
Pensa di guardare un film o una serie TV su una piattaforma di streaming.
Quando si utilizzano piattaforme di streaming, gli utenti globali trasmettono in streaming o memorizzano localmente file multimediali di grandi dimensioni, multi-gigabyte (GB), simultaneamente.
Lo streaming di oggetti è ciò che accade in background quando si fa questo. Ogni serie TV o film è memorizzato come un oggetto diviso o un intervallo montato di oggetti. E il modo in cui sono memorizzati è un classico esempio di archiviazione a oggetti.
Cos'è l'archiviazione a oggetti?
L'archiviazione a oggetti, o archiviazione basata su oggetti, è un'architettura di archiviazione dati che memorizza i dati come oggetti o unità distinte. Questi oggetti contengono i dati, i metadati rilevanti e identificatori unici globali (GUID) – tutti immediatamente accessibili tramite interfacce RESTFUL, API o HTTP/HTTPS. La struttura piatta di un sistema di archiviazione a oggetti consente di memorizzare i dati in un unico magazzino anziché in file in cartelle o blocchi in server.
Il software di archiviazione a oggetti è più adatto per le organizzazioni che vogliono raccogliere, memorizzare e analizzare una grande quantità di dati. Le soluzioni di archiviazione a oggetti sono cruciali per abilitare analisi che richiedono molta larghezza di banda. Possono aiutare le aziende a risolvere un portafoglio di archiviazione frammentato, recuperare i dati più velocemente e ottimizzare le risorse.
L'archiviazione a oggetti non è sempre stata l'opzione preferita per gestire enormi quantità di dati. Nei primi tempi, era più adatta per gestire laghi di dati, backup e archivi di dati. Poi è arrivata l'era della crescita esplosiva dei dati. Un database relazionale tradizionale era incapace di gestire l'enorme quantità di dati generati.
Questo ha costretto le aziende a ripensare l'archiviazione basata su blocchi o file, essere resilienti ai dati e andare oltre la capacità di archiviazione. Sviluppato alla fine degli anni '90 dai ricercatori della Carnegie Mellon University e dell'Università della California–Berkeley, il software di archiviazione a oggetti oggi può memorizzare e gestire terabyte (TB) o petabyte (PB) di dati in un unico namespace con la trifecta di scala, velocità ed economicità. Ciò che li ha ulteriormente costretti a ripensare l'infrastruttura IT on-premises è l'ascesa delle applicazioni cloud-native.
Archiviazione a oggetti vs. archiviazione a blocchi vs. archiviazione a file
La quantità di dati con cui lavori continua a crescere ogni giorno, rendendo la gestione dei dati ancora più opprimente. Con tre tipi di architettura di archiviazione: archiviazione a oggetti, archiviazione a blocchi e archiviazione a file tra cui scegliere, è cruciale avere una solida comprensione dei pro e dei contro di ciascuno perché la tecnologia di archiviazione che scegli influenza significativamente le decisioni aziendali.
.png)
Archiviazione a oggetti
Le aziende che cercano di archiviare e fare il backup di dati non strutturati prodotti da dispositivi Internet of Things (IoT) spesso trovano l'archiviazione basata su oggetti la soluzione migliore. Questi dati non strutturati includono contenuti web, media e dati dei sensori.
Un sistema di archiviazione a oggetti si basa su un ambiente dati strutturalmente piatto anziché su gerarchie complesse come cartelle o directory per memorizzare i dati come oggetti. Pensa a questi oggetti come a repository o bucket autonomi. Ognuno di essi memorizza dati con identificatori unici (UID) e metadati personalizzabili. Le organizzazioni possono rispecchiare e eseguire il codice di cancellazione per questi bucket attraverso data center e dispositivi di archiviazione.
Caratteristiche dell'archiviazione a oggetti:
- Protocolli di accesso ai dati flessibili
- Architettura distribuita e scalabile
- Gestione delle informazioni basata su metadati
- Multi-tenancy all'interno della stessa infrastruttura
- Namespace globale per una maggiore trasparenza dei dati
- Gestione automatizzata del sistema per ridurre la complessità
- Protezione avanzata dei dati tramite codifica di cancellazione e replica dei dati
Grazie alla sua scalabilità e affidabilità, l'archiviazione a oggetti è ampiamente utilizzata per applicazioni di archiviazione basate su cloud. Inoltre, lo schema di indirizzamento piatto rende facile cercare e accedere a singoli oggetti.
S3, che era originariamente Amazon S3, è il protocollo di accesso più comune che gli archivi di oggetti utilizzano. Utilizza comandi senza connessione come LIST, GET, PUT e DELETE per accedere agli oggetti. Oggi, le applicazioni possono utilizzare nativamente il protocollo S3 per accedere ai file, il che significa che non è più necessario un file system.
