La tecnología avanza a un ritmo rápido, y aunque a veces puede resultar abrumadora, está facilitando nuestras tareas diarias.
Desde pedir nuestro café matutino con un comando de voz hasta encontrar la ruta más rápida a la oficina, estas comodidades se han vuelto algo natural. Pero, ¿y si tus dispositivos pudieran entender e interactuar con el mundo que nos rodea de la misma manera que lo haría un humano?
Con el poder de la inteligencia artificial (IA) y la tecnología de visión por computadora, ahora podemos hacerlo.
¿Qué es "you only look once" (YOLO)?
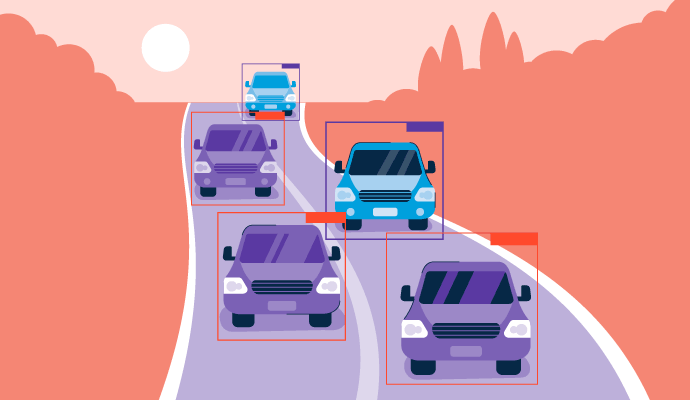
"You only look once", o YOLO, es un algoritmo de detección de objetos en tiempo real desarrollado por primera vez en 2015. Predice la probabilidad de que un objeto esté presente dentro de una imagen o video. Es un algoritmo específico que mejora el campo actual de la detección de objetos en la tecnología de visión por computadora, donde los objetos en las imágenes se localizan e identifican.
YOLO solo necesita revisar el visual una vez para hacer estas predicciones, de ahí su nombre, y también se puede referir como detección de objetos de un solo disparo (SSD). Es una parte importante del proceso de detección de objetos que muchos productos de software de reconocimiento de imágenes utilizan para entender qué está representando el medio visual.
Al usar redes neuronales de extremo a extremo, este algoritmo puede predecir tanto la ubicación (cajas delimitadoras) como la identidad (clasificación) de los objetos en una imagen simultáneamente. Esto fue un salto respecto a los algoritmos tradicionales de detección de objetos, que reutilizaban clasificadores existentes para predecir esta información.
Cómo funciona You Only Look Once
YOLO se basa en una única red neuronal convolucional (CNN), un componente clave del aprendizaje profundo y un tipo de red de IA que filtra las entradas del modelo para buscar patrones reconocibles. Las capas en estas redes están formateadas para detectar primero los patrones más simples, antes de pasar a los más complejos.
Aunque las CNN se utilizan para más que el procesamiento de imágenes, son una parte fundamental de la arquitectura de YOLO. Cuando se introduce una imagen en un modelo basado en YOLO, pasa por varios pasos para detectar objetos dentro de ese visual. Aquí hay un desglose:
- Imagen de entrada: La imagen completa, ya sea una foto estática, un gráfico o un formato de video, se pasa a través del modelo. Las características de la imagen se extraen y se pasan a través de capas conectadas para predecir las clasificaciones y las coordenadas de las cajas delimitadoras.
- División en cuadrícula: La imagen de entrada se divide luego en cajas en una formación de cuadrícula. Cada pequeño cuadrado o celda de la cuadrícula tiene la tarea de detectar objetos dentro de su sección, además de proporcionar un valor de probabilidad o confianza para cualquier objeto detectado.
- Detección de objetos: Si se predice que una cuadrícula contiene un objeto, se destacará como celdas significativas. El modelo luego determina el tipo de objeto y su ubicación dentro de la cuadrícula en un solo paso.
- Puntuación de la caja delimitadora: El modelo dibuja cajas alrededor de los objetos detectados, conocidas como cajas delimitadoras. Cada celda de la cuadrícula puede generar múltiples cajas delimitadoras si hay más de un objeto en esa celda. Las cajas delimitadoras también pueden superponerse a las celdas para abarcar completamente cada objeto en toda la imagen. Se asigna una puntuación de confianza a cada caja delimitadora que representa la probabilidad de que la predicción sea correcta.
