
Shreya Mattoo
Shreya Mattoo is a former Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.
Gli esseri umani sono dotati di visione periferica; ma i computer stanno raggiungendo la competenza con il rilevamento degli oggetti ora.
Sia che si tratti di Tesla Autopilot o di aspirapolvere Deebot, i dispositivi informatici sono alimentati con nuovi algoritmi di intelligenza artificiale generativa per accelerare le capacità di elaborazione e nominare gli oggetti fisici. Conosciuto in sintesi come rilevamento degli oggetti, questa simulazione visiva progettata con software di riconoscimento delle immagini ha passato il testimone della visione e della vista ai computer.
Lo scopo principale del rilevamento degli oggetti è segmentare, localizzare e annotare oggetti fisici o digitali con precisione infallibile per completare un compito designato.
Il rilevamento degli oggetti ha aperto nuove strade per l'assistenza robotica, mirata alla produzione di dispositivi auto-assistiti per facilitare compiti tediosi. Impariamo di più su questo in dettaglio.
Cos'è il rilevamento degli oggetti?
Il rilevamento degli oggetti è un approccio di intelligenza artificiale ristretta che identifica, classifica e localizza oggetti in fotografie digitali o video. L'obiettivo principale del rilevamento degli oggetti è rilevare le istanze di ciascun oggetto, segmentarle e analizzare le loro caratteristiche necessarie per la categorizzazione in tempo reale e la modularità approfondita.
Il rilevamento degli oggetti fa parte dell'architettura complessiva del database di un'azienda. Alcune aziende hanno adottato con successo questa tecnologia mentre altre stanno aspettando di annunciarla come una tecnica di gestione del database di successo.
Esempi principali di rilevamento degli oggetti includono sicurezza e sorveglianza, controllo degli accessi, presenza biometrica, monitoraggio delle condizioni stradali, macchine auto-assistite e protezione dei confini marini.
Come funziona il rilevamento degli oggetti?
Il rilevamento degli oggetti funziona in modo simile al riconoscimento degli oggetti. L'unica differenza è che il riconoscimento degli oggetti è il processo di identificazione della categoria corretta dell'oggetto, mentre il rilevamento degli oggetti rileva semplicemente la presenza e la posizione dell'oggetto in un'immagine.
I compiti di rilevamento degli oggetti possono essere eseguiti utilizzando due diverse tecniche di analisi dei dati.
- Elaborazione delle immagini è una parte dell'apprendimento non supervisionato che non richiede dati di addestramento storici per insegnare ai modelli analitici. I modelli si auto-addestrano sulle immagini di input e creano mappe delle caratteristiche per fare previsioni. L'elaborazione delle immagini non richiede un'elevata potenza di elaborazione grafica o grandi set di dati per l'esecuzione.
- Rete neurale profonda: Una rete neurale profonda è generalmente un algoritmo di apprendimento supervisionato che richiede grandi set di dati e un'elevata potenza di calcolo GPU per prevedere le classi di oggetti. È un modo più accurato per classificare oggetti parzialmente nascosti, complessi o posizionati in sfondi sconosciuti in un'immagine.
Formare una rete neurale profonda è un compito laborioso e costoso. Tuttavia, alcuni set di dati su larga scala forniscono la disponibilità di dati etichettati.
Sapevi che? COCO, un set di dati su larga scala per il rilevamento, la segmentazione e la didascalia degli oggetti, può essere utilizzato per addestrare una rete neurale profonda.
Alcune caratteristiche che puoi aspettarti da MS COCO:
- Segmentazione degli oggetti
- Riconoscimento nel contesto
- Segmentazione delle cose superpixel
- Preaddestrato su 33.000 immagini
- 1,5 milioni di istanze di oggetti
- 80 classi di oggetti
- 91 categorie di cose
- 5 didascalie per immagine
- 250.000 persone con punti chiave
Vuoi saperne di più su Software di Riconoscimento Immagini? Esplora i prodotti Riconoscimento delle immagini.
Importanza del rilevamento degli oggetti
Avendo compreso la metodologia di lavoro, è tempo di discutere cosa rende importante il rilevamento degli oggetti.
Il rilevamento degli oggetti costituisce la base per altre importanti tecniche di visione artificiale, come la classificazione delle immagini, il recupero delle immagini, l'elaborazione delle immagini o la co-segmentazione degli oggetti, che estraggono informazioni significative dagli oggetti della vita reale. Sviluppatori e ingegneri stanno utilizzando queste tecniche per costruire macchine futuristiche che consegnano generi alimentari e medicinali alle nostre porte!