Archiviazione a blocchi
L'archiviazione a blocchi, o archiviazione a livello di blocco, è la forma più antica e semplice di archiviazione dati. Memorizza i dati in blocchi di dimensioni fisse. Ciascuno di questi blocchi ha un indirizzo e memorizza unità di dati separate su reti di archiviazione (SAN).
Invece di metadati personalizzabili, un sistema di archiviazione a blocchi utilizza indirizzi per identificare i file e un'interfaccia di sistema di computer piccolo su internet (iSCSI) per trasportarli dai blocchi richiesti. Questo controllo granulare porta a prestazioni più veloci quando sia l'applicazione che l'archiviazione sono locali. Ci sarà anche più latenza quando sono più distanti.
Le piattaforme di archiviazione a blocchi consentono la creazione di percorsi dati multipli e un facile recupero disaccoppiando i dati dagli ambienti utente e distribuendoli su più ambienti. Questo rende l'archiviazione a blocchi la scelta preferita per gli sviluppatori di applicazioni che cercano soluzioni di trasferimento dati veloci, affidabili ed efficienti per situazioni di calcolo ad alte prestazioni.
Ad esempio, un'implementazione di macchine virtuali a livello aziendale può sfruttare l'archiviazione a blocchi per memorizzare il file system della macchina virtuale (VMFS). Utilizzare un volume di archiviazione basato su blocchi per memorizzare il VMFS rende più facile per gli utenti condividere file utilizzando il sistema operativo (OS) nativo.
Archiviazione a file
L'archiviazione a file, nota anche come archiviazione a livello di file o archiviazione basata su file, è una metodologia gerarchica per memorizzare o organizzare dati su un dispositivo di archiviazione collegato alla rete (NAS). Funziona molto come un tradizionale sistema di file di rete, il che significa che è facile da configurare ma offre solo un percorso singolo ai dati.
Ad esempio, i dispositivi di archiviazione collegati alla rete (NAS) utilizzano sistemi di archiviazione a file per condividere dati su reti locali (LAN) o reti geografiche (WAN). Poiché l'archiviazione a file utilizza protocolli comuni a livello di file, i sistemi dissimili di solito limitano l'usabilità.
Alimentato da un sistema di file globale, l'archiviazione a file utilizza directory e sottodirectory per memorizzare i dati. Il sistema di file è responsabile della gestione di diversi attributi di file come la posizione della directory, la data di accesso, il tipo di file, la dimensione del file, i dettagli di creazione e modifica.
Il caso d'uso perfetto per l'archiviazione a file è la gestione di dati strutturati.
Un volume crescente di dati sarà difficile da gestire a causa delle crescenti richieste di risorse e dei problemi strutturali. Alcuni di questi problemi possono essere risolti con dispositivi ad alta capacità con abbondante spazio di archiviazione o archiviazione a file basata su cloud.
| Archiviazione a oggetti | Archiviazione a blocchi | Archiviazione a file | |
| Architettura | Dati come oggetti | Dati in blocchi | Dati in file |
| Struttura | Piatta | Altamente strutturata | Strutturata gerarchicamente |
| Trasporto | TCP/IP | FC/iSCSI | TCP/IP |
| Interfaccia | HTTP, REST | Collegamento diretto/SAN | NFS, SMB |
| Geografia | Può essere memorizzata in più regioni | Può essere memorizzata in più regioni | Disponibile localmente |
| Scalabilità | Infinita | Limitata | Possibile solo per l'archiviazione a file basata su cloud |
| Analisi | Metadati personalizzabili per un facile recupero dei file | Nessun metadato | Diversi attributi di file per un facile riconoscimento |
| Quando usare | Elevata larghezza di banda di streaming | Dati di database e transazionali | Archiviazione dati collegata alla rete |
| Miglior caso d'uso | Grandi volumi di dati (statici o non strutturati) | Flussi di lavoro intensivi di dati con bassa latenza | Backup dei dati, archiviazione dei dati, condivisione di file locali e libreria centralizzata |
L'architettura distribuita e scalabile dell'archiviazione a oggetti è possibile grazie all'accesso parallelo ai dati e ai metadati distribuiti. Prima di approfondire l'architettura, è importante conoscere i diversi componenti dell'archiviazione a oggetti.
Vuoi saperne di più su Soluzioni di archiviazione oggetti? Esplora i prodotti Soluzioni di Archiviazione Oggetti.
Quali sono i componenti dell'archiviazione a oggetti?
La ragione per cui l'archiviazione a oggetti è così attraente risiede nella sua gerarchia di sistema piatta che promuove l'accessibilità, la ricercabilità, la sicurezza e la scalabilità. Questo ambiente piatto è costruito da più componenti che rendono più facile per te memorizzare grandi volumi di dati su reti distribuite. Questi componenti sono:
Oggetto
Un oggetto è l'unità fondamentale di un sistema di archiviazione basato su oggetti. Contiene dati con attributi come metadati rilevanti e identificatori unici.
