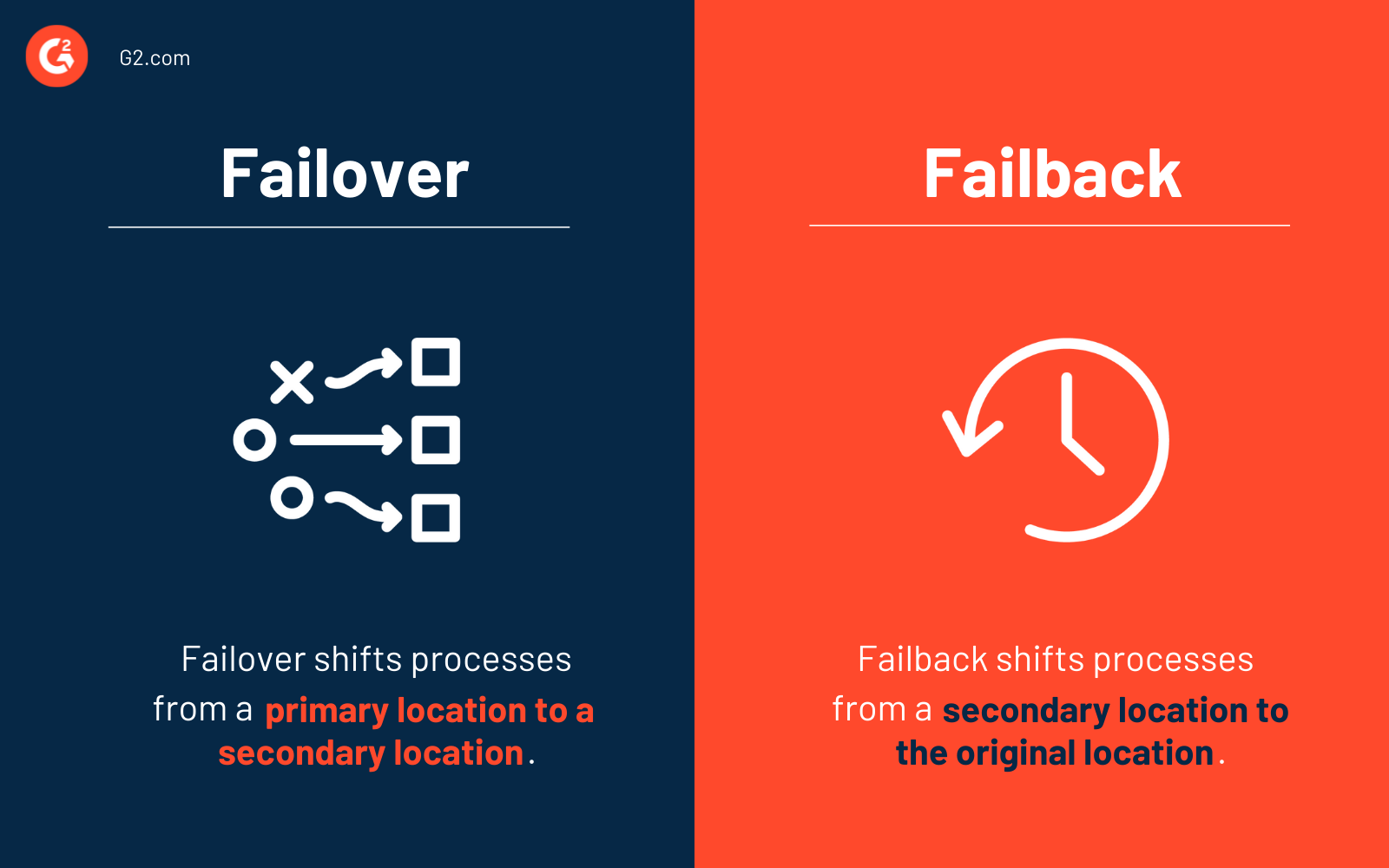
El proceso de conmutación por error desplaza la producción del sitio primario a una ubicación secundaria. Este sitio de recuperación generalmente contiene una copia replicada de todos los sistemas y datos de tu sitio de producción primario. Durante una conmutación por error, todas las actualizaciones se almacenan virtualmente.
La recuperación es una medida de continuidad del negocio desplegada cuando el sitio de producción primario vuelve a estar en funcionamiento después de que se aborda un desastre (o un evento programado). La producción se restaura a su antiguo (o nuevo) sitio durante una recuperación, y cualquier modificación registrada en el almacenamiento virtual se sincroniza.
Beneficios de la conmutación por error
Para las empresas centradas en la web, el tiempo de actividad del servicio es crítico para la misión, ya que impacta todas las operaciones. Desde el crecimiento organizacional hasta la retención de clientes y las relaciones, la alta disponibilidad es el criterio esencial que las empresas no pueden ignorar. Los beneficios de los sistemas de conmutación por error incluyen:
- Protección contra el tiempo de inactividad: Implementar sistemas de conmutación por error efectivos para componentes críticos de la pila de TI de una organización debería disminuir significativamente el tiempo de inactividad causado por interrupciones del servicio. Si incluso uno de los componentes críticos del sistema falla, evitará el funcionamiento adecuado de cada componente que interactúa con él.