Un algoritmo di rilevamento degli oggetti può rilevare automaticamente i movimenti del bestiame, i segnali stradali e le corsie stradali in modo che i veicoli a guida autonoma possano raggiungere le loro destinazioni. Questo, a sua volta, elimina la necessità per i conducenti di svolgere commissioni logistiche.

Il rilevamento degli oggetti può anche funzionare su reti mobili potando i livelli di una rete neurale profonda. Viene già utilizzato negli scanner di sicurezza o nei metal detector negli aeroporti per rilevare oggetti indesiderati e illegali.
Oltre a questo, le aziende utilizzano il rilevamento degli oggetti per il conteggio delle persone, il riconoscimento delle targhe, il riconoscimento vocale e il rilevamento delle prove. Tuttavia, una leggera mancanza di precisione a volte ne ostacola l'efficienza nel rilevare oggetti minuti. Una mancanza di precisione al cento per cento lo rende meno preferibile per domini critici come l'estrazione mineraria e il militare.
Classificazione delle immagini vs. rilevamento degli oggetti
Il rilevamento degli oggetti viene spesso confuso con la classificazione delle immagini. Sebbene siano i lati dello stesso cubo di Rubik, ecco alcune differenze notevoli.
-png.png)
Classificazione delle immagini è un concetto semplice di categorizzazione di un'immagine multispettrale in base ai suoi componenti. Se ti viene data un'immagine di un cane, il modello di classificazione delle immagini può interpretare le sue caratteristiche principali ed etichettare facilmente l'immagine come "cane". Se un'immagine contiene due oggetti, come un gatto e un cane, il modello utilizza un classificatore multi-etichetta per classificare entrambi questi oggetti.
Il modello di classificazione delle immagini non accetta alcuna variabile per la localizzazione degli oggetti oltre a definire la classe dell'oggetto. È qui che entra in gioco il rilevamento degli oggetti.
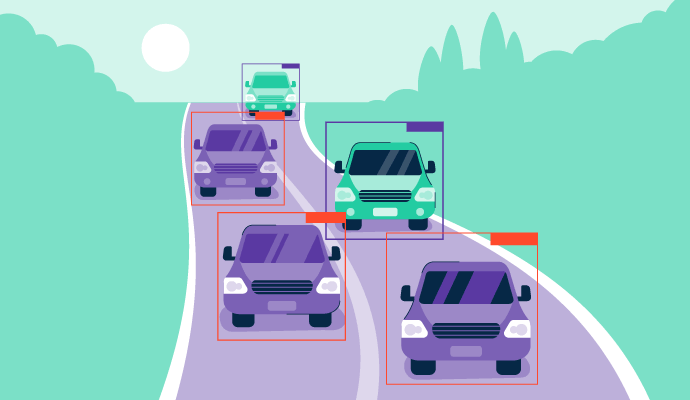
Un algoritmo di rilevamento degli oggetti può identificare la classe dell'oggetto e prevedere l'esatta posizione degli oggetti in un'immagine disegnando riquadri di delimitazione attorno ad essi. È una combinazione di classificazione delle immagini e localizzazione degli oggetti che consente al sistema di sapere dove sono posizionati gli oggetti in un'immagine e perché. Consente a un sistema di analizzare visivamente ogni oggetto e determinarne l'applicazione nella vita reale, proprio come fanno gli esseri umani.
Modelli di rilevamento degli oggetti
Gli approcci più preferiti per il rilevamento degli oggetti sono il machine learning o il deep learning. Entrambi i metodi funzionano in combinazione con una macchina a vettori di supporto (SVM) per estrarre le caratteristiche, addestrare l'algoritmo, e categorizzare gli oggetti.
Il rilevamento degli oggetti non è possibile senza un dataset adeguato. I dataset coprono le principali caratteristiche note di un oggetto, come posizione, dimensioni, categoria o colori. In pratica, se un modello di rilevamento degli oggetti è preaddestrato su un dataset di qualcosa con ruote, un parabrezza, indicatori di direzione, un motore e un bagagliaio, può classificare accuratamente l'oggetto nell'immagine data come un'auto.