Ci sono tre tipi di oggetti:
- Oggetto radice: Identifica il dispositivo di archiviazione e i suoi attributi
- Oggetto di gruppo: Offre una directory al sottoinsieme logico di oggetti su un dispositivo di archiviazione a oggetti
- Oggetto utente: Sposta i dati dell'applicazione per scopi di archiviazione e memorizza attributi relativi all'utente e all'archiviazione
Dispositivo di archiviazione basato su oggetti (OSD)
Un dispositivo di archiviazione basato su oggetti è responsabile della gestione dell'archivio locale degli oggetti, del servizio e della memorizzazione dei dati dalla rete. È la base dell'architettura di archiviazione a oggetti e consiste in un disco, memoria ad accesso casuale (RAM), un processore e un'interfaccia di rete.
Quattro funzioni principali di un dispositivo di archiviazione basato su oggetti sono:
- Archiviazione dati: Memorizza e recupera dati in modo affidabile tramite ID oggetti
- Layout intelligente: Ottimizza il layout dei dati e il pre-fetching utilizzando il processore
- Gestione dei metadati: Gestisce i metadati per gli oggetti memorizzati
- Sicurezza: Ispeziona le trasmissioni in arrivo per la sicurezza
I dispositivi di archiviazione basati su oggetti funzionano in modo simile alle reti di archiviazione (SAN) nei sistemi di archiviazione tradizionali ma possono essere indirizzati direttamente in parallelo senza l'intervento di un array ridondante di dischi indipendenti (RAID).
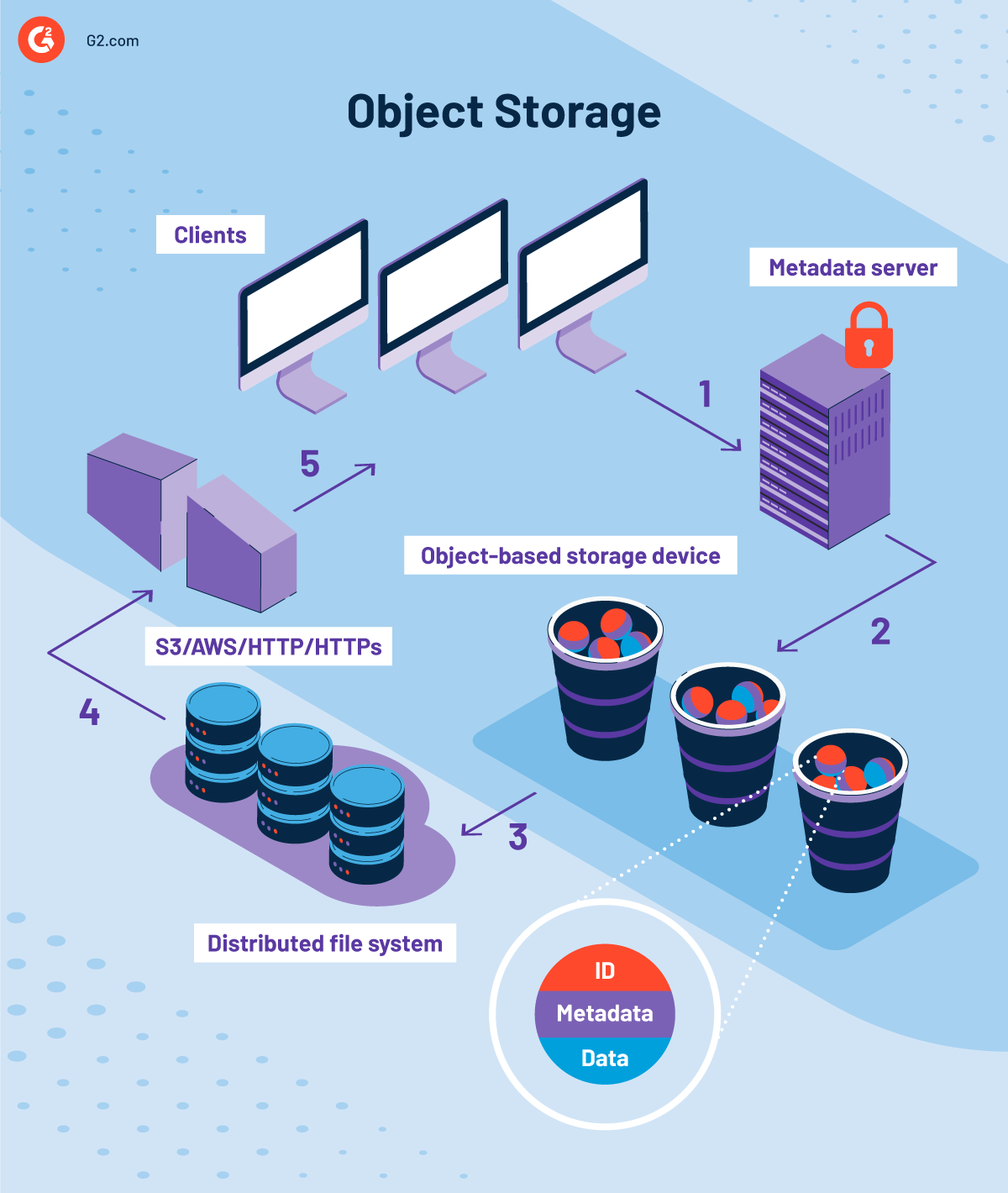
File system distribuito
Un file system distribuito sfrutta un file system installabile per consentire ai nodi del computer di leggere e scrivere oggetti sul dispositivo di archiviazione a oggetti. Le sue funzioni chiave sono:
- Interfaccia del sistema operativo portatile (POSIX): Facilita le operazioni di sistema standard come Apri, Leggi, Scrivi e Chiudi per il sistema di archiviazione sottostante
- Caching: Fornisce caching per i dati in arrivo nel nodo di calcolo
- Striping: Gestisce lo striping degli oggetti su più dispositivi di archiviazione a oggetti
- Montaggio: Utilizza il controllo degli accessi per montare i file system alla radice
- Driver dell'interfaccia di sistema di computer piccolo su internet (iSCSI): Implementa il driver iSCSI per facilitare le estensioni degli oggetti e il payload dei dati
Server dei metadati
Un server dei metadati (MDS) funge da repository centrale e facilita l'archiviazione, la gestione e la consegna dei metadati utilizzando il metamodel comune del magazzino (CWM) e l'architettura dei metadati aperta.
Coordina con i nodi autorizzati per garantire una corretta interazione tra nodi e oggetti. Mantiene anche la coerenza della cache per gli stessi file. La rimozione dei server dei metadati risulta in un'elevata larghezza di banda e scalabilità lineare negli ambienti di rete di archiviazione (SAN).
Le funzioni chiave del server dei metadati sono:
