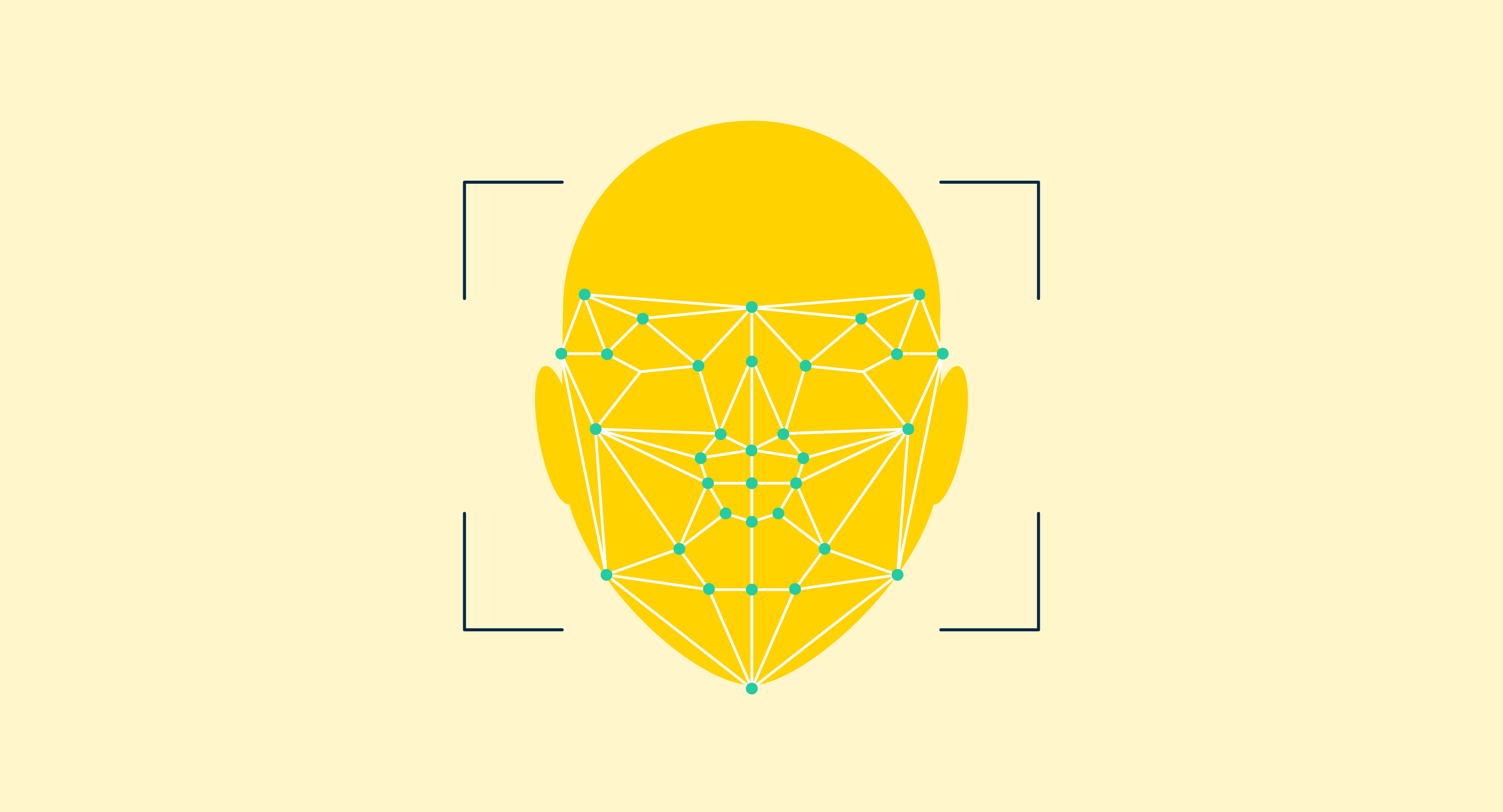
Il nostro mondo è pieno di immagini e, la maggior parte delle volte, noi umani possiamo decifrare esattamente cosa sono quelle immagini e cosa significano abbastanza facilmente. Per i computer, non è così semplice.
Tuttavia, nell'ultimo decennio, i progressi nell'intelligenza artificiale (AI) e nell'apprendimento automatico hanno migliorato significativamente la capacità dei computer di comprendere i contenuti visivi.