Diversi tipi di metodi di rilevamento degli oggetti hanno diversi livelli di efficacia e applicabilità nei vari settori. Comprendiamo questo in dettaglio:
Machine learning
Il punto a favore dell'utilizzo di un algoritmo di machine learning per eseguire il rilevamento degli oggetti è che si basa su dati inseriti manualmente per la classificazione, non su dati di addestramento automatici. Questo rende l'algoritmo complessivo meno soggetto a errori e più stabile.
Il rilevamento degli oggetti è un problema di machine learning supervisionato, il che significa che devi utilizzare modelli preaddestrati per attivare i rilevatori di oggetti. L'elenco delle classi nel dataset di addestramento di un algoritmo ML deve appartenere a un'immagine specifica o a un elenco di immagini.
Approcci di machine learning come il natural language processing (NLP) identificano e classificano gli oggetti in base alla loro intensità di illuminazione rispetto a uno sfondo. Gli algoritmi ML per oggetti 2D possono anche essere riutilizzati per rilevare oggetti 3D nelle immagini.
Caratteristiche del canale aggregato (ACF)
ACF è un metodo di machine learning che riconosce oggetti specifici in un'immagine basandosi su un dataset di immagini di addestramento e sulle posizioni a terra degli oggetti. Viene utilizzato principalmente per il rilevamento di oggetti multi-vista, come l'identificazione di oggetti 3D catturati da tre rig di telecamere. Veicoli auto-assistiti, rilevamento dei pedoni e rilevamento del volto funzionano su questo principio.
ACF combina diversi canali che estraggono caratteristiche da un'immagine come gradienti o pixel piuttosto che ritagliare un'immagine in varie posizioni. I canali comuni includono scala di grigi o RBG, a seconda della difficoltà del problema di rilevamento degli oggetti. ACF ti offre una comprensione più ricca degli oggetti e accelera la velocità di rilevamento per una maggiore precisione.
Consiglio: Per creare un rilevatore di oggetti ACF, dichiara e definisci una funzione di programmazione MATLAB, "trainACFObjectDetector()" e carica le immagini di addestramento. Testa l'accuratezza del rilevamento su un'immagine di test separata.
Rilevamento degli oggetti DPM
Il modello delle parti deformabili (DPM) è un approccio di machine learning che riconosce gli oggetti con una miscela di modelli grafici e parti deformabili dell'immagine. Contiene quattro componenti principali:
- Un filtro radice grossolano definisce diversi riquadri di delimitazione in un'immagine per catturare gli oggetti.
- I filtri delle parti coprono i frammenti degli oggetti e li trasformano in frecce di pixel più scuri.
- Un modello spaziale memorizza la posizione di tutti i frammenti degli oggetti rispetto ai riquadri di delimitazione nel filtro radice.
- Un regressore riduce la distanza tra i riquadri di delimitazione e la verità a terra per prevedere accuratamente gli oggetti.

Fonte: lilianweng.github.io/
Consiglio: Estrarre caratteristiche importanti di oggetti salienti può essere utile durante la raccolta di dati dai cantieri per monitorare i progressi del lavoro o applicare salute e sicurezza ambientale durante il lavoro.
Deep learning
Mentre i modelli di machine learning sono costruiti sulla selezione manuale delle caratteristiche, i flussi di lavoro di deep learning vengono forniti con la selezione automatica delle caratteristiche per adattarsi al tuo stack tecnologico. Gli approcci di deep learning come i modelli di reti neurali convoluzionali producono previsioni di oggetti più veloci e accurate. Ovviamente, hai bisogno di un'unità di elaborazione grafica (GPU) più potente e di set di dati più grandi per farlo accadere!
Il deep learning viene utilizzato per una varietà di compiti di rilevamento degli oggetti. Le moderne telecamere di sorveglianza video o i sistemi di monitoraggio sono alimentati da reti neurali per rilevare con successo volti o oggetti sconosciuti.
Ecco alcuni approcci di deep learning per affrontare il rilevamento degli oggetti.
You Only Look Once (YOLO)
YOLO è un framework di rilevamento degli oggetti a singolo stadio dedicato alle applicazioni industriali. Il suo design efficiente e le sue alte prestazioni lo rendono adatto all'hardware ed efficiente. È una CNN addestrata su grandi database visivi come image nets e può essere codificata in editor open-source in TensorFlow, Darknet o Python.