- Autenticazione: Identifica e autentica i dispositivi di archiviazione basati su oggetti in attesa di unirsi al sistema di archiviazione
- Gestione degli accessi: Gestisce l'accesso ai file e alle directory per le richieste di operazione dai nodi
- Coerenza della cache: Aggiorna le cache locali prima di consentire a più nodi di utilizzare lo stesso file
- Gestione della capacità: Garantisce l'uso ottimale delle risorse del disco disponibili
- Scalabilità: Gestisce la gestione dei metadati a livello di file e directory per la scalabilità
Tessuto di rete
Il tessuto di rete è responsabile della connessione dell'intera rete, cioè dispositivi di archiviazione basati su oggetti, nodi di calcolo e server dei metadati in un unico tessuto. Altri componenti chiave della rete sono:
- Protocollo dell'interfaccia di sistema di computer piccolo su internet (iSCSI): Un protocollo di trasporto di base per dati e comandi ai dispositivi di archiviazione a oggetti (OSD)
- Supporto per comandi di chiamata di procedura remota (RPC): Facilita la comunicazione tra server dei metadati e nodi di calcolo
Come funziona l'archiviazione a oggetti?
I volumi di archiviazione a oggetti funzionano come repository autonomi e memorizzano i dati in unità modulari. Sia l'identificatore che i metadati dettagliati giocano un ruolo chiave nelle prestazioni superiori della distribuzione del carico. Una volta creato un oggetto, può essere facilmente copiato su nodi aggiuntivi, a seconda delle politiche esistenti. I nodi con alta disponibilità e ridondanza possono essere dispersi geograficamente o memorizzati nello stesso data center.
Gli ambienti di cloud computing pubblico consentono l'accesso all'archiviazione a oggetti tramite HTTP o REST API. La maggior parte dei fornitori di servizi di archiviazione cloud pubblica di solito offre API che costruiscono loro stessi. Alcuni dei comandi comuni inviati a HTTP includono PUT (per creare oggetti), GET (per leggere oggetti), DELETE (per eliminare oggetti) e LIST (per elencare oggetti).
Come si muove i dati un sistema di archiviazione a oggetti?
Operazioni di LETTURA:
- Un client si connette con il server dei metadati
- L'identità del nodo è convalidata dal server dei metadati
- Il server dei metadati restituisce un elenco di oggetti sui dispositivi di archiviazione a oggetti
- Il server dei metadati convalida l'identità del nodo
- Un token di sicurezza viene inviato al nodo per accedere a oggetti specifici
- Il nodo confeziona i dati
- Il dispositivo di archiviazione a oggetti trasferisce i dati al client
Operazioni di SCRITTURA:
- Un client richiede al server dei metadati di scrivere un oggetto
- Il server dei metadati autorizza il nodo con un token di sicurezza
- Il nodo confeziona la richiesta di SCRITTURA e la invia a due OSD contemporaneamente
- Il nodo elaborerà la richiesta e informerà il client
Quali sono i vantaggi dell'archiviazione a oggetti?