Utilizzando strumenti complessi di riconoscimento delle immagini, i computer possono ora identificare diversi elementi all'interno di un'immagine e trasmettere tali informazioni a noi. Di conseguenza, sono molto meglio attrezzati per interpretare e spiegare di cosa tratta un'immagine.
Il riconoscimento delle immagini è una sottocategoria della visione artificiale, un campo più ampio in cui i contenuti visivi vengono identificati e processati nel tentativo di renderli il più simili possibile alla visione e comprensione umana. Man mano che l'AI diventa più sofisticata, così fa anche il software di riconoscimento delle immagini e la sua capacità di comprendere i contenuti visivi.
Cos'è il riconoscimento delle immagini?
Il riconoscimento delle immagini è un processo in cui le macchine identificano oggetti o caratteristiche, come persone o animali, all'interno di un'immagine visiva. Attraverso un processo complesso di analisi dei pixel e delle loro regolarità, modelli, colori e forme, i computer possono determinare cosa rappresenta l'immagine e classificarla in modo simile a come lo farebbe un essere umano.
Come processo a più fasi, il riconoscimento delle immagini comporta la raccolta di dati iniziali su un'immagine, seguita dalla loro elaborazione attraverso la macchina. I dati vengono quindi analizzati rispetto agli esempi del mondo reale su cui la macchina è stata addestrata. Questi set di dati di addestramento sono fondamentali per costruire una base da cui il software di riconoscimento delle immagini può apprendere e rendere il riconoscimento delle immagini future più accurato.
Esempio di riconoscimento delle immagini
Alcuni esempi di riconoscimento delle immagini sono la funzione di auto-tagging di Facebook, l'app Google Lens che traduce immagini o elementi di ricerca, la ricerca per immagini di eBay e l'organizzazione automatizzata di immagini e video in Google Foto. Analizzando i parametri delle immagini, il riconoscimento delle immagini può aiutare a navigare ostacoli e automatizzare compiti che necessitano di supervisione umana.
Un altro semplice esempio di riconoscimento delle immagini è il software di riconoscimento ottico dei caratteri (OCR), che identifica il testo stampato e converte file non modificabili in documenti formattabili. Una volta che lo scanner OCR ha determinato i caratteri nell'immagine, li converte e li memorizza in un file di testo.
È superfluo dire che tutte le tecniche di riconoscimento delle immagini possono essere applicate ai flussi video. Perché, fondamentalmente, un video è costituito da un gruppo di immagini che vengono mostrate rapidamente. Quindi, la tecnica di riconoscimento delle immagini può essere applicata ai video.
Vuoi saperne di più su Software di Riconoscimento Immagini? Esplora i prodotti Riconoscimento delle immagini.
Riconoscimento delle immagini vs. rilevamento degli oggetti
Il riconoscimento delle immagini comporta l'identificazione e la categorizzazione degli oggetti trovati all'interno di un'immagine o video, utilizzando modelli e caratteristiche apprese per determinare accuratamente il contenuto. L'obiettivo è che la macchina identifichi cosa sta accadendo nell'immagine come la percezione umana.
Il rilevamento degli oggetti, d'altra parte, ha un obiettivo più mirato di identificare particolari oggetti all'interno di un'immagine.
In altre parole, il riconoscimento delle immagini interpreta ampiamente il contenuto complessivo di un'immagine, mentre il rilevamento degli oggetti è incaricato di identificare e classificare parti specifiche dell'immagine come definite dall'utente.
Entrambi i processi utilizzano algoritmi di apprendimento automatico per apprendere, elaborare e classificare i vari elementi all'interno di un'immagine. Tuttavia, il loro obiettivo e risultato differiscono leggermente: il rilevamento degli oggetti è più specifico con un ambito di lavoro più ristretto.
Riconoscimento delle immagini vs. visione artificiale
Il riconoscimento delle immagini è una sottocategoria della visione artificiale. Molti usano questi due termini in modo intercambiabile.