- Previene la pérdida de ingresos: Si una herramienta comercial vital, como tu servicio de procesamiento de pagos, no está disponible durante mucho tiempo, la rentabilidad de tu organización sufrirá. Dado que las acciones de los consumidores son volátiles, incluso una mala experiencia puede hacer que los clientes dejen de usar tu empresa permanentemente.
Desafíos de la conmutación por error
Con demasiada frecuencia, la conmutación por error es una idea tardía o un último recurso. Sin embargo, al planificar y probar los procedimientos de conmutación por error de antemano, los gerentes de TI pueden prevenir el tiempo de inactividad y lograr niveles consistentes de calidad del servicio, especialmente cuando ocurre lo inesperado.
Un proceso de conmutación por error bien engrasado viene con altos costos y puede aumentar la probabilidad de error humano en caso de fallos. Sin embargo, implementar procedimientos efectivos puede reducir el riesgo de pérdida en sistemas críticos y minimizar posibles interrupciones en la calidad del servicio.
Aunque la conmutación por error parece un salvador en todo su esplendor, implementar una estrategia de conmutación por error viene con desafíos significativos.
Costo incrementado
Configurar, mantener y monitorear una estrategia de conmutación por error confiable y protegida es costoso. Esto es especialmente cierto si deseas asegurarte de que cada componente de un paisaje complejo e interconectado tenga su propio mecanismo de conmutación por error.
Para construir sistemas de conmutación por error confiables que funcionen automáticamente con poco tiempo de inactividad, debes invertir dinero en sistemas de alto ancho de banda que puedan manejar intercambios de datos sincrónicos. La mayoría de los gastos totales de línea para sistemas de conmutación por error pueden atribuirse a depender de la experiencia de terceros para instalar y administrar los sistemas.
Procesos largos de gestión del sistema y aseguramiento de calidad (QA)
Un sistema de conmutación por error necesita el mismo mantenimiento y validación de QA que los sistemas primarios para proteger efectivamente la tecnología de tu organización. Ejecutar tus sistemas primarios y de conmutación por error en versiones separadas anula tener sistemas idénticos y sincronizados en primer lugar, requiriendo más esfuerzo durante períodos de mantenimiento ajustados.
También debes asegurarte de que tus sistemas de conmutación por error puedan interactuar y comprometerse frecuentemente con los diversos componentes del entorno. Estas validaciones pueden aumentar sustancialmente el tiempo asignado por tu personal de TI para pruebas y QA.
Casos de uso de la conmutación por error
La conmutación por error puede ocurrir en cualquier parte de un sistema, incluyendo una computadora, una red, un dispositivo de almacenamiento o un servidor web. Aquí hay algunas formas en que la conmutación por error puede ayudar a las organizaciones a crear una infraestructura resiliente.
- La conmutación por error del servidor de aplicaciones protege numerosos servidores que ejecutan aplicaciones. Estos servidores de conmutación por error idealmente deberían ejecutarse en hosts separados y todos deberían tener nombres de dominio distintos.
- La conmutación por error del sistema de nombres de dominio (DNS) asegura que los servicios de red o sitios web permanezcan disponibles durante una interrupción. Genera un registro DNS para un sistema que incluye dos o más direcciones IP o conexiones de conmutación por error. Esto permite a los usuarios redirigir el tráfico de un sistema fallido hacia un sitio redundante en vivo.
- La conmutación por error del protocolo de configuración dinámica de host (DHCP) despliega dos o más servidores DHCP para manejar el mismo grupo de direcciones. Esto permite que cada servidor DHCP respalde al otro en caso de una pérdida de red. Comparten la responsabilidad de la asignación de arrendamiento para ese grupo en todo momento.
- La conmutación por error del servidor SQL elimina cualquier posible punto único de fallo al emplear almacenamiento de datos compartido y numerosas conexiones de red a través de un almacenamiento conectado a la red (NAS).
Conmutación por error con gracia
Aunque la integración de la conmutación por error puede ser costosa, considera el enorme costo del tiempo de inactividad. Piensa en la conmutación por error como una póliza de seguro esencial de seguridad y protección.
La conmutación por error debe ser un componente clave de tu estrategia de recuperación ante desastres. Tu prioridad debe ser limitar las transferencias de datos para evitar cuellos de botella mientras mantienes una sincronización de alta calidad entre los sistemas primarios y de respaldo desde un enfoque de ingeniería de sistemas.
Descubre cómo crear un plan de recuperación ante desastres robusto que proteja tus operaciones y proteja tus valiosos activos.
Este artículo fue publicado originalmente en 2022. Ha sido actualizado con nueva información.