Raggiungere prestazioni di picco su hardware server di commodity diventa molto più facile con un sistema di archiviazione a oggetti. Se la tua azienda ha un lago di dati in crescita esponenziale, cioè un pool di dati non strutturati, l'archiviazione a oggetti è un must per organizzare, gestire e accedere ai dati. Ecco perché:
- Facilità di ricerca: Gli oggetti in un sistema di archiviazione a oggetti sono di solito memorizzati con ID unici, metadati personalizzabili e URL HTTP. Tutti questi rendono super facile per gli utenti trovare oggetti ed eseguire operazioni di LETTURA/SCRITTURA. Questa facilità di accesso e ricerca rende i sistemi di archiviazione a oggetti una scelta preferita per le organizzazioni che gestiscono dati non strutturati.
- Scalabilità illimitata: Forse il più grande vantaggio dei sistemi di archiviazione a oggetti è che possono facilmente scalare quando i dati crescono. L'architettura strutturale piatta consente l'aggiunta orizzontale di nodi e rende facile gestire grandi volumi di dati.
- Agilità: I sistemi di file tradizionali e i database non sono di solito agili e richiedono una manutenzione professionale rigorosa. I sistemi di archiviazione a oggetti possono gestirsi da soli in base alle istruzioni dei metadati e consentono agli sviluppatori di cambiare app senza dipendere dal team dell'infrastruttura. Questa agilità è ciò che rende efficiente la gestione del ciclo delle informazioni per le organizzazioni che adottano soluzioni di archiviazione a oggetti.
- Recupero economico: Un sistema di archiviazione a oggetti può copiare oggetti su più di un nodo mentre crea un oggetto. Nel caso improbabile di disastri, il tempo di recupero dei dati diventa più facile per le organizzazioni poiché questi nodi sono situati in tutto il mondo. Questo elimina la necessità di memorizzare grandi volumi di dati in hardware fisico e rende l'archiviazione a oggetti economica.
- Sicurezza avanzata: Le soluzioni di archiviazione a oggetti basate su cloud consentono alle imprese di memorizzare i dati in modo sicuro con crittografia in transito e a riposo. Molti fornitori di archiviazione cloud offrono anche altre funzionalità di sicurezza come la protezione da ransomware, la multi-tenancy sicura, l'autenticazione del protocollo leggero di accesso alla directory (LDAP), la protezione da fuoriuscite di dati e così via.
Quando usare l'archiviazione a oggetti:
- Recupero da disastri
- App mobili e basate su internet
- Backup e recupero di dati critici
- Estensione dell'archiviazione on-premise con archiviazione cloud ibrida
- Archiviazione write-once-read-many (WORM) per archivi di conformità
- Per memorizzare fonti di dati non strutturati, come file multimediali
Detto ciò, i sistemi di archiviazione a oggetti non sono adatti per la gestione di dati transazionali e di database. Inoltre, non consentono l'alterazione di un singolo pezzo di dati. Per modificare una parte di un blocco, è necessario leggere e scrivere completamente l'intero oggetto.
Come possono i sistemi di archiviazione a oggetti proteggere i dati dal ransomware?
Con sistemi complessi arrivano vulnerabilità complesse. Ecco perché è super importante avere una solida strategia di recupero. Uno dei modi migliori per gestire il ransomware è bypassare l'infezione ripristinando i dati tramite un backup sicuro. E l'archiviazione a oggetti offre la soluzione perfetta per questo. Perché?:
- Nessuna modifica non autorizzata dei dati: L'archiviazione a oggetti ha un'architettura di archiviazione dati immutabile, il che significa che non può essere modificata una volta scritta. Questo perché i dati sono scritti utilizzando la tecnologia write once read many (WORM). Inoltre, gli amministratori hanno la libertà di abilitare l'immutabilità a livello di bucket. Poiché i dati non possono essere modificati, non possono essere crittografati dal ransomware. Alcuni fornitori di archiviazione cloud offrono anche la funzionalità di blocco degli oggetti che funziona in sinergia con WORM per proteggere i dati a livello di dispositivo.
- Più copie dei dati: Sempre più criminali informatici continuano a utilizzare varianti di ransomware per mirare ai backup dei dati anziché ai dati stessi. La funzionalità di versioning dei dati di un sistema di archiviazione a oggetti ti consente di creare una nuova copia dei dati mentre li alteri. Questo significa che ci sarà sempre una copia dei dati originali anche se un file è crittografato dal ransomware.
Le migliori pratiche per l'archiviazione a oggetti
Ottenere il massimo dall'archiviazione a oggetti non è facile. Indipendentemente dal tipo di dati non strutturati con cui la tua organizzazione ha a che fare, è importante seguire le migliori pratiche per gestire i tuoi dati.
- Scopri i carichi di lavoro intensivi di dati: Il primo passo per implementare l'archiviazione a oggetti è identificare i carichi di lavoro e le applicazioni intensivi di dati. Cerca applicazioni che richiedono throughput di streaming, non alti tassi di transazione. Mentre l'archiviazione a oggetti è ideale per set di dati più grandi, pensa se ha senso per le tue esigenze di applicazione e archiviazione dei dati.
- Analizza la prova del concetto: Condurre una prova del concetto è essenziale per identificare la piattaforma di archiviazione a oggetti giusta. Questo ti aiuta a valutare le capacità del fornitore e vedere se soddisfano le tue esigenze. Considera l'uso di macchine virtuali per test non distruttivi per garantire il successo del progetto.
- Preparati per il guasto del dispositivo: Molti fornitori di archiviazione cloud offrono 1 petabyte (PB) in un unico dispositivo. Questi dispositivi ti proteggono dalla perdita di dati e offrono prezzi convenienti, ma di solito richiedono un tempo di ricostruzione più lungo dopo un incidente di guasto del dispositivo. Ecco perché è meglio dividere i grandi server in nodi indipendenti. Potresti anche considerare configurazioni di cluster abilitate alla codifica di cancellazione che rendono i dispositivi resilienti ai guasti.
- Soddisfa le esigenze degli utenti: Con i sistemi di archiviazione a oggetti, puoi consolidare utenti e applicazioni in un ambiente condiviso su un unico sistema. Gli utenti hanno bisogno di diversi livelli di servizio insieme alla capacità di archiviazione e alla sicurezza. Sfruttare la qualità del servizio (QoS) e la multi-tenancy ti aiuterà a soddisfare queste esigenze.
- Sfrutta il potere dei metadati ricchi: I metadati facilitano il processo di analisi dei dati e l'estrazione di informazioni da un database di archiviazione a oggetti. Ecco perché è cruciale sfruttare i tag di metadati integrati per rendere i pool di archiviazione e i set di dati ricercabili.
- Automatizza il flusso di lavoro con le integrazioni: Le soluzioni a oggetti di solito si basano su S3 API per regolare come le applicazioni controllano i dati. Ora, S3 API viene fornito con oltre 400 verbi che possono gestire senza problemi diverse funzioni relative a reportistica, gestione e integrazioni. Le organizzazioni dovrebbero sfruttare questa funzionalità dell'archiviazione a oggetti e lavorare con DevOps per automatizzare i flussi di lavoro.
Casi d'uso del software di archiviazione a oggetti cloud
Ciò che rende le opzioni di archiviazione a oggetti la prima scelta per l'archiviazione aziendale è la loro capacità di memorizzare grandi quantità di dati non strutturati in un pool piatto. Ecco le industrie che continuano a sfruttare l'archiviazione a oggetti tramite servizi cloud:
- Media e intrattenimento: Grazie alla sua scalabilità, le industrie dei media utilizzano l'archiviazione a oggetti per memorizzare e gestire un gran numero di file multimediali e risorse multimediali. La presenza di metadati rende più facile per le organizzazioni identificare e accedere a questi file al momento dell'urgenza.
- Big data: Contenendo set di dati diversi e grandi, i big data difficilmente si adattano ai database. Ecco perché le organizzazioni che sfruttano l'analisi dei big data preferiscono utilizzare l'archiviazione a oggetti. La natura scalabile dell'archiviazione a oggetti consente loro di memorizzare petabyte di dati di reti neurali e apprendimento automatico per addestrare modelli.
- Sanità: Le organizzazioni sanitarie devono memorizzare grandi quantità di dati, mantenerli sicuri e conformarsi alle normative sulla protezione dei dati come il Regolamento generale sulla protezione dei dati (GDPR) e il California Consumer Privacy Act (CCPA). Devono anche memorizzare dati che potrebbero non essere frequentemente accessibili e fornire una visione uniforme dei dati dei pazienti ai medici. L'archiviazione a oggetti basata su cloud a basso costo soddisfa facilmente tutti questi requisiti.
- Archiviazione intensiva di dati: Le organizzazioni che si occupano di servizi di file o database dei clienti beneficiano anche dell'archiviazione a oggetti. La natura del loro business richiede loro di semplificare l'archiviazione dei dati in un modo facilmente accessibile. L'archiviazione a oggetti è la soluzione ideale che soddisfa tutti questi requisiti.
- Archiviazione come servizio: L'archiviazione a oggetti è anche la soluzione di archiviazione preferita per le aziende che cercano AWS S3 o archiviazione compatibile con S3. La maggior parte di queste aziende non vuole implementare sistemi di archiviazione locali o cerca funzioni avanzate come multi-tenancy, controlli di qualità del servizio e così via. E questo fa il caso per l'adozione del protocollo o API S3.
- Backup e recupero: Alcune organizzazioni utilizzano anche l'archiviazione a oggetti per scopi di backup e recupero dei dati. Lo fanno per evitare la perdita di dati eseguendo il backup su nodi in diversi data center. Tali organizzazioni dovrebbero cercare la funzionalità WORM quando scelgono un fornitore di archiviazione dati cloud.
- Archiviazione a freddo: A seconda della natura del loro business, le organizzazioni potrebbero anche aver bisogno di memorizzare dati inattivi che non vengono frequentemente accessi. Questa raccolta di dati è nota come archiviazione a freddo. Le soluzioni di archiviazione a oggetti sono convenienti quando si tratta di memorizzare questo tipo di dati.
- Archiviazione di artefatti: Gli artefatti sono raccolte di log e file di versione generati durante il ciclo di vita di un'applicazione. Le organizzazioni spesso preferiscono memorizzare questi artefatti per ulteriori test. Il metodo di distribuzione degli URL unici dell'archiviazione a oggetti rende più facile per gli sviluppatori memorizzare e accedere a questo tipo di file.
Software di archiviazione a oggetti
Scegliere il giusto software di archiviazione a oggetti è fondamentale per memorizzare dati non strutturati scalabili. Se stai cercando funzionalità robuste che consentano flessibilità, prestazioni e maggiore capacità, lascia che il software di archiviazione basato su oggetti faccia il lavoro pesante.
Per essere inclusi in questa categoria, il prodotto software deve:
- Memorizzare dati non strutturati e metadati rilevanti
- Facilitare il recupero dei dati tramite API o HTTP/HTTPS
- Essere offerto da fornitori di servizi cloud
*Di seguito sono riportate le 5 principali soluzioni di software di archiviazione a oggetti dal Grid® Report di G2 dell'autunno 2021. Alcune recensioni possono essere modificate per chiarezza.
1. Amazon Simple Storage Service (S3)
Amazon Simple Storage Service (S3) viene fornito con un'interfaccia di servizi web semplice che ti consente di memorizzare e recuperare dati da qualsiasi parte del web. È noto per la sua scalabilità, affidabilità e infrastruttura economica.
Cosa piace agli utenti:
“Possiamo memorizzare i nostri dati e accedervi in qualsiasi momento. Possiamo creare molti utenti IAM e fornire loro accesso. Possiamo accedere al sito tramite mobile. Possiamo creare un sito di ambiente di test e condividere l'URL con il cliente. Il team di supporto S3 è molto tecnico. Ti aiutano e assistono se ne hai bisogno. La loro sicurezza è ottima. I dati dei nostri clienti sono sempre al sicuro e possiamo scaricarli in qualsiasi momento.”
- Recensione Amazon S3, Atul S.
Cosa non piace agli utenti:
“È un po' complesso quando configuriamo AWS S3 per la prima volta poiché dobbiamo creare un bucket tramite la console, impostare le politiche, scegliere tra varie impostazioni, un po' di mal di testa per i principianti. Il problema principale che personalmente sento con AWS è che giocare con le impostazioni di AWS S3 senza conoscenze avanzate finisce per far trapelare i file su internet o non servire affatto.”
- Recensione Amazon S3, Heena M.
2. Google Cloud Storage
Google Cloud Storage offre un'archiviazione a oggetti affidabile e sicura con funzionalità come opzioni di ridondanza multiple, trasferimento dati facile, classi di archiviazione e altro ancora. Consente anche la configurazione dei dati utilizzando la gestione del ciclo di vita degli oggetti (OLM).
Cosa piace agli utenti:
“Google Cloud Storage è una piattaforma di archiviazione fantastica che ha prestazioni di alta classe, affidabilità e grande convenienza per tutte le mie esigenze di archiviazione. Nella mia posizione di lavoro, dove devo gestire molti dati, è molto facile spostare i dati nel processo di analisi con l'aiuto di Google Cloud Storage utilizzando BigQuery e API per l'estrazione dei dati.”
- Recensione Google Cloud Storage, Kelly T.
Cosa non piace agli utenti:
“I dati possono finire nelle mani di terze parti. La sicurezza è responsabilità dell'azienda, qualcosa che può portare problemi all'utente in caso di fallimenti. Il controllo totale dell'accesso ai dati non è disponibile. È necessario l'accesso a internet in ogni momento.”
- Recensione Google Cloud Storage, Corbet T.
3. Azure Blob Storage
Azure Blob Storage è una soluzione di archiviazione a oggetti scalabile ideale per il calcolo ad alte prestazioni, applicazioni cloud-native e apprendimento automatico. Consente l'accesso ai dati da qualsiasi luogo tramite HTTP/HTTPS.
Cosa piace agli utenti:
“Blob storage è la soluzione di archiviazione principale su Microsoft Azure. Ha molte integrazioni e casi d'uso. Le caratteristiche principali sono la capacità infinita, diversi tipi di ridondanza a seconda delle tue esigenze e budget, e gli endpoint di rete virtuale.
La politica di accesso flessibile basata su token SAS ti consente di dare accesso permanente e temporaneo senza la necessità di revocarlo manualmente. Molti strumenti possono accedere agli account di archiviazione, puoi persino aprirlo in SQL Server Management Studio e gestire i tuoi dati attraverso di esso. Velocità incredibile, i BLOB sono molto più veloci anche dei dischi SSD locali delle VM di Azure.”
- Recensione Azure Blob Storage, Gleb M.
Cosa non piace agli utenti:
“L'amministrazione è un po' complicata. Ora c'è un RBAC ma in precedenza c'erano solo i token SAS. Non c'è un modo semplice per utilizzare un dominio personalizzato con certificati SSL - bisogna usare CDN.”
- Recensione Azure Blob Storage, Aleksander K.
4. DigitalOcean Spaces
DigitalOcean Spaces è una soluzione di archiviazione a oggetti compatibile con S3 che viene fornita con una rete di distribuzione dei contenuti (CDN) integrata e un'interfaccia utente (UI) o API drag-and-drop per creare uno spazio di archiviazione affidabile.
Cosa piace agli utenti:
“DigitalOcean Spaces è uno strumento fantastico per memorizzare immagini e file per le tue applicazioni. È facile da integrare con applicazioni basate su Java utilizzando Amazon SDK. È molto facile da usare e accedere utilizzando l'interfaccia utente di DigitalOcean. È anche conveniente per un singolo sviluppatore. Lo uso per la mia applicazione ogni giorno.”
- Recensione DigitalOcean Spaces, Sonam S.
Cosa non piace agli utenti:
“Qualcosa che non mi piace degli spazi è l'interfaccia utente. Inoltre, potresti affrontare interruzioni a volte con lo spazio. Potresti dover controllare occasionalmente la pagina di stato di DigitalOcean.”
- Recensione DigitalOcean Spaces, Sachin A.
5. IBM Cloud Object Storage
IBM Cloud Object Storage offre un'archiviazione cloud scalabile ed economica per dati non strutturati. Viene fornito con funzionalità come trasferimento file ad alta velocità, servizi integrati, offerte cross-region e altro ancora.
Cosa piace agli utenti:
“Mi piace l'opzione di classe di archiviazione di IBM Cloud Object Storage. IBM fornisce quattro tipi di opzioni di archiviazione come Active (Standard), Smart Tier, Cool (Vault), Cold Vault. Nella nostra azienda, ogni membro del team IT possiede un account cloud IBM e utilizza diversi servizi in base al proprio lavoro. Come membro del team di sicurezza informatica, monitoro il sistema e memorizzo i dati di log sul tier attivo di IBM.
Più importante, l'azienda ha backup sul servizio Cold Vault di IBM. L'ho testato e posso dire che è sicuro e robusto per la nostra azienda. Il processo di migrazione è stato facile e veloce grazie al desk di supporto di IBM. Hanno fatto davvero un buon lavoro. Durante i miei test di sicurezza, il servizio di IBM è stato il migliore tra i servizi cloud. La performance del controllo di conformità è stata la migliore.”
- Recensione IBM Cloud Object Storage, Nikola M.
Cosa non piace agli utenti:
“Ho trovato un paio di volte che il sistema si bloccava e mi costringeva a ricaricare i dati da memorizzare.”
- Recensione IBM Cloud Object Storage, Matthew B.
Memorizza i dati in modo sostenibile con capacità multi-petabyte
Le esigenze di archiviazione dei dati moderni devono raggiungere la permanenza, la disponibilità, la scalabilità e la sicurezza (PASS) per memorizzare e gestire grandi volumi di dati non strutturati. Le soluzioni di archiviazione a oggetti cloud non solo soddisfano tutti questi requisiti, ma vengono anche senza il peso del costo. Ecco perché le organizzazioni stanno sempre più sfruttando il software di archiviazione a oggetti per creare cloud pubblici, privati o aziendali.
Scopri di più su come scegliere il giusto fornitore di archiviazione cloud per scalare l'archiviazione dei dati non strutturati rimanendo economici.

Sudipto Paul
Sudipto Paul leads the SEO content team at G2 in India. He focuses on shaping SEO content strategies that drive high-intent referral traffic and ensure your brand is front-and-center as LLMs change the way buyers discover software. He also runs Content Strategy Insider, a newsletter where he regularly breaks down his insights on content and search. Want to connect? Say hi to him on LinkedIn.