-png.png)
La visione artificiale è un campo ampio che include diversi strumenti e strategie che mirano a infondere capacità visive all'interno di macchine e sistemi informatici. Queste tecniche includono il tracciamento degli oggetti, la sintesi delle immagini, la segmentazione delle immagini, la ricostruzione delle scene, il rilevamento degli oggetti e l'elaborazione delle immagini. La tecnica della visione artificiale alimenta diverse innovazioni come l'imaging medico, lo studio degli organi anatomici, le auto a guida autonoma, l'automazione dei processi robotici e l'automazione industriale. L'obiettivo principale è replicare le capacità visive umane all'interno dei sistemi informatici in modo che possano completare più di un compito alla volta riconoscendo il loro stato visivo e aspetto.
Il riconoscimento delle immagini è una sottocategoria all'interno della tecnologia della visione artificiale che si concentra sul rilevamento, la categorizzazione e la ristrutturazione degli elementi delle immagini all'interno di fotografie digitali statiche, video e scenari del mondo reale. Questo software è pre-addestrato su set di immagini con caratteristiche simili a quelle del set di test. L'algoritmo di riconoscimento delle immagini analizza la posizione degli oggetti, estrae le caratteristiche, le invia a un livello di pooling e infine alimenta le caratteristiche a una macchina a vettori di supporto (SVM) per effettuare la classificazione finale. Le applicazioni comuni includono il riconoscimento facciale, l'autenticazione biometrica, l'identificazione dei prodotti e la moderazione dei contenuti.
Tipi di riconoscimento delle immagini
Il riconoscimento delle immagini è tipicamente suddiviso in tre categorie in base a come la macchina è stata addestrata:
- Apprendimento supervisionato. Quando i dati sono etichettati e le categorie per gli elementi delle immagini sono note in anticipo, l'apprendimento supervisionato è l'approccio migliore da utilizzare. Può distinguere diverse categorie, ad esempio "non un gatto" e "un gatto", e riconoscere queste parti dell'immagine.
- Apprendimento non supervisionato. Quando le categorie sono sconosciute e le immagini vengono inserite nella macchina, l'apprendimento non supervisionato riconosce i modelli nei dati. L'analisi dell'immagine si basa su attributi e caratteristiche piuttosto che su categorie o oggetti pre-programmati.
- Apprendimento auto-supervisionato. Quando ci sono alcuni dati etichettati, ma la macchina sta ancora imparando a funzionare con informazioni meno specifiche, l'apprendimento auto-supervisionato può essere un buon approccio da utilizzare. È un sottoinsieme dell'apprendimento non supervisionato, in cui le etichette vengono create durante il processo di analisi. È necessaria una maggiore supervisione in questo passaggio critico di addestramento, poiché determina quanto bene la macchina può riconoscere le immagini future.
All'interno di ciascuna di queste categorie, possono essere utilizzati vari tipi di applicazioni per un riconoscimento delle immagini più esteso e specifico. Questi includono:
- Riconoscimento facciale. Questo tipo specializzato di riconoscimento degli oggetti addestra le macchine a identificare e processare le caratteristiche facciali individuali. Le applicazioni spaziano dalla sicurezza e sorveglianza all'applicazione della legge. Ad esempio, la sicurezza aeroportuale e il controllo delle frontiere ora spesso utilizzano il riconoscimento facciale per confrontare le caratteristiche di un essere umano di fronte alla telecamera con il documento di identità per verificare la loro identità.
- Riconoscimento delle scene. Paesaggi e edifici possono anche essere identificati dal software di riconoscimento delle immagini. Questo può essere utilizzato in vari modi, come veicoli a guida autonoma, sistemi di mappatura o software di gioco come visori di realtà aumentata e virtuale.
- Riconoscimento dei gesti. Sebbene identificare immagini statiche sia una sfida per i computer, riconoscere e valutare i gesti in movimento, in particolare quelli umani, può essere ancora più complesso. Gli strumenti di riconoscimento delle immagini possono essere programmati per leggere e comprendere i movimenti delle mani, le espressioni facciali e altro ancora.
- Riconoscimento ottico dei caratteri (OCR). I caratteri fissi come lettere e numeri sono più facili da decifrare per i computer, in particolare quando la macchina è stata addestrata a rilevare questi elementi visivi e ha categorie pre-assegnate per organizzarli. I documenti scritti a mano potrebbero dover essere scansionati e convertiti in testo digitale. Questa tecnica è uno dei modi più semplici e veloci per digitalizzare le informazioni scritte.
Come funziona il riconoscimento delle immagini?