- Salida: Después de que se han evaluado los cuadrados de la cuadrícula, la salida final enumerará todos los objetos dentro de la imagen, junto con cada caja delimitadora y su etiqueta. Como parte del post-procesamiento, se llevará a cabo la supresión no máxima (NMS) para eliminar las cajas superpuestas, asegurando que cada objeto esté representado por solo una caja con la puntuación de confianza más alta. Este paso mejora la precisión de la detección de objetos y hace que todo el proceso sea más eficiente al filtrar el ruido adicional para crear una salida más limpia.
¿Quieres aprender más sobre Software de reconocimiento de imágenes? Explora los productos de Reconocimiento de imágenes.
Tipos de YOLO en la detección de objetos
Desde su desarrollo, YOLO ha pasado por varias iteraciones que han incorporado tecnología actualizada y han creado un flujo de trabajo más rápido y eficiente. Aquí hay un breve resumen de YOLO v1-v6 y un vistazo a dónde estamos hoy:
- YOLOv1: El algoritmo original se centró principalmente en la detección de objetos como un problema de regresión en lugar de los enfoques tradicionales de clasificación, lo cual fue innovador en su momento. Esta base todavía se utiliza en los modelos YOLO hoy en día.
- YOLOv2: También conocido como YOLO 9000, esta versión se basó en los conceptos originales de YOLO y abordó algunas de las limitaciones del primer modelo. Se introdujeron cajas de anclaje como cajas predeterminadas dentro de la cuadrícula, con proporciones y escalas únicas. Esto hizo que predecir las cajas delimitadoras fuera más fácil y se ajustara mejor a los objetos reales en la imagen. La versión también incluyó actualizaciones para manejar imágenes de mayor resolución sin ralentizar los tiempos de procesamiento.
- YOLOv3: Esta versión introdujo una técnica conocida como "red de pirámide de características" (FPN), que se utilizó para detectar objetos de diferentes tamaños dentro de la imagen. La velocidad de procesamiento también se incrementó en la tercera versión de YOLO mediante el uso de Darknet-53.
- YOLOv4: Con una versión actualizada de Darknet, CSPDarnet, la cuarta versión de YOLO fue significativamente más rápida y precisa que las iteraciones anteriores. La precisión mejoró en alrededor de un 0.5% en promedio gracias a la introducción de una técnica conocida como "conexión parcial de estado cruzado" o CSP, donde se introdujeron múltiples modelos al mismo tiempo para combinar sus habilidades de predicción.
- YOLOv5: Introducido en 2020, la quinta versión de YOLO introdujo una arquitectura de red neuronal actualizada llamada EfficientDet. EfficientDet fue una serie de modelos de clasificación de imágenes diseñados para mejorar la precisión computacional y el uso de memoria mientras se lograban los niveles más altos de precisión de salida. Las cajas de anclaje ya no eran necesarias con la versión 5, con una sola capa convolucional capaz de predecir cajas delimitadoras de objetos directamente, sin importar su forma o tamaño.
- YOLOv6: La introducción de una nueva red neuronal más ligera significó que la versión 6 de YOLO funcionaba de manera más eficiente y con menos recursos necesarios. También se introdujo la aumentación de datos durante el entrenamiento, lo que permite al modelo reconocer objetos incluso cuando están volteados, rotados o escalados en la imagen de entrada.
Las actualizaciones más recientes de YOLO, versiones 7 a 9, han continuado viendo mejoras en velocidad y precisión a medida que el algoritmo se adapta en función de los avances actuales en aprendizaje profundo. La capacidad de aprendizaje del algoritmo ha aumentado significativamente con estos modelos más nuevos, permitiendo que la detección de objetos sea posible incluso con datos de imagen borrosos o incompletos.
Industrias que utilizan You Only Look Once
Hay numerosas formas en que YOLO puede implementarse en la vida cotidiana, pero algunas industrias se benefician más de esta tecnología que otras.
Seguridad
Los sistemas de vigilancia se vuelven más complejos cada año, ayudando a mantenernos seguros dondequiera que estemos. YOLO se utiliza a menudo para detectar individuos que son monitoreados por las fuerzas del orden a través de sistemas de CCTV y cámaras de seguridad, mientras también se monitorean delitos como el hurto en tiendas o asaltos que ocurren en tiempo real.
Salud
Al igual que otras formas de detección de objetos y reconocimiento de imágenes, YOLO puede utilizarse en la atención médica en tiempo real y en el tratamiento de imágenes. Varios estudios han encontrado un uso generalizado de YOLO en toda esta industria, incluidas las intervenciones quirúrgicas donde la detección de órganos es necesaria debido a la diversidad biológica de diferentes pacientes.
Tanto los escaneos 2D como 3D pueden localizar rápida y precisamente la colocación de órganos, proporcionando información sobre posibles problemas que la imagen médica está destinada a detectar.
