
Vladimir N. Vapnik desenvolveu algoritmos de máquina de vetores de suporte (SVM) para lidar com problemas de classificação na década de 1990. Esses algoritmos encontram um hiperplano ótimo, que é uma linha em um plano 2D ou 3D, entre duas categorias de conjuntos de dados para distingui-las.
O SVM facilita o processo do algoritmo de aprendizado de máquina (ML) para generalizar novos dados enquanto faz previsões de classificação precisas.
Muitos softwares de reconhecimento de imagem e plataformas de classificação de texto usam SVM para classificar imagens ou documentos textuais. Mas o alcance dos SVMs vai além disso. Depois de cobrir os fundamentos, vamos explorar alguns de seus usos mais amplos.
O que são máquinas de vetores de suporte?
Máquinas de vetores de suporte (SVMs) são algoritmos de aprendizado de máquina supervisionados que desenvolvem métodos de classificação de objetos em um espaço n-dimensional. As coordenadas desses objetos são geralmente chamadas de características.
Os SVMs desenham um hiperplano para separar duas categorias de objetos de modo que todos os pontos de uma categoria de objetos estejam de um lado do hiperplano. O objetivo é encontrar o melhor plano, que maximize a distância (ou margem) entre dois pontos em cada categoria. Os pontos que caem nessa margem são chamados de vetores de suporte. Esses vetores de suporte são críticos na definição do hiperplano ótimo.
Entendendo as máquinas de vetores de suporte em detalhes
O SVM requer treinamento em pontos rotulados de categorias específicas para encontrar o hiperplano, tornando-o um algoritmo de aprendizado supervisionado. O algoritmo resolve um problema de otimização convexa em segundo plano para maximizar a margem com cada ponto de categoria no lado certo. Com base nesse treinamento, ele pode atribuir uma nova categoria a um objeto.

Fonte: Visually Explained
As máquinas de vetores de suporte são fáceis de entender, implementar, usar e interpretar. No entanto, sua simplicidade nem sempre as beneficia. Em algumas situações, é impossível separar duas categorias com um hiperplano simples. Para resolver isso, o algoritmo encontra um hiperplano no espaço de dimensão superior com uma técnica conhecida como truque do kernel e o projeta de volta para o espaço original.
É o truque do kernel que permite que você execute essas etapas de forma eficiente.
Quer aprender mais sobre Software de Reconhecimento de Imagem? Explore os produtos de Reconhecimento de Imagem.
O que é um truque do kernel?
No mundo real, separar a maioria dos conjuntos de dados com um hiperplano simples é desafiador, pois a fronteira entre duas classes raramente é plana. É aqui que o truque do kernel entra em cena. Ele permite que o SVM lide com limites de decisão não lineares de forma eficiente, sem alterar significativamente o próprio algoritmo.
No entanto, escolher essa transformação não linear é complicado. Para obter uma fronteira de decisão sofisticada, você precisa aumentar a dimensão da saída, o que aumenta os requisitos computacionais.
O truque do kernel resolve esses dois desafios de uma só vez. Ele se baseia em uma abordagem onde o algoritmo SVM não precisa saber sempre que cada ponto é mapeado sob transformação não linear. Ele pode trabalhar com a forma como cada ponto de dados se compara com os outros.
Ao aplicar a transformação não linear, você toma o produto interno entre F(x) e F(x) primo, conhecido como função kernel.