YOLO produce rilevamenti di oggetti all'avanguardia a una velocità fulminea di 45 fotogrammi al secondo. Ad oggi, sono state lanciate diverse versioni di YOLO, come YOLOv1, YOLOv2 o YOLOv3, sono state lanciate.
L'ultima versione, YOLOv6, può essere addestrata su dataset personalizzati in PyTorch tramite interfacce di programmazione delle applicazioni (API). Pytorch è un pacchetto Python e una delle forme più preferite di ricerca sul deep learning. YOLOv6 è addestrato esclusivamente per rilevare veicoli in movimento sulla strada.
Sapevi che? YOLO o le reti neurali convoluzionali basate su regioni (R-CNN) utilizzano la funzione di precisione media o mAP(). Confronta un riquadro di delimitazione a terra con un riquadro effettivamente rilevato e restituisce una probabilità o un punteggio di fiducia. Più alto è il punteggio, più accurata è la previsione.
SSD (Single Shot Detector)
SSD è un rilevatore di oggetti personalizzato senza una rete di proposte di regioni specifica (diverse parti di un'immagine raggruppate insieme in una rete) per la previsione degli oggetti. Prevede la posizione e il tipo di oggetto di un'immagine direttamente in un unico passaggio attraverso una gamma di livelli di un modello di deep learning.
SSD è suddiviso in due parti:
1. Backbone
Il backbone della rete di classificazione delle immagini preaddestrata estrae le caratteristiche dall'immagine per identificare l'immagine. Queste reti, come ResNet, sono addestrate su ImageNets (grandi database di immagini) e separate dal livello di classificazione delle immagini interno. Lascia il modello backbone come una rete neurale profonda, addestrata esclusivamente su milioni di immagini per estrarre informazioni semantiche dall'immagine di input preservando la struttura spaziale dell'immagine.
Per ResNet34, il backbone crea mappe delle caratteristiche 256x7x7 per qualsiasi immagine di input.
2. Testa
La testa del modello di rilevamento degli oggetti è solo uno strato cerebrale di rete neurale aggiunto al backbone che aiuta nel processo di regressione finale dell'immagine. Fornisce la posizione spaziale dell'oggetto e la combina con la classe dell'oggetto nelle fasi finali dell'SSD.
Fonte:developers.arcgis.com
Altri componenti importanti
Ecco i componenti importanti che compongono un modello SSD per eseguire il rilevamento degli oggetti in tempo reale.
- Cella della griglia: Proprio come l'algoritmo YOLO, l'algoritmo SSD divide il riquadro di delimitazione in una griglia 5x5. Ogni cella della griglia è responsabile dell'output della forma, della posizione, del colore e dell'etichetta dell'oggetto che contiene.
- Riquadro di ancoraggio: Mentre la CNN divide l'immagine in una griglia, a ciascuna cella della griglia viene assegnato più di un riquadro di ancoraggio. Il modello SSD utilizza una tecnica di corrispondenza dei modelli durante il periodo di addestramento per abbinare il riquadro di delimitazione con ciascun oggetto di verità a terra dell'immagine.

Fonte: pyimagesearch.com
Qui, il riquadro di delimitazione previsto è disegnato in rosso, mentre il riquadro di delimitazione della verità a terra (etichettato a mano) è in verde. Poiché c'è un alto grado di sovrapposizione, questo riquadro di ancoraggio è responsabile dell'identificazione della presenza di oggetti. L'Intersezione su Unione (IoU) qui può essere misurata come
- Rapporto d'aspetto: Ogni oggetto ha una forma e una configurazione diverse. Alcuni sono più rotondi e più grandi, mentre altri sono rimpiccioliti e più corti. L'architettura SSD aiuta a dichiarare i rapporti d'aspetto in anticipo attraverso un parametro di rapporto.
- Livello di zoom: Il parametro di zoom può ingrandire oggetti più piccoli in ciascuna cella della griglia per identificare la loro presenza, categoria e posizione. Ad esempio, se dobbiamo identificare un edificio e un parco da un elicottero, dobbiamo scalare l'algoritmo SSD in modo che rilevi sia gli oggetti più grandi che quelli più piccoli.
- Campo recettivo: Il campo recettivo è definito come il set di pixel in movimento dell'immagine su cui l'algoritmo sta attualmente lavorando. Diversi livelli di un modello CNN calcolano diverse regioni di un'immagine di input. Man mano che si approfondisce, la dimensione dell'oggetto aumenta. Proprio come un microscopio, un modello CNN ingrandisce ogni pixel dell'oggetto per calcolare a quale categoria appartiene.
Intersezione su Unione (IoU): Area di sovrapposizione / Area di unione
EfficientNet
EfficientNet è un'architettura di rete neurale convoluzionale che scala uniformemente tutte le dimensioni di un oggetto prima di rilevarle. Queste reti neurali sono sviluppate a un costo fisso di software applicativo. Sulla disponibilità delle risorse, gli algoritmi EfficientNet possono essere scalati su un dominio applicativo per ottenere migliori risultati di rilevamento degli oggetti.
EfficientNet è considerato uno dei migliori modelli CNN esistenti per il rilevamento degli oggetti poiché ha raggiunto un'accuratezza all'avanguardia su set di dati di apprendimento come Fiori (98,8%) pur essendo 6,1 volte più veloce di altri modelli di rilevamento degli oggetti.
Mask R-CNN
Questo estende Faster R-CNN raggruppando la rete di proposte di regioni e la CNN preaddestrata come AlexNet. Una rete di proposte di regioni è una rete di regioni separate da riquadri di delimitazione. Mask R-CNN estrae caratteristiche dall'immagine e crea mappe delle caratteristiche per rilevare la presenza di oggetti. Genera anche una maschera di alta qualità (riquadro di delimitazione) per ciascun oggetto per separarlo dal resto.
Come funziona Mask R-CNN?
Mask R-CNN è stato costruito utilizzando Faster R-CNN e Fast R-CNN. Mentre Faster R-CNN ha uno strato softmax che biforca gli output in due parti, una previsione di classe e un offset del riquadro di delimitazione, Mask R-CNN è l'aggiunta di un terzo ramo che descrive la maschera dell'oggetto che è la forma dell'oggetto. È distinto dalle altre categorie e richiede l'estrazione delle coordinate grafiche dell'oggetto per prevedere accuratamente la posizione.
Mask R-CNN è una combinazione di due CNN che funziona raggruppando in uno strato di maschera dell'oggetto, noto anche come Regione di Interesse (ROI), parallelamente al localizzatore di riquadri di delimitazione esistente.
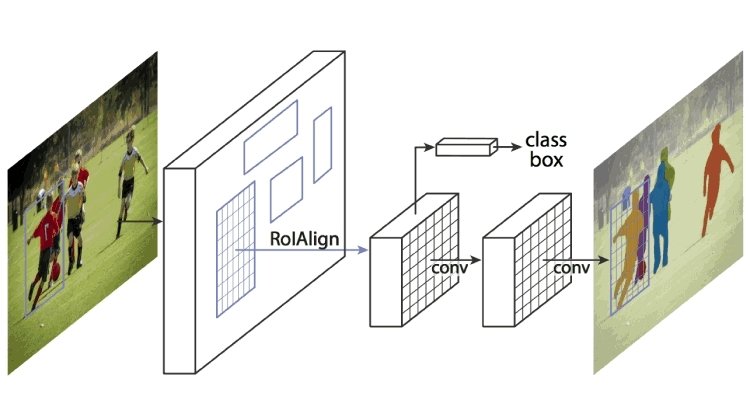
Fonte: viso.ai
Caratteristiche di Mask R-CNN
Discutiamo brevemente alcune caratteristiche.
- È un modello estremamente semplice da addestrare e funziona a una velocità di 5 fotogrammi al secondo (FPS)
- Funziona miracolosamente bene per rilevare volti umani in diverse configurazioni.
- Supera tutte le voci di modello singolo in ogni compito di rilevamento degli oggetti.
- Mask R-CNN può facilmente generalizzare ad altri compiti. Può anche essere utilizzato per stimare le pose umane in un particolare framework.
- Serve come solida base per creare robot auto-assistiti che prevederanno il nostro ambiente futuro.
Tutti gli algoritmi di rilevamento degli oggetti supervisionati dipendono da dataset etichettati, il che significa che gli esseri umani devono applicare la loro conoscenza per addestrare la rete neurale su diversi input. Le mappe delle etichette possono recuperare gli oggetti etichettati in un dataset () funzioni per dedurre la categoria corretta dell'oggetto.
Cosa sono le mappe delle etichette?
La funzione label-map() nella programmazione Tensorflow mappa i numeri di output alla classe dell'oggetto. Se l'output di un algoritmo di rilevamento degli oggetti è 4, questa funzione scansiona i dati di addestramento e restituisce la classe corrispondente al numero "4". Se "4" è menzionato come "aereo", il testo di output sarà "aereo".
Applicazioni del rilevamento degli oggetti nei vari settori
Finora, il rilevamento degli oggetti ha raggiunto traguardi in domini critici come la sicurezza, i trasporti, il settore medico e militare. Le aziende software lo utilizzano per recuperare e categorizzare automaticamente grandi dataset relazionali per aumentare l'efficienza produttiva. Questo processo è anche noto come etichettatura dei dati o annotazione dei dati.
Ecco alcune applicazioni reali che citano l'importanza dei sistemi di rilevamento degli oggetti alimentati dall'IA:
- Polizia e forense: Il rilevamento degli oggetti può tracciare e localizzare oggetti specifici come una persona, un veicolo o uno zaino da fotogramma a fotogramma. Consente agli agenti di polizia e ai professionisti forensi di ispezionare ogni angolo di un sito del crimine per raccogliere prove. Tuttavia, a causa del grande volume di dati, il processo di rilevamento degli oggetti è un po' complicato e richiede ore di filmati per identificare ciò che può contribuire al successo di un caso.
- Checkout senza contatto: Molti ristoranti utilizzano il tracciamento degli oggetti RFID per calcolare l'importo del conto scansionando i piatti vuoti. Questo processo aggiunge automaticamente il prezzo di tutti gli articoli al totale ed elimina le solite transazioni in contanti e con carta di credito in un ristorante.
- Inventario e magazzinaggio: I professionisti della logistica possono facilmente rilevare, classificare e prelevare beni finiti per il trasporto attraverso il rilevamento degli oggetti in tempo reale. Alcune aziende hanno persino sviluppato magazzini automatici per navigare più facilmente tra gli scaffali del magazzino. Può anche automatizzare e regolare la gestione della catena di approvvigionamento tracciando i livelli di inventario per determinare il flusso di produzione ottimale.
- Sistema di parcheggio: I rilevatori visivi preintegrati nelle auto possono rilevare spazi di parcheggio liberi in parcheggi a superficie o garage. Può anche fornire al conducente una vista anteriore e posteriore dello spazio di parcheggio e degli altri veicoli per parcheggiare l'auto in sicurezza.
- Risposta ai disastri: Le recenti fluttuazioni nei nostri ecosistemi, come il deterioramento dello strato di ozono, l'aumento dei gas serra e il riscaldamento globale, hanno spinto sviluppatori e ingegneri a creare applicazioni di rilevamento degli oggetti. Affinando le reti neurali e utilizzando toolkit essenziali, possono essere costruiti modelli veloci e accurati per la risposta e la gestione dei disastri.
- Riconoscimento biometrico e facciale: I controlli di sicurezza aeroportuali impiegano il riconoscimento facciale vicino ai gate di partenza per attestare l'identità dei viaggiatori. I dispositivi di riconoscimento facciale confrontano i documenti di identità con altre tecnologie biometriche, come le impronte digitali, per prevenire frodi e furti d'identità. Durante i trasferimenti internazionali, i dipartimenti di immigrazione e dogana utilizzano i confronti facciali per confrontare il ritratto del viaggiatore con la foto nel passaporto.
Le 5 migliori piattaforme di riconoscimento delle immagini
*Questi sono i 5 principali software di riconoscimento delle immagini basati sul G2 Fall 2024 Grid Report di dicembre 2024

Uno scudo per la visione umana
Il rilevamento degli oggetti non è solo il risultato della generazione di supercomputer; è anche una promessa di un futuro sicuro per l'umanità. Oltre a alimentare le macchine con una visione abilitata dall'IA, ha scoperto, analizzato e districato i nostri problemi mondani meglio di quanto abbiamo fatto noi.
Il rilevamento degli oggetti potrebbe non essere ancora esteso. Ma ha tracciato il percorso iniziale del successo attraverso le catene aziendali. Non si torna indietro da qui.
Esplora come l'IA si sta diffondendo oltre i limiti con il software di sintesi vocale per supportare i non vedenti e migliorare l'accessibilità ai dati.Questo articolo è stato originariamente pubblicato nel 2022. È stato aggiornato con nuove informazioni.