Agricultura
El desarrollo de la IA ha ayudado significativamente a la industria agrícola, permitiendo a los agricultores monitorear sus cultivos en todo momento sin la necesidad de supervisión manual. YOLO y la robótica agrícola han reemplazado la recolección y cosecha manual en muchos casos. También se utiliza para identificar cuándo los cultivos están en su punto máximo de madurez para la recolección, basándose en características de color o tamaño de los objetos (cultivos) en las imágenes.
Vehículos autónomos
Para los coches autónomos, YOLO ayuda a identificar señales de tráfico, peatones y otros peligros en la carretera con velocidad y precisión, al igual que lo haría un conductor humano.
Beneficios de YOLO
Hay numerosos beneficios que vienen con el uso de algoritmos como YOLO en modelos de IA para la detección de objetos, particularmente en velocidad y precisión.
- Aplicaciones en tiempo real: Para industrias donde la gestión del tiempo y la reactividad rápida son esenciales, como los coches autónomos y la seguridad, YOLO es una de las mejores opciones automatizadas para detectar objetos en una imagen o video.
- Altos niveles de precisión: Con cada nueva versión de YOLO, el algoritmo se vuelve más preciso en la detección de objetos con confianza en las cajas delimitadoras de salida. Tanto las clasificaciones como las ubicaciones de los objetos en las imágenes son más precisas cada vez.
- Eficiencia de un solo disparo: En lugar de esperar a que las imágenes pasen por varias capas de una red neuronal, YOLO puede procesar la información en un solo paso para mejorar su eficiencia y velocidad general.
- Capacidad para evaluar imágenes de diferentes escalas: YOLO ahora es capaz de procesar imágenes con diferentes proporciones de aspecto y determinar objetos de diferentes tamaños dentro de modelos que utilizan cajas de anclaje, así como aquellos que no las utilizan.
Principales herramientas de reconocimiento de imágenes utilizadas para You Only Look Once
YOLO puede usarse solo para un rol específico en el reconocimiento de imágenes, la detección de objetos, pero estas herramientas pueden añadirse a los flujos de trabajo para completar muchas más tareas. La detección de objetos es solo una parte de cómo se procesan las imágenes utilizando IA, con aspectos como la restauración de imágenes y la reconstrucción de escenas también posibles con este software.
Para ser incluido en la categoría de reconocimiento de imágenes, las plataformas deben:
- Proporcionar un algoritmo de aprendizaje profundo específicamente para el reconocimiento de imágenes
- Conectarse con grupos de datos de imágenes para aprender una solución o función específica
- Consumir los datos de imagen como una entrada y proporcionar una salida
- Proporcionar capacidades de reconocimiento de imágenes a otras aplicaciones, procesos o servicios
* A continuación se presentan las cinco principales soluciones de software de reconocimiento de imágenes del Informe de Verano 2024 de G2. Algunas reseñas pueden estar editadas para mayor claridad.
1. Google Cloud Vision API
Google Cloud Vision API es capaz de detectar y clasificar múltiples objetos dentro de imágenes utilizando un algoritmo preentrenado que puede adaptarse a tus propios modelos. Este software ayuda a los desarrolladores a utilizar el poder del aprendizaje automático con una precisión de predicción líder en la industria.
Lo que más les gusta a los usuarios:
"Lo más útil que he experimentado sobre esta herramienta particular de Vision API de Google es su integración de características de detección en nuestros proyectos de aprendizaje profundo y de máquinas. Su API nos está ayudando a detectar cualquier objeto y etiquetarlo con comprensión humana y formar un modelo de aprendizaje automático."
- Reseña de Google Cloud Vision API, Kunal D.
Lo que no les gusta a los usuarios:
"Para imágenes de baja calidad, a veces da la respuesta incorrecta ya que algunos alimentos tienen el mismo color. No nos proporciona la opción de personalizar o entrenar el modelo para nuestro caso de uso específico. La parte de configuración es compleja."
- Reseña de Google Cloud Vision API, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit es una biblioteca de aprendizaje automático de código abierto y multiplataforma. Atrae a desarrolladores e ingenieros de IA por sus opciones de reconocimiento de gestos e imágenes en tiempo real que se integran dentro de sus propios algoritmos y modelos.
Lo que más les gusta a los usuarios:
"Su extenso conjunto de algoritmos y su interfaz fácil de usar lo hacen adecuado tanto para principiantes como para usuarios avanzados."
- Reseña de Gesture Recognition Toolkit, Ram M.
Lo que no les gusta a los usuarios:
"Gesture Recognition Toolkit tiene ocasionalmente retrasos y un proceso de