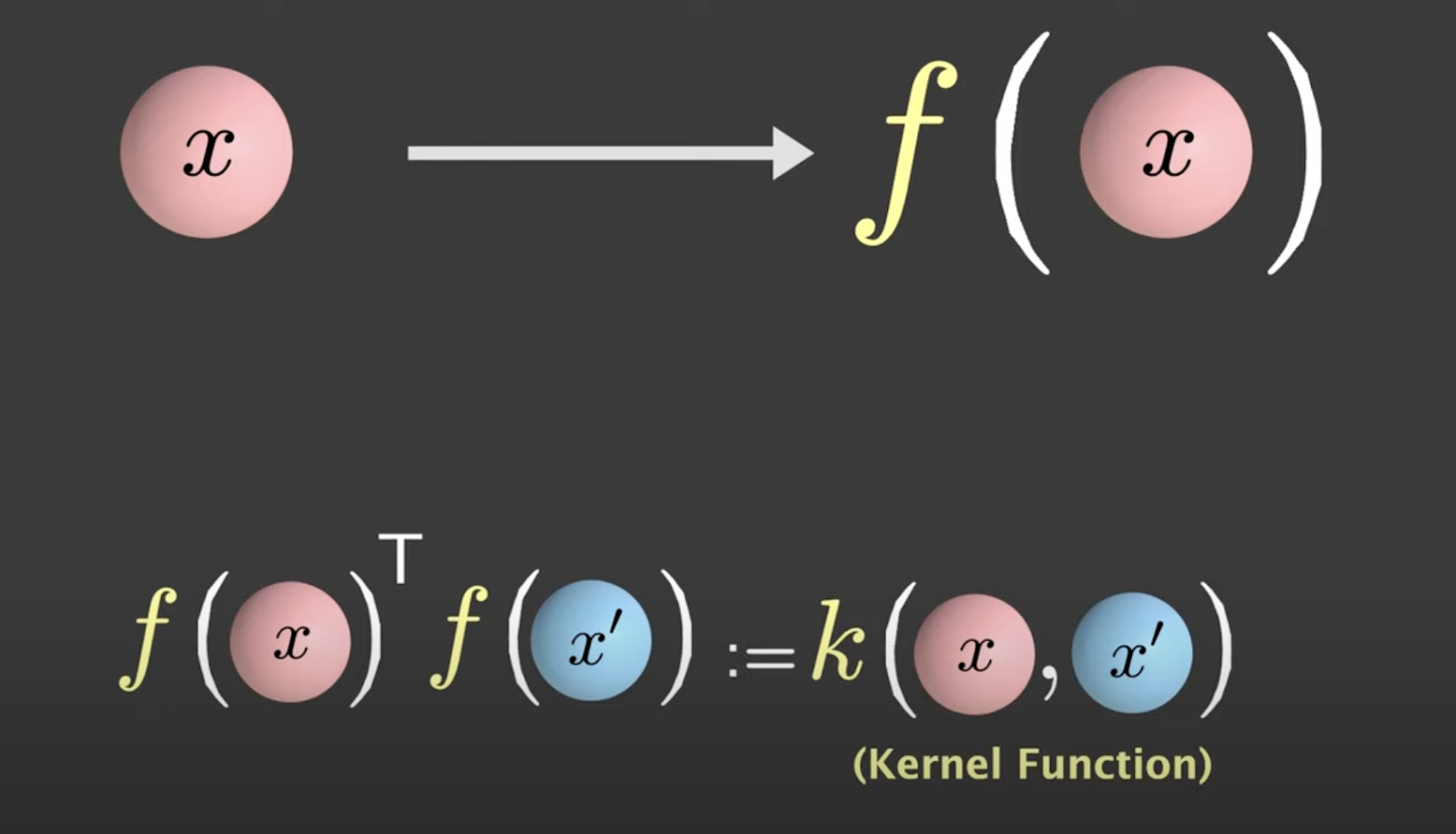
Fonte: Visually Explained
No entanto, esse kernel linear dá uma fronteira de decisão que pode ou não ser boa o suficiente para separar os dados. Nesses casos, você opta por uma transformação polinomial correspondente a um kernel polinomial. Essa abordagem leva em consideração as características originais do conjunto de dados, bem como considera suas interações para obter uma fronteira de decisão mais sofisticada e curva.

Fonte: Visually Explained
O truque do kernel é benéfico e parece um código de trapaça de videogame. É fácil ajustar e ser criativo com os kernels.
Tipos de classificadores de máquina de vetores de suporte
Existem dois tipos de SVM classificados: linear e kernel.
1. SVMs Lineares
SVMs lineares são quando os dados não precisam passar por transformações e são linearmente separáveis. Uma única linha reta pode facilmente segregar os conjuntos de dados em categorias ou classes.