Perché un computer possa riconoscere immagini e modelli, impiega un processo noto come apprendimento profondo. Questo è una forma di apprendimento automatico in cui le reti neurali profonde replicano i complessi poteri decisionali del cervello umano in un ambiente artificiale.
Queste reti neurali profonde sono composte da tre o più livelli, spesso centinaia o migliaia, che addestrano il modello di software di riconoscimento delle immagini per applicazioni nel mondo reale. Proprio come i nostri cervelli contengono numerosi nodi interconnessi per trasmettere informazioni in tutto il nostro corpo, queste reti informatiche operano in modo comparabile.
Questi nodi nella rete identificano cosa sta vedendo il computer, valutano diverse opzioni e poi forniscono un risultato conclusivo su cosa mostra l'immagine. Addestrare questi nodi è cruciale per la macchina per apprendere e migliorare la sua precisione nel tempo.
La macchina deve essere addestrata utilizzando un ampio set di dati, che la aiuta a imparare e identificare le caratteristiche necessarie di diversi oggetti. Una volta addestrata, il processo di riconoscimento delle immagini segue tipicamente questi sei passaggi:
- Raccolta dati. I dati vengono inseriti nella macchina, di solito in un ambiente di apprendimento supervisionato con immagini etichettate.
- Pre-elaborazione. Prima che inizi l'addestramento, le immagini vengono regolate per rimuovere eventuali distorsioni o interferenze. Questo può comportare il ritaglio, la luminosità o altre regolazioni delle immagini per renderle il più utili possibile per la macchina.
- Estrazione delle caratteristiche. Isolare le parti dell'immagine che devono essere categorizzate è un passaggio essenziale nell'addestramento. Questo aiuta la macchina a distinguere tra le diverse parti del visivo.
- Addestramento del modello. Utilizzando i set di dati etichettati, la rete neurale della macchina viene addestrata ripetutamente fino a quando i modelli e le caratteristiche vengono riconosciuti con un alto livello di precisione. Durante questa fase avvengono l'etichettatura e la segmentazione, fornendo al modello più informazioni per comprendere l'immagine.
- Test del modello. Verranno utilizzati diversi set di dati per continuare l'addestramento e il test dell'algoritmo fino a quando non sarà pronto per il dispiegamento. Questi set di dati probabilmente diventeranno più complessi nel tempo, passando da set di dati etichettati a non etichettati per aiutare la macchina a imparare e diventare più precisa.
- Distribuzione e ri-test. Quando il modello è stato sufficientemente testato e convalidato, può essere distribuito per un uso più ampio.
Ad esempio, la macchina potrebbe ricevere un'immagine di due cani che giocano in un cortile. Il software di riconoscimento delle immagini inizierebbe a identificare gli elementi dell'immagine con la classificazione, separando i cani dallo sfondo. Da lì, potrebbero tornare a etichettare i singoli cani come "cane" e altri elementi nell'immagine, come "albero", "palla" o "recinzione".
Industrie che beneficiano del riconoscimento delle immagini
Le applicazioni aziendali del riconoscimento delle immagini stanno diventando più estese man mano che l'AI e l'apprendimento automatico raggiungono livelli di sofisticazione e precisione senza precedenti. Per i compiti che potrebbero essere automatizzati o richiedere un livello significativo di sforzo umano, il riconoscimento delle immagini può ridurre significativamente sia il tempo che i costi.
Alcune delle industrie che stanno beneficiando di questa tecnologia includono:
- Retail. Il riconoscimento delle immagini nell'industria retail è uno dei modi migliori per migliorare l'esperienza del cliente quando si fa shopping in negozio. Ad esempio, può abbinare abiti a un cliente specifico in base al suo stile attuale. I sistemi di sicurezza possono anche utilizzare il riconoscimento delle immagini per identificare potenziali taccheggiatori o altre minacce alla sicurezza.
- Sanità. I radiologi possono utilizzare il riconoscimento delle immagini per identificare rapidamente e facilmente problemi nelle risonanze magnetiche e in altre immagini mediche, portando a trattamenti più rapidi ed efficaci per i pazienti.
- Agricoltura. Parassiti e malattie possono essere disastrosi per la comunità agricola. Con il software di riconoscimento delle immagini, gli agricoltori possono analizzare la composizione visiva delle colture, permettendo loro di prendere misure correttive prima che i problemi diventino irreversibili.
- Finanza. L'errore umano nella contabilità può essere incredibilmente costoso, ma numerosi compiti nel settore finanziario possono essere automatizzati per risparmiare tempo e denaro. L'elaborazione delle fatture, la gestione delle spese e la convalida delle transazioni finanziarie sono tutti esempi di come il riconoscimento delle immagini può aiutare. Ad esempio, le piccole imprese possono rapidamente scansionare una ricevuta cartacea sul loro telefono e caricarla nel loro software di contabilità. Il riconoscimento delle immagini estrarrà le informazioni nell'immagine per aggiungere automaticamente questi dati di spesa ai loro registri.
- Produzione. I difetti nei prodotti possono essere errori costosi per l'industria manifatturiera. Il riconoscimento delle immagini può trovare questi errori o qualsiasi deviazione dallo standard di qualità tipico. Ad esempio, nel campo della produzione farmaceutica, il riconoscimento delle immagini può facilmente individuare una pillola mancante da un pacchetto prima che il processo di produzione sia completato e il farmaco sia confezionato per la vendita in una quantità errata.
Compiti del software di riconoscimento delle immagini
Il software di riconoscimento delle immagini è alimentato da apprendimento profondo, più precisamente, reti neurali artificiali.
Prima di discutere il funzionamento dettagliato del software di riconoscimento delle immagini, esaminiamo i cinque compiti comuni di riconoscimento delle immagini: rilevamento, classificazione, etichettatura, euristica e segmentazione.
Rilevamento
Il processo di localizzazione di un oggetto in un'immagine si chiama rilevamento. Una volta trovato l'oggetto, viene messo un riquadro attorno ad esso.
Ad esempio, considera un'immagine di un parco con cani, gatti e alberi sullo sfondo. Il rilevamento può comportare la localizzazione degli alberi nell'immagine, di un cane seduto sull'erba o di un gatto sdraiato.
Una volta rilevato l'oggetto, viene posizionato un riquadro attorno ad esso. Ovviamente, gli oggetti possono avere tutte le forme e dimensioni. A seconda della complessità dell'oggetto, vengono utilizzate tecniche come l'annotazione poligonale, semantica e a punti chiave per il rilevamento.
Classificazione
È il processo di determinare la classe o categoria di un'immagine. Un'immagine può avere solo una singola classe. Nell'esempio precedente, se c'è un cucciolo sullo sfondo, può essere classificato come "cani" o semplicemente come immagini di cani. Se ci sono cani di razze o colori diversi, possono anche essere classificati come "cani".
Etichettatura
L'etichettatura è simile alla classificazione ma mira a una maggiore precisione. Cerca di identificare più oggetti in un'immagine. Pertanto, un'immagine può avere uno o più tag. Ad esempio, un'immagine di un parco può avere tag come "cani", "gatti", "umani" e "alberi".
Euristica
L'algoritmo prevede un "euristico" per ogni elemento all'interno di un'immagine, che è un punteggio proiettivo di un elemento appartenente a una specifica categoria di immagine. L'euristico è una misura stimata, solitamente misurata tramite una metrica di distanza come la metrica euclidea o di Minkowski. L'euristico viene quindi confrontato con un valore "tensore", che viene calcolato mediante moltiplicazione incrociata delle proprietà dei dati in un numero di griglie in cui l'immagine è divisa. Il valore euristico stabilisce un obiettivo predeterminato per l'algoritmo di riconoscimento delle immagini da raggiungere.
Segmentazione
La segmentazione delle immagini è un compito di rilevamento che tenta di localizzare oggetti in un'immagine fino al pixel più vicino. È utile in situazioni in cui la precisione è fondamentale. La segmentazione delle immagini è ampiamente utilizzata nell'imaging medico per rilevare e etichettare i pixel delle immagini.
Elaborare un'intera immagine non è sempre una buona idea, poiché può contenere informazioni non necessarie. L'immagine viene segmentata in sotto-parti e le proprietà dei pixel di ciascuna parte vengono calcolate per comprendere la sua relazione con l'immagine complessiva. Altri fattori vengono presi in considerazione, come l'illuminazione dell'immagine, il colore, il gradiente e le rappresentazioni vettoriali facciali.
Ad esempio, se stai cercando di rilevare auto in un parcheggio e segmentarle, i cartelloni pubblicitari o i segnali potrebbero non essere di grande utilità. È qui che la suddivisione dell'immagine in vari segmenti diventa fondamentale. I pixel simili in un'immagine vengono segmentati insieme e ti danno una comprensione granulare degli oggetti nell'immagine.
Vantaggi del riconoscimento delle immagini
Sia per le aziende che per i consumatori, il software di riconoscimento delle immagini ha diversi vantaggi significativi.
Protegge le persone dai crimini online
Oggigiorno, i nostri volti sono ovunque su Internet, insieme a informazioni personali apparentemente infinite. Con gli strumenti di riconoscimento delle immagini, è possibile effettuare ricerche di immagini per verificare l'uso non autorizzato delle tue informazioni per frodi.
Per gli artisti visivi, questo è anche un buon modo per identificare se qualcuno sta rubando o utilizzando in modo improprio la tua opera d'arte.
Elabora i dati rapidamente
Il riconoscimento delle immagini AI può elaborare grandi set di dati esponenzialmente più velocemente di quanto potrebbe fare un essere umano. Questo non solo libera il tuo team per svolgere altri compiti più critici per il business, ma completa anche il lavoro in un tempo molto più rapido.
Soluzioni scalabili per qualsiasi progetto visivo
I sistemi AI hanno una gamma diversificata di applicazioni, il che significa che possono essere utilizzati per quasi tutto. Ciò rende il software di riconoscimento delle immagini una delle opzioni più adattabili e flessibili per qualsiasi tipo di progetto, indipendentemente dalle dimensioni.
Miglior software di riconoscimento delle immagini
Con la sua gamma di capacità, il giusto software di riconoscimento delle immagini dipende dalle tue esigenze specifiche e dai risultati desiderati. La maggior parte degli strumenti può gestire una varietà di input di dati, incluso il miglior software di riconoscimento delle immagini gratuito. Ma per progetti più complessi, il software a pagamento è spesso la scelta migliore.
Per essere inclusi nella categoria del software di riconoscimento delle immagini, le piattaforme devono:
- Fornire un algoritmo di apprendimento profondo specificamente per il riconoscimento delle immagini
- Connettersi con pool di dati di immagini per apprendere una soluzione o funzione specifica
- Consumare i dati delle immagini come input e fornire una soluzione in output
- Integrare le capacità di riconoscimento delle immagini in altre applicazioni, processi o servizi
* Di seguito sono riportate le cinque principali soluzioni di software di riconoscimento delle immagini dal Rapporto Grid di G2 della primavera 2024. Alcune recensioni possono essere modificate per chiarezza.
1. Google Cloud Vision API
Google Cloud Vision API consente agli sviluppatori di sfruttare facilmente la potenza dell'AI e dell'apprendimento automatico per riconoscere e valutare le immagini con una precisione di previsione leader nel settore. Gli strumenti ti permettono di caricare immagini direttamente, con l'API Vision che agisce come un localizzatore di oggetti per rilevare oggetti ed etichette all'interno dell'immagine stessa.
Cosa piace di più agli utenti:
“Stiamo utilizzando l'API in un progetto in cui dobbiamo conoscere il valore nutrizionale del cibo, quindi otteniamo il nome del cibo tramite il riconoscimento delle immagini e poi calcoliamo i suoi nutrienti in base ai contenuti alimentari. È molto facile integrarlo con la nostra applicazione e il tempo di risposta dell'API è anche molto veloce.”
- Recensione di Google Cloud Vision API, Badal O.
Cosa non piace agli utenti:
“A seconda dell'uso, i costi associati all'utilizzo di Google Cloud Vision API possono accumularsi. Gli utenti dovrebbero esaminare attentamente il modello di prezzo e stimare le spese potenziali per i loro casi d'uso specifici.”
- Recensione di Google Cloud Vision API, Piyush D.
2. Syte
Alimentato dall'AI, Syte è la prima piattaforma di scoperta di prodotti al mondo. Con la ricerca tramite fotocamera, la personalizzazione e strumenti di eCommerce intelligenti, le aziende possono aiutare i clienti a scoprire e acquistare prodotti con un'esperienza iper-personalizzata nel loro negozio online.
Cosa piace di più agli utenti:
“Lo strumento di ricerca simile al negozio è stato un ottimo strumento da quando lo abbiamo implementato sui nostri siti. Lo strumento Syte è stato fondamentale nella scoperta dei prodotti e nell'aiutare i clienti a trovare prodotti visivamente simili quando non riescono a trovare la loro taglia.”
- Recensione di Syte, Emely C.
Cosa non piace agli utenti:
“La piattaforma di merchandising backend non è la più intuitiva rispetto ad altre piattaforme. Il "completa il look" non mostra i prodotti esatti come parte del look, solo simili.”
- Recensione di Syte, Cristina F.
3. Carifai
Carifai è una piattaforma AI completa per sviluppatori e team per collaborare su produzioni AI audio e visive. I modelli di apprendimento linguistico personalizzati sono open source, con aggiornamenti frequenti, e possono servire usi multi-modali in una gamma di progetti e industrie.
Cosa piace di più agli utenti:
“Facile da navigare e una vasta selezione di modelli costruiti dagli utenti per iniziare a giocare e imparare. Sembra github ma con AI. Facile per un principiante come me trovare ciò che sto cercando. Iscrizione rapida e facile e puoi iniziare subito senza alcuna fastidiosa chiamata demo o presentazione di vendita prima.”
- Recensione di Clarifai, Tate T.
Cosa non piace agli utenti:
“Potrebbe essere utile avere la libreria di addestramento ulteriormente potenziata poiché i casi d'uso e i modelli sono relativamente nuovi. Sarebbe utile avere walkthrough su come implementare i modelli end-to-end per diversi tipi di modelli.”
- Recensione di Clarifai, Sam G.
4. Gesture Recognition Toolkit
Gesture Recognition Toolkit è una suite di strumenti open-source e cross-platform che consente agli sviluppatori la libertà e la flessibilità di progettare e costruire software di riconoscimento dei gesti in tempo reale. Largamente utilizzato nello sviluppo di giochi e realtà virtuale, gli utenti del toolkit possono creare da zero o lavorare con altri membri della comunità per sfruttare le applicazioni open-source per costruire i loro modelli di apprendimento linguistico.
Cosa piace di più agli utenti:
“Mi piace come è progettato per funzionare con dati sensoriali in tempo reale e allo stesso tempo con il tradizionale compito di apprendimento automatico offline. Mi piace che abbia un float a doppia precisione e possa essere facilmente cambiato in precisione singola, rendendolo uno strumento molto flessibile.”
- Recensione di Gesture, Diana Grace Q.
Cosa non piace agli utenti:
"Ha un ritardo occasionale e un processo di implementazione meno fluido. Il tempo di risposta del supporto clienti potrebbe essere più veloce.
- Recensione di Gesture, Civic V.
5. SuperAnnotate
SuperAnnotate è una piattaforma leader per costruire, addestrare, testare e distribuire modelli AI con dati di addestramento di alta qualità. Strumenti avanzati di annotazione e riconoscimento delle immagini consentono agli utenti di costruire pipeline di apprendimento automatico di successo e gestire carichi di lavoro di automazione.
Cosa piace di più agli utenti:
“SuperAnnotate ha un'interfaccia intuitiva. È stato facile familiarizzare con le diverse funzioni e strumenti che la piattaforma fornisce. È facile navigare tra le migliaia di immagini nel nostro set di dati - sia in modalità di annotazione che al di fuori. Questo è stato molto utile in situazioni in cui ho dovuto trovare immagini specifiche per apportare alcune modifiche al set di dati. Inoltre, la funzione di panoramica delle etichette è utile per rilevare e correggere eventuali incoerenze nelle nostre annotazioni.”
- Recensione di SuperAnnotate, Camilla M.
Cosa non piace agli utenti:
“La piattaforma può fornire più opzioni di filtro per gli account manager e funzioni aggiuntive per gli annotatori per correggere compiti inviati involontariamente.”
- Recensione di SuperAnnotate, Hoang D.

È quasi irriconoscibile...ma non del tutto!
Le immagini visive e i video giocano un ruolo critico nelle nostre vite, sia personalmente che sul posto di lavoro. Avere la tecnologia a portata di mano che può rilevare e valutare questi contenuti visivi in quasi lo stesso modo del cervello umano è un passo significativo nell'intelligenza artificiale, con infinite possibilità su come questi strumenti possono beneficiare le nostre vite quotidiane.
Scopri di più sulle applicazioni AI in modo da poter automatizzare più compiti e funzioni quotidiane nella tua azienda.

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.

