

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.
Stellen Sie sich eine Welt vor, in der Computer selbstständig lernen und sich anpassen können. Nicht mehr nur auf das beschränkt, was wir ihnen programmieren, werden Maschinen in der Lage sein, zu verstehen, zu analysieren und sogar vorherzusagen, wie Menschen sich verhalten. Dies ist nicht nur ein Traum; es ist eine Realität, auf die wir uns schnell zubewegen.
In der heutigen informationsreichen Welt kann die Menge an Daten überwältigend sein. Während es einfach ist, Daten zu sammeln, besteht die eigentliche Herausforderung darin, nützliche Erkenntnisse aus all diesen Informationen zu gewinnen. Hier kommt das maschinelle Lernen ins Spiel.
Was ist maschinelles Lernen?
Maschinelles Lernen ist ein Teil der künstlichen Intelligenz, der sich auf die Erstellung von Algorithmen konzentriert, die aus Daten lernen können. Durch die Nutzung vergangener Daten können sie zukünftige Ergebnisse vorhersagen und Maschinen eine intelligentere Möglichkeit bieten, große Mengen an Informationen zu analysieren und versteckte Verbindungen aufzudecken, die Menschen möglicherweise übersehen.
Verschiedene Werkzeuge für maschinelles Lernen helfen Entwicklern, intelligente Systeme zu erstellen und bereitzustellen. Diese Werkzeuge ermöglichen es Unternehmen, vorherzusagen, welche Produkte Kunden am wahrscheinlichsten kaufen und welche Online-Inhalte sie genießen werden.
Eine häufige Anwendung des maschinellen Lernens sind Empfehlungssysteme. Große Unternehmen wie Google, Netflix und Amazon nutzen diese Systeme, um zu lernen, was Nutzer bevorzugen, und ihnen personalisierte Produkt- und Dienstleistungsvorschläge zu unterbreiten.
Geschichte des maschinellen Lernens
Maschinelles Lernen gibt es schon seit einiger Zeit, und es zeigt sich in der Art und Weise, wie wir heute von Computern sprechen – "Maschinen" ist ein Begriff, der weniger gebräuchlich geworden ist.
Im Folgenden finden Sie einen kurzen Überblick über die Entwicklung des maschinellen Lernens, der seine Reise von der Entstehung bis zur weit verbreiteten Anwendung nachzeichnet.
- Vor den 1920er Jahren: Thomas Bayes, Andrey Markov, Adrien-Marie Legendre und andere angesehene Mathematiker legen das notwendige Fundament für die grundlegenden Techniken des maschinellen Lernens.
- 1943: Das erste mathematische Modell von neuronalen Netzwerken wird in einem wissenschaftlichen Artikel von Walter Pitts und Warren McCulloch vorgestellt.
- 1949: "The Organization of Behavior", ein Buch von Donald Hebb, wird veröffentlicht. Dieses Buch untersucht, wie Verhalten mit Gehirnaktivität und neuronalen Netzwerken zusammenhängt.
- 1950: Alan Turing versucht, KI zu beschreiben und stellt die Frage, ob Maschinen die Fähigkeit zum Lernen haben.
- 1951: Marvin Minsky und Dean Edmonds bauen das allererste künstliche neuronale Netzwerk.
- 1956: John McCarthy, Marvin Minsky, Nathaniel Rochester und Claude Shannon organisieren den Dartmouth Workshop. Die Veranstaltung wird oft als "Geburtsort der KI" bezeichnet, und der Begriff künstliche Intelligenz wurde bei derselben Veranstaltung geprägt.
Hinweis: Arthur Samuel gilt als der Vater des maschinellen Lernens, da er den Begriff 1959 prägte.
- 1965: Alexey (Oleksii) Ivakhnenko und Valentin Lapa entwickelten den ersten mehrschichtigen Perzeptron. Ivakhnenko wird oft als Vater des Deep Learning (DL) angesehen.
- 1967: Der nächste Nachbar-Algorithmus wird konzipiert.
- 1979: Der Informatiker Kunihiko Fukushima veröffentlichte seine Arbeit über Neocognitron: ein hierarchisches mehrschichtiges Netzwerk zur Mustererkennung. Neocognitron inspirierte auch die Entwicklung von Convolutional Neural Networks (CNNs).
- 1985: Terrence Sejnowski erfindet NETtalk. Dieses Programm lernt, (englische) Wörter auf die gleiche Weise auszusprechen wie Babys.
- 1995: Tin Kam Ho führt Random Decision Forests in einem Artikel ein.
- 1997: Deep Blue, der IBM-Schachcomputer, besiegt Garry Kasparov, den Weltmeister im Schach.
- 2000: Der Begriff Deep Learning wird erstmals vom Forscher für neuronale Netzwerke Igor Aizenberg erwähnt.
- 2009: Fei-Fei Li startet ImageNet, eine große Bilddatenbank, die intensiv für die Forschung zur visuellen Objekterkennung genutzt wird.
- 2011: Googles X Lab entwickelt Google Brain, einen Algorithmus für künstliche Intelligenz. Später im Jahr besiegt IBM Watson menschliche Konkurrenten in der Quizshow Jeopardy!.
- 2014: Ian Goodfellow und seine Kollegen entwickeln ein generatives gegnerisches Netzwerk (GAN). Im selben Jahr entwickelt Facebook DeepFace, ein Deep-Learning-Gesichtserkennungssystem, das menschliche Gesichter in Bildern mit einer Genauigkeit von fast 97,25 % erkennen kann. Später stellt Google der Öffentlichkeit ein groß angelegtes maschinelles Lernsystem namens Sibyl vor.
- 2015: AlphaGo wird die erste KI, die einen professionellen Spieler im Go besiegt.
- 2020: Open AI kündigt GPT-3 an, einen leistungsstarken Algorithmus zur Verarbeitung natürlicher Sprache mit der Fähigkeit, menschenähnlichen Text zu generieren.
Möchten Sie mehr über Maschinelles Lernsoftware erfahren? Erkunden Sie Maschinelles Lernen Produkte.
Maschinelles Lernen vs. Deep Learning
Obwohl sowohl maschinelles Lernen als auch Deep Learning Teilbereiche der künstlichen Intelligenz sind, unterscheiden sie sich in ihrem Umfang und ihrer Komplexität.
ML umfasst das Training von Modellen mit Daten, um Vorhersagen oder Entscheidungen zu treffen, indem verschiedene Techniken wie Entscheidungsbäume, Support Vector Machines und k-nächste Nachbarn verwendet werden. In diesem Ansatz ist oft menschliches Eingreifen erforderlich, um relevante Merkmale zu identifizieren und sicherzustellen, dass sich die Modelle im Laufe der Zeit verbessern, ein Konzept, das allgemein als Human-in-the-Loop bekannt ist.
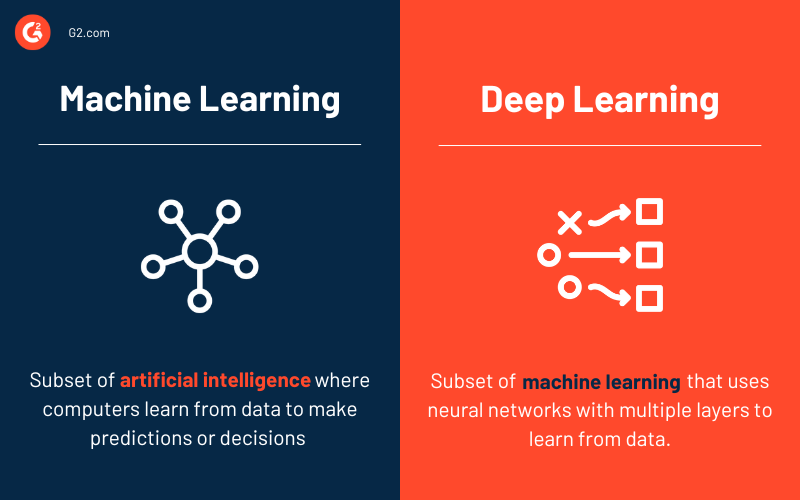
Im Gegensatz dazu ist DL ein fortgeschrittenerer Teilbereich von ML, der künstliche neuronale Netzwerke nutzt, die vom menschlichen Gehirn inspiriert sind und aus Schichten miteinander verbundener Knoten (Neuronen) bestehen. DL-Modelle sind hervorragend in der Verarbeitung großer Datenmengen und können automatisch wichtige Merkmale ohne menschliche Anleitung identifizieren.
Zum Beispiel kann Deep Learning bei Bildverarbeitung-Aufgaben eigenständig Kanten, Formen und komplexe Objekte erkennen, während traditionelle ML-Methoden normalerweise erfordern, dass Menschen diese Merkmale im Voraus spezifizieren.
Wie maschinelles Lernen funktioniert
Im Kern analysieren und identifizieren maschinelle Lernalgorithmen Muster aus Datensätzen und nutzen diese Informationen, um verbesserte Vorhersagen über neue, unbekannte Daten zu treffen. Dieser Prozess spiegelt wider, wie Menschen lernen und sich verbessern. Wenn wir Entscheidungen treffen, verlassen wir uns oft auf vergangene Erfahrungen, um neue Situationen besser einschätzen zu können. Ähnlich untersucht ein maschinelles Lernmodell historische Daten, um fundierte Vorhersagen oder Entscheidungen zu treffen.
Um das Konzept zu vereinfachen, stellen Sie sich vor, Sie spielen das Dinosaurierspiel in Google Chrome (das erscheint, wenn es kein Internet gibt). Die Herausforderung besteht darin, über Kakteen zu springen oder unter Vögeln hindurchzutauchen. Ein Mensch lernt dies durch Versuch und Irrtum und erkennt schnell, dass man Hindernisse vermeiden muss, um im Spiel zu bleiben.
Eine Anwendung des maschinellen Lernens würde auf ähnliche Weise lernen. Ein Entwickler könnte die Anwendung so programmieren, dass sie springt, wann immer der T-Rex auf einen dichten Bereich dunkler Pixel trifft, wobei die Erfolgsrate dieser Aktion im Laufe der Zeit zunimmt. Durch das Aufeinandertreffen mit mehr Hindernissen und die Anpassung basierend auf den Ergebnissen könnte die KI ihre Vorhersagen darüber verfeinern, wann sie springen oder ducken sollte.
Nehmen wir ein weiteres Beispiel:
Betrachten Sie diese Sequenz:
3 → 9
4 → 16
5 → 25
Wenn Sie gefragt würden, welche Zahl mit 6 gepaart ist, würden Sie wahrscheinlich 36 sagen. Sie haben dies getan, indem Sie ein Muster erkannt haben (jede Zahl wird quadriert). Ein maschinelles Lernmodell arbeitet auf die gleiche Weise – es analysiert frühere Daten, um Vorhersagen basierend auf Mustern zu treffen.
Im Wesentlichen ist maschinelles Lernen reine Mathematik. Jeder Algorithmus des maschinellen Lernens basiert auf mathematischen Funktionen, die beim Lernen angepasst werden. Das bedeutet, dass der Lernprozess selbst in der Mathematik verwurzelt ist – Daten in umsetzbare Erkenntnisse zu verwandeln.
4 Methoden des maschinellen Lernens
Es gibt zahlreiche Methoden des maschinellen Lernens, durch die KI-Systeme aus Daten lernen können. Diese Methoden werden basierend auf der Art der Daten (beschriftet oder unbeschriftet) und den erwarteten Ergebnissen kategorisiert. Im Allgemeinen gibt es vier Arten des maschinellen Lernens: überwacht, unüberwacht, halbüberwacht und verstärkendes Lernen
1. Überwachtes Lernen
Überwachtes Lernen ist ein Ansatz des maschinellen Lernens, bei dem ein Datenwissenschaftler wie ein Tutor agiert und das KI-System trainiert, indem er grundlegende Regeln und beschriftete Datensätze bereitstellt. Die Datensätze enthalten beschriftete Eingabedaten und erwartete Ausgaberesultate. In dieser Methode des maschinellen Lernens wird dem System explizit gesagt, wonach es in den Eingabedaten suchen soll.
Einfacher ausgedrückt, lernen überwachte Lernalgorithmen durch Beispiele. Solche Beispiele werden zusammenfassend als Trainingsdaten bezeichnet. Sobald ein maschinelles Lernmodell mit dem Trainingsdatensatz trainiert wurde, werden die Testdaten bereitgestellt, um die Genauigkeit des Modells zu bestimmen.
Überwachtes Lernen kann weiter in zwei Typen unterteilt werden: Klassifikation und Regression.
2. Unüberwachtes Lernen
Unüberwachtes Lernen ist eine Technik des maschinellen Lernens, bei der der Datenwissenschaftler das KI-System durch Beobachtung lernen lässt. Der Trainingsdatensatz enthält nur die Eingabedaten und keine entsprechenden Ausgabedaten.
Im Gegensatz zum überwachten Lernen erfordert unüberwachtes Lernen große Mengen unbeschrifteter Daten, um zu beobachten, Muster zu finden und zu lernen. Unüberwachtes Lernen könnte ein Ziel an sich sein, zum Beispiel das Entdecken versteckter Muster in Datensätzen oder eine Methode zum Merkmalslernen.
Unüberwachte Lernprobleme werden im Allgemeinen in Clustering und Assoziationsprobleme unterteilt.
3. Halbüberwachtes Lernen
Halbüberwachtes Lernen ist eine Mischung aus überwachtem und unüberwachtem Lernen. In diesem Prozess des maschinellen Lernens trainiert der Datenwissenschaftler das System nur ein wenig, damit es einen Überblick auf hoher Ebene erhält.
Außerdem wird ein kleiner Prozentsatz der Trainingsdaten beschriftet sein, während der Rest unbeschriftet bleibt. Im Gegensatz zum überwachten Lernen erfordert diese Lernmethode, dass das System die Regeln und Strategien durch Beobachtung von Mustern im Datensatz lernt.
Halbüberwachtes Lernen ist nützlich, wenn Sie nicht genügend beschriftete Daten haben oder der Beschriftungsprozess teuer ist, aber dennoch ein genaues maschinelles Lernmodell erstellen möchten.
4. Verstärkendes Lernen
Verstärkendes Lernen (RL) ist eine Lerntechnik, die es einem KI-System ermöglicht, in einer interaktiven Umgebung zu lernen. Ein Programmierer verwendet einen Belohnungs-Bestrafungs-Ansatz, um das System zu lehren, indem es durch Versuch und Irrtum lernt und Feedback aus seinen eigenen Aktionen erhält.
Einfach ausgedrückt, steht das KI-System im verstärkenden Lernen vor einer spielähnlichen Situation, in der es die Belohnung maximieren muss.
Obwohl der Programmierer die Spielregeln definiert, gibt die Person keine Hinweise darauf, wie das Spiel gelöst oder gewonnen werden kann. Das System muss seinen Weg finden, indem es zahlreiche zufällige Versuche durchführt und aus jedem Schritt lernt, sich zu verbessern.
Anwendungsfälle des maschinellen Lernens
Projekte des maschinellen Lernens haben nahezu jede Branche revolutioniert, die eine digitale Transformation durchlaufen hat. Hier sind nur einige der vielen wirkungsvollen Anwendungsfälle von Projekten des maschinellen Lernens in verschiedenen Sektoren.
Bilderkennung
Maschinen werden immer besser darin, Bilder zu verarbeiten. Tatsächlich sind Modelle des maschinellen Lernens besser und schneller darin, Bilder zu erkennen und zu klassifizieren als Menschen.
Diese Anwendung des maschinellen Lernens wird als Bilderkennung oder Computer Vision bezeichnet. Sie wird von Deep-Learning-Algorithmen angetrieben und verwendet Bilder als Eingabedaten. Sie haben diese Leistung wahrscheinlich in Aktion gesehen, wenn Sie ein Foto auf Facebook hochgeladen haben und die App vorschlug, Ihre Freunde zu markieren, indem sie ihre Gesichter erkannte.
Customer Relationship Management (CRM) Software
Maschinelles Lernen ermöglicht CRM-Software Anwendungen, die "Warum"-Fragen zu entschlüsseln.
Warum übertrifft ein bestimmtes Produkt die anderen? Warum führen Kunden eine bestimmte Aktion auf der Website aus? Warum sind Kunden mit einem Produkt nicht zufrieden?
Durch die Analyse historischer Daten, die von CRM-Anwendungen gesammelt wurden, können Modelle des maschinellen Lernens helfen, bessere Verkaufsstrategien zu entwickeln und sogar aufkommende Markttrends vorherzusagen. ML kann auch Wege finden, um Abwanderungsraten zu reduzieren, den Kundenlebenszeitwert zu verbessern und Unternehmen einen Schritt voraus zu halten.
Zusammen mit Datenanalyse, Marketingautomatisierung und prädiktiver Analyse ermöglicht maschinelles Lernen Unternehmen, rund um die Uhr verfügbar zu sein, indem es als Chatbots verkörpert wird.
Patientendiagnose
Es ist sicher zu sagen, dass Papierakten der Vergangenheit angehören. Viele Krankenhäuser und Kliniken haben jetzt elektronische Gesundheitsakten (EHRs) eingeführt, die die Speicherung von Patienteninformationen sicherer und effizienter machen.
Da EHRs Patienteninformationen in ein digitales Format umwandeln, kann die Gesundheitsbranche maschinelles Lernen implementieren und mühsame Prozesse beseitigen. Dies bedeutet auch, dass Ärzte Patientendaten in Echtzeit analysieren und sogar die Möglichkeit von Krankheitsausbrüchen vorhersagen können.
Zusammen mit der Verbesserung der Genauigkeit medizinischer Diagnosen können Algorithmen des maschinellen Lernens Ärzten helfen, Brustkrebs zu erkennen und die Fortschrittsrate einer Krankheit vorherzusagen.
Bestandsoptimierung
Wenn ein bestimmtes Material im Übermaß gelagert wird, kann es ungenutzt bleiben, bevor es verdirbt. Andererseits, wenn es einen Mangel gibt, wird die Lieferkette beeinträchtigt. Der Schlüssel liegt darin, den Bestand zu halten, indem die Produktnachfrage berücksichtigt wird.
Die Nachfrage nach einem Produkt kann basierend auf historischen Daten vorhergesagt werden. Zum Beispiel wird Eiscreme häufiger während der Sommersaison verkauft (obwohl nicht immer und überall). Es gibt jedoch zahlreiche andere Faktoren, die die Nachfrage beeinflussen, einschließlich des Wochentags, der Temperatur, bevorstehender Feiertage und mehr.
Das Berechnen solcher Mikro- und Makrofaktoren ist für Menschen praktisch unmöglich. Nicht überraschend ist die Verarbeitung solcher großen Datenmengen eine Spezialität von Anwendungen des maschinellen Lernens.
Zum Beispiel fand IBM Watson durch die Nutzung der enormen Datenbank von The Weather Company heraus, dass der Joghurtverkauf steigt, wenn der Wind überdurchschnittlich ist, und der Autogasverkauf steigt, wenn die Temperatur kälter als der Durchschnitt ist.
Darüber hinaus wären selbstfahrende Autos, Nachfrageprognosen, Spracherkennung, Empfehlungssysteme und Anomalieerkennung ohne maschinelles Lernen nicht möglich gewesen.
Wie man ein Modell des maschinellen Lernens erstellt
Ein Modell des maschinellen Lernens zu erstellen, ist wie die Entwicklung eines Produkts. Es gibt eine Ideenfindungs-, Validierungs- und Testphase, um nur einige Prozesse zu nennen. Im Allgemeinen kann der Aufbau eines Modells des maschinellen Lernens in fünf Schritte unterteilt werden.
Sammlung und Vorbereitung des Trainingsdatensatzes
Im Bereich des maschinellen Lernens ist nichts wichtiger als qualitativ hochwertige Trainingsdaten.
Wie bereits erwähnt, ist der Trainingsdatensatz eine Sammlung von Datenpunkten. Diese Datenpunkte helfen dem Modell zu verstehen, wie es das Problem angehen soll, das es lösen soll. Typischerweise enthält der Trainingsdatensatz Bilder, Text, Video oder Audio.
Der Trainingsdatensatz ist ähnlich wie ein Mathematikbuch mit Beispielaufgaben. Je mehr Beispiele, desto besser. Neben der Quantität spielt auch die Qualität des Datensatzes eine Rolle, da das Modell hochgenau sein muss. Der Trainingsdatensatz muss auch die realen Bedingungen widerspiegeln, unter denen das Modell verwendet wird.
Der Trainingsdatensatz kann vollständig beschriftet, unbeschriftet oder teilweise beschriftet sein. Wie bereits erwähnt, hängt die Art des Datensatzes von der gewählten Methode des maschinellen Lernens ab.
In jedem Fall muss der Trainingsdatensatz frei von doppelten Daten sein. Ein qualitativ hochwertiger Datensatz durchläuft zahlreiche Reinigungsprozesse und enthält alle wesentlichen Attribute, die das Modell lernen soll.
Behalten Sie immer diesen Satz im Hinterkopf: Müll rein, Müll raus.
Wählen Sie einen Algorithmus
Ein Algorithmus ist ein Verfahren oder eine Methode zur Lösung eines Problems. In der Sprache des maschinellen Lernens ist ein Algorithmus ein Verfahren, das auf Daten angewendet wird, um ein Modell des maschinellen Lernens zu erstellen. Lineare Regression, logistische Regression, k-nächste Nachbarn (KNN) und Naive Bayes sind einige der beliebten Algorithmen des maschinellen Lernens.
Die Wahl eines Algorithmus hängt von dem Problem ab, das Sie lösen möchten, der Art der Daten (beschriftet oder unbeschriftet) und der verfügbaren Datenmenge.
Wenn Sie beschriftete Daten verwenden, können Sie die folgenden Algorithmen in Betracht ziehen:
- Entscheidungsbäume
- Lineare Regression
- Logistische Regression
- Support Vector Machine (SVM)
- Random Forest
Wenn Sie unbeschriftete Daten verwenden, können Sie die folgenden Algorithmen in Betracht ziehen:
- K-means Clustering Algorithmus
- Apriori-Algorithmus
- Singulärwertzerlegung
- Neuronale Netzwerke
Außerdem, wenn Sie das Modell trainieren möchten, um Vorhersagen zu treffen, wählen Sie überwacht. Wenn Sie das Modell trainieren möchten, um Muster zu finden oder Daten in Cluster zu unterteilen, wählen Sie unüberwacht.
Trainieren Sie den Algorithmus
In dieser Phase durchläuft der Algorithmus zahlreiche Iterationen. Nach jeder Iteration werden die Gewichte und Verzerrungen innerhalb des Algorithmus angepasst, indem die Ausgabe mit den erwarteten Ergebnissen verglichen wird. Der Prozess wird fortgesetzt, bis der Algorithmus genau wird, was das Modell des maschinellen Lernens ist.
Validieren Sie das Modell
Für viele ist der Validierungsdatensatz gleichbedeutend mit dem Testdatensatz. Kurz gesagt, es handelt sich um einen Datensatz, der während der Trainingsphase nicht verwendet wurde und dem Modell zum ersten Mal vorgestellt wird. Der Validierungsdatensatz ist entscheidend für die Bewertung der Genauigkeit des Modells und das Verständnis, ob es unter Overfitting leidet, einer falschen Optimierung eines Modells, wenn es zu stark auf seinen Trainingsdatensatz abgestimmt wird.
Wenn die Genauigkeit des Modells weniger als oder gleich 50 % beträgt, ist es unwahrscheinlich, dass es für reale Anwendungen nützlich ist. Idealerweise sollte das Modell eine Genauigkeit von 90 % oder mehr haben.
Testen Sie das Modell
Sobald das Modell trainiert und validiert ist, muss es mit realen Daten getestet werden, um seine Genauigkeit zu überprüfen. Dieser Schritt könnte den Datenwissenschaftler ins Schwitzen bringen, da das Modell auf einem größeren Datensatz getestet wird, anders als in der Trainings- oder Validierungsphase.
In einfacheren Worten, die Testphase lässt Sie überprüfen, wie gut das Modell gelernt hat, die spezifische Aufgabe auszuführen. Es ist auch die Phase, in der Sie feststellen können, ob das Modell auf einem größeren Datensatz funktioniert.
Das Modell wird im Laufe der Zeit und mit dem Zugang zu neueren Datensätzen besser. Zum Beispiel wird der Spam-Filter Ihres E-Mail-Posteingangs periodisch besser, wenn Sie bestimmte Nachrichten als Spam und falsch-positive Nachrichten als nicht Spam melden.
Beste Software für maschinelles Lernen
Wie bereits erwähnt, sind Algorithmen des maschinellen Lernens in der Lage, Vorhersagen oder Entscheidungen basierend auf Daten zu treffen. Diese Algorithmen verleihen Anwendungen die Fähigkeit, Automatisierungs- und KI-Funktionen anzubieten. Interessanterweise sind sich die meisten Endbenutzer der Verwendung von Algorithmen des maschinellen Lernens in solchen intelligenten Anwendungen nicht bewusst.
Um in die Kategorie des maschinellen Lernens aufgenommen zu werden, muss ein Produkt:
- Ein Produkt oder einen Algorithmus anbieten, der in der Lage ist, durch die Nutzung von Daten zu lernen und sich zu verbessern
- Die Quelle intelligenter Lernfähigkeiten in Softwareanwendungen sein
- In der Lage sein, Dateninputs aus verschiedenen Datenpools zu nutzen
- Die Fähigkeit haben, eine Ausgabe zu erzeugen, die ein bestimmtes Problem basierend auf den gelernten Daten löst
* Im Folgenden sind die fünf führenden Softwarelösungen für maschinelles Lernen aus dem G2 Fall 2024 Grid® Report aufgeführt. Einige Bewertungen können zur Klarheit bearbeitet worden sein.
1. Vertex AI
Vertex AI ist eine einheitliche Plattform, die die Entwicklung und Bereitstellung von ML-Modellen vereinfacht. Sie bietet eine umfassende Reihe von Tools und Diensten, einschließlich Datenvorbereitung, Modelltraining, Bewertung und Bereitstellung, was es Entwicklern und Datenwissenschaftlern erleichtert, ML-Anwendungen zu erstellen und zu verwalten.
Was Benutzer am meisten mögen:
"Für ein persönliches Projekt habe ich mich entschieden, einen konversationellen KI-Chatbot zu erstellen, der darauf abzielt, das Gespräch menschlicher zu gestalten. Ich habe zunächst Dialogflow verwendet, aber die Antworten klangen nicht natürlich. Ich hatte Schwierigkeiten, Gespräche zu organisieren, Benutzerflüsse zu planen und Fehler zu behandeln.
Dann habe ich den Vertex AI Agent Builder (früher Vertex AI Search and Conversations genannt) gefunden. Die Verwendung der Agent Builder API hat mir viel Zeit bei Authentifizierungs- und Zugriffsproblemen gespart. Am Ende konnte ich einen Chatbot erstellen, der natürlich klingt, indem ich eine Wissensdatenbank mit LLM und RAG erstellt habe."
- Vertex AI Review, Tejashri P.
Was Benutzer nicht mögen:
"Es fehlt an ausführlicher Dokumentation für einige erweiterte Funktionen und komplexere Anwendungsfälle. Darüber hinaus können je nach Arbeitslast und Konfiguration die Trainingszeiten manchmal langsamer erscheinen als bei der Verwendung dedizierter Hardware zum Ausführen von Modellen."
- Vertex AI Review, Manoj P.
2. Amazon Forecast
Amazon Forecast ist ein vollständig verwalteter maschineller Lernservice, der fortschrittliche Algorithmen verwendet, um genaue Vorhersagen für Zeitreihendaten zu generieren. Er nutzt dieselbe Technologie, die von Amazon.com verwendet wird, um zukünftige Trends für Millionen von Produkten vorherzusagen. Durch die genaue Vorhersage der zukünftigen Nachfrage nach Produkten und Dienstleistungen können Unternehmen Bestände optimieren, Abfall reduzieren und die Planung verbessern.
Was Benutzer am meisten mögen:
"Amazon Forecast ist ein einfach zu verwendender prädiktiver Analysedienst, der automatisch große Datenmengen verarbeitet und sich ideal für eine Vielzahl von Vorhersagebedürfnissen eignet. Mit seinen fortschrittlichen Algorithmen generiert er hochgenaue Vorhersagen und hilft Unternehmen, fundierte Entscheidungen auf der Grundlage zuverlässiger Erkenntnisse zu treffen."
- Amazon Forecast Review, Annette J.
Was Benutzer nicht mögen:
"Die Genauigkeit und Effektivität der von Amazon Forecast generierten Vorhersagen hängt stark von der Qualität und Relevanz der Eingabedaten ab. Wenn die historischen Daten, die für das Training verwendet werden, Anomalien, Ausreißer oder andere Qualitätsprobleme enthalten, kann dies die Genauigkeit der Vorhersage negativ beeinflussen."
- Amazon Forecast Review, Saurabh M.
3. Google Cloud TPU
Google Cloud TPU ist ein speziell entwickelter Anwendungsspezifischer integrierter Schaltkreis (ASIC) für maschinelles Lernen, der entwickelt wurde, um maschinelle Lernmodelle mit KI-Diensten auf Google Cloud auszuführen. Er bietet mehr als 100 Petaflops Leistung in nur einem einzigen Pod, was genug Rechenleistung für Geschäfts- und Forschungsbedürfnisse ist.
Was Benutzer am meisten mögen:
"Ich liebe die Tatsache, dass wir dank des optimalen Betriebs der modernsten maschinellen Lernmodelle einen hochmodernen KI-Dienst für Netzwerksicherheit aufbauen konnten. Die Leistung von Google Cloud TPU ist unvergleichlich: bis zu 11,5 Petaflops und 4 TB HBM. Am besten ist die benutzerfreundliche Google Cloud Platform-Oberfläche."
- Google Cloud TPU Review, Isabelle F.
Was Benutzer nicht mögen:
"Ich wünschte, es gäbe eine Integration mit Textverarbeitungsprogrammen."
- Google Cloud TPU Review, Kevin C.
4. Jarvis
Jarvis von NVIDIA ist eine Plattform für maschinelles Lernen, die eine benutzerfreundliche Oberfläche für den Aufbau und die Bereitstellung von ML-Modellen bietet. Sie vereinfacht den Prozess der Datenvorbereitung, Modellauswahl, des Trainings und der Bewertung. Jarvis ML bietet vorgefertigte Modelle für gängige Aufgaben wie Bildklassifikation, natürliche Sprachverarbeitung und Zeitreihenvorhersagen.
Was Benutzer am meisten mögen:
"Jarvis ist ähnlich wie andere KI-Technologien, aber was ich am meisten daran schätze, ist die Sprachbefehlseingabefunktion, die die Produktivität steigert. Darüber hinaus bietet es kreative Inhaltsvorschläge für Blog-Ersteller, was es zu einem wertvollen Werkzeug für die Inhaltserstellung macht."
- Jarvis Review, Akshit N.
Was Benutzer nicht mögen:
"Die Sprachfunktion ist effektiv, aber Benutzer, die an Google Voice gewöhnt sind, könnten die Eingabe-zu-Ausgabe-Flüssigkeit im Vergleich zu anderen Sprachoptionen als weniger zufriedenstellend empfinden. Während die Benutzeroberfläche optisch ansprechend erscheint, ist es wichtig, dass die hinter der UI konfigurierte API ebenfalls gut funktioniert."
- Jarvis Review, Adithya K.
5. Aerosolve
Aerosolve ist eine Softwareplattform für maschinelles Lernen, die hauptsächlich für prädiktive Analysen und Anwendungen der Datenwissenschaft entwickelt wurde. Sie zeichnet sich besonders durch ihre Benutzerfreundlichkeit aus und ermöglicht es Benutzern, komplexe Modelle zu erstellen, ohne umfangreiche Programmierkenntnisse zu benötigen.
Was Benutzer am meisten mögen:
"Ich bin beeindruckt von seinen fortschrittlichen Fähigkeiten. Es ist sehr einfach zu bedienen, mit reibungsloser Implementierung und unkomplizierter Integration. Darüber hinaus ist der Kundensupport anständig, was die Gesamterfahrung positiv macht."
- Aerosolve Review, Rahul S.
Was Benutzer nicht mögen:
"Aerosolve ist in Bereichen wie Bildverarbeitungsfähigkeiten unzureichend."
- Aerosolve Review, Aurelija A.
Für die aktuellste Liste mit einer ausführlichen Bewertung lesen Sie diesen G2-Leitfaden zu den besten ML-Plattformen für 2026.
KI ist das Gehirn, ML ist der Muskel!
Maschinelles Lernen ist der Muskel, der es der KI ermöglicht, zu lernen, sich anzupassen und komplexe Aufgaben auszuführen. Von der Datenwissenschaft bis zur KI-Entwicklung wird maschinelles Lernen überall eingesetzt.
Da sich das maschinelle Lernen weiterentwickelt, können wir noch innovativere Anwendungen erwarten. Von selbstfahrenden Autos bis hin zur personalisierten Medizin transformiert maschinelles Lernen Branchen und verbessert unser Leben.
Mit diesem Fortschritt geht jedoch die Verantwortung einher, sicherzustellen, dass diese Technologien ethisch entwickelt und genutzt werden. Indem wir Bedenken wie Datenschutz und Voreingenommenheit ansprechen, können wir die Kraft der KI durch maschinelles Lernen nutzen und eine personalisiertere, integrativere und intelligentere Zukunft schaffen.
Entdecken Sie Statistiken zum maschinellen Lernen, die die zukünftige Landschaft prägen werden.
Dieser Artikel wurde ursprünglich 2021 veröffentlicht. Er wurde mit neuen Informationen aktualisiert.