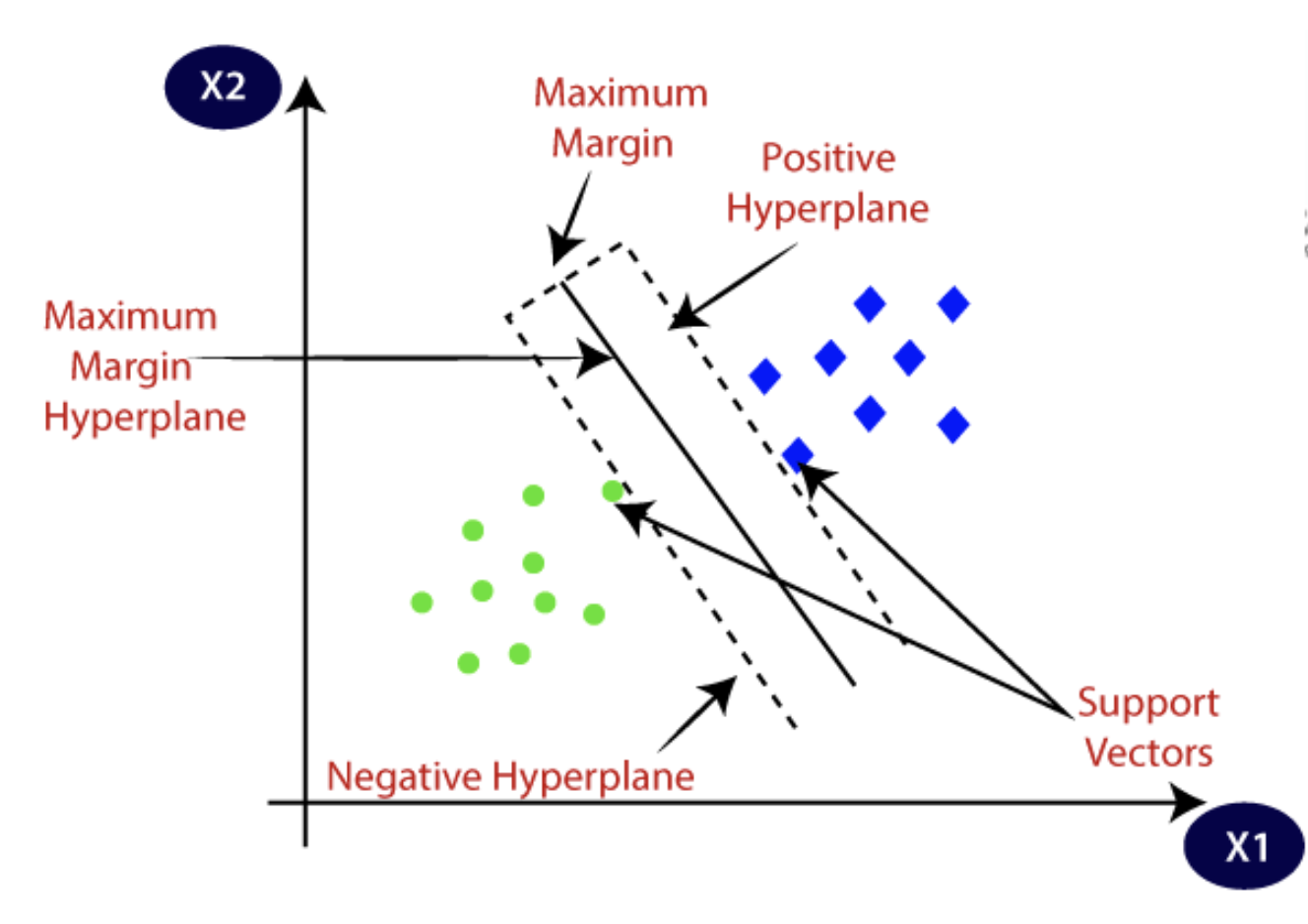
Fonte: Javatpoint
Como esses dados são linearmente distintos, o algoritmo aplicado é conhecido como SVM linear, e o classificador que ele produz é o classificador SVM. Este algoritmo é eficaz para problemas de classificação e de análise de regressão.
2. SVMs Não Lineares ou Kernel
Quando os dados não são linearmente separáveis por uma linha reta, é usado um classificador SVM não linear ou Kernel. Para dados não lineares, a classificação é realizada adicionando características em dimensões superiores em vez de confiar no espaço 2D.
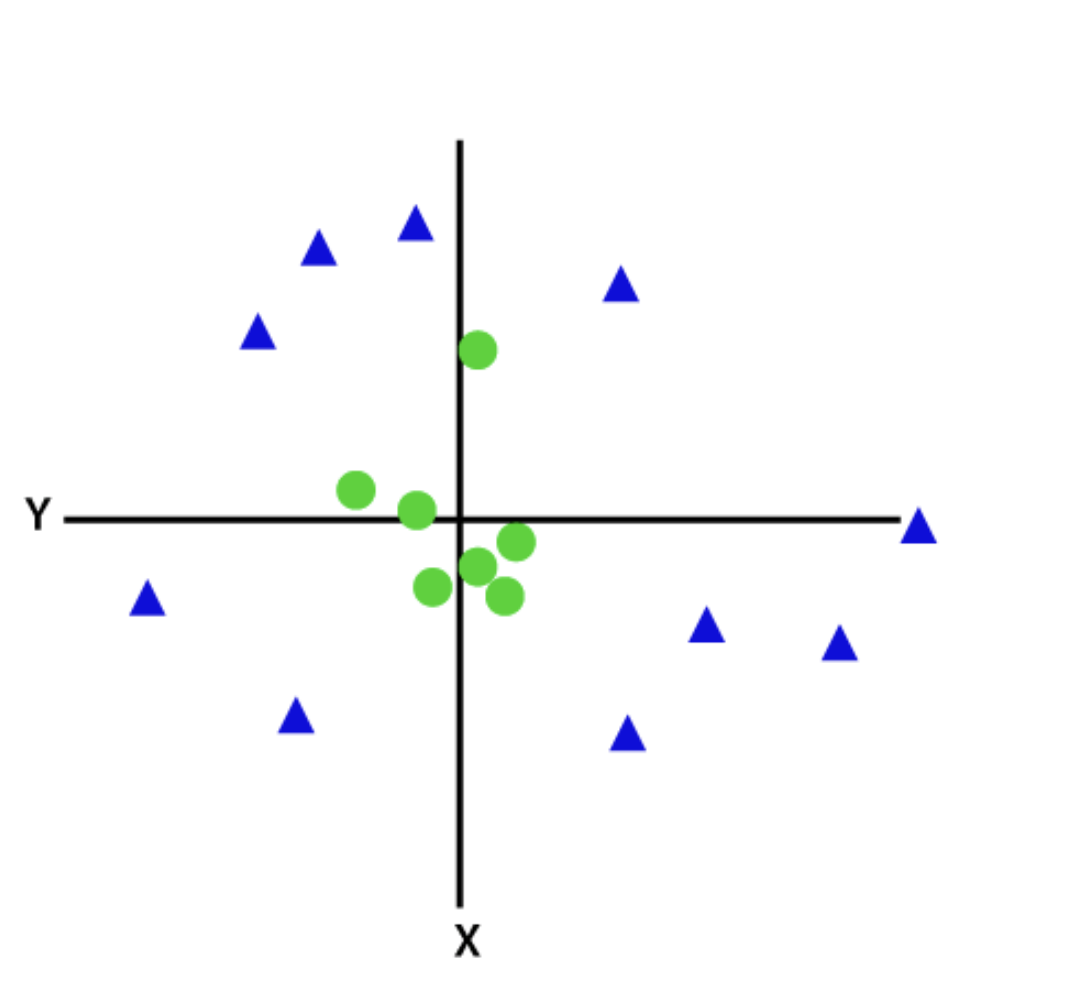
Fonte: Javatpoint
Após a transformação, adicionar um hiperplano que separa facilmente classes ou categorias se torna fácil. Esses SVMs são geralmente usados para problemas de otimização com várias variáveis.
A chave para os SVMs não lineares é o truque do kernel. Ao aplicar diferentes funções kernel, como linear, polinomial, função de base radial (RDF) ou kernel sigmoide, os SVMs podem lidar com uma ampla variedade de estruturas de dados. A escolha do kernel depende das características dos dados e do problema a ser resolvido.
Como funciona uma máquina de vetores de suporte?
O algoritmo de máquina de vetores de suporte visa identificar um hiperplano para separar pontos de dados de diferentes classes. Eles foram potencialmente projetados para problemas de classificação binária, mas evoluíram para resolver problemas de múltiplas classes.
Com base nas características dos dados, os SVMs empregam funções kernel para transformar características de dados em dimensões superiores, facilitando a adição de um hiperplano que separa diferentes classes de conjuntos de dados. Isso ocorre por meio da técnica do truque do kernel, onde a transformação de dados é alcançada de forma eficiente e econômica.
Para entender como o SVM funciona, devemos analisar como um classificador SVM é construído. Começa com a divisão dos dados. Divida seus dados em um conjunto de treinamento e um conjunto de teste. Isso ajudará você a identificar outliers ou dados ausentes. Embora não seja tecnicamente necessário, é uma boa prática.
Em seguida, você pode importar um módulo SVM para qualquer biblioteca. Scikit-learn é uma biblioteca Python popular para máquinas de vetores de suporte. Ela oferece uma implementação eficaz de SVM para tarefas de classificação e regressão. Comece treinando suas amostras no classificador e prevendo respostas. Compare o conjunto de teste e os dados previstos para comparar a precisão para avaliação de desempenho.
Existem outras métricas de avaliação que você pode usar, como:
- F1-score calcula quantas vezes um modelo fez uma previsão correta em todo o conjunto de dados. Ele combina as pontuações de precisão e recall de um modelo.
- Precisão mede com que frequência um modelo de aprendizado de máquina prevê corretamente a classe positiva.
- Recall avalia com que frequência um modelo de ML identifica verdadeiros positivos de todas as amostras positivas reais no conjunto de dados.
Em seguida, você pode ajustar os hiperparâmetros para melhorar o desempenho de um modelo SVM. Você obtém os hiperparâmetros iterando em diferentes kernels, valores de gama e regularização, o que ajuda a localizar a combinação mais ideal.
Aplicações de máquinas de vetores de suporte
Os SVMs encontram aplicações em vários campos. Vamos ver alguns exemplos de SVMs aplicados a problemas do mundo real.
- Estimativa de resistência da superfície do solo: Calcular a liquefação do solo é crítico no projeto de estruturas de engenharia civil, especialmente em zonas propensas a terremotos. Os SVMs ajudam a prever se a liquefação ocorre ou não no solo, criando modelos que incluem múltiplas variáveis para avaliar a resistência do solo.
- Problema de geo-sondagem: Os SVMs ajudam a rastrear a estrutura em camadas do planeta. As propriedades de regularização da formulação de vetores de suporte são aplicadas ao problema inverso de geo-sondagem. Aqui, os resultados estimam as variáveis ou parâmetros que os produziram. O processo envolve funções lineares e modelos algorítmicos de vetores de suporte separando dados eletromagnéticos.
- Detecção de homologia remota de proteínas: Os modelos SVM usam funções kernel para detectar semelhanças em sequências de proteínas com base nas sequências de aminoácidos. Isso ajuda a categorizar proteínas em parâmetros estruturais e funcionais, o que é importante na biologia computacional.
- Detecção facial e classificação de expressões: Os SVMs classificam estruturas faciais de não faciais. Esses modelos analisam os pixels e classificam as características em características faciais ou não faciais. No final, o processo cria uma fronteira de decisão quadrada em torno da estrutura facial com base na intensidade dos pixels.
- Categorização de texto e reconhecimento de escrita à mão: Aqui, cada documento carrega uma pontuação comparada com um valor de limiar, facilitando sua classificação na categoria relevante. Para reconhecer a escrita à mão, os modelos SVM são primeiro treinados com dados de treinamento sobre escrita à mão e, em seguida, eles segregam a escrita humana e a escrita por computador com base na pontuação.
- Detecção de esteganografia: Os SVMs ajudam a garantir que as imagens digitais não sejam contaminadas ou adulteradas por ninguém. Ele separa cada pixel e os armazena em diferentes conjuntos de dados que os SVMs analisam posteriormente.
Resolvendo problemas de classificação com precisão
As máquinas de vetores de suporte ajudam a resolver problemas de classificação enquanto fazem previsões precisas. Esses algoritmos podem lidar facilmente com dados lineares e não lineares, tornando-os adequados para várias aplicações, desde classificação de texto até reconhecimento de imagem.
Além disso, os SVMs reduzem o overfitting, que ocorre quando o modelo aprende demais com os dados de treinamento, afetando seu desempenho em novos dados. Eles se concentram em pontos de dados importantes, chamados de vetores de suporte, ajudando-os a fornecer resultados confiáveis e precisos.
Saiba mais sobre modelos de aprendizado de máquina e como treiná-los.
Editado por Monishka Agrawal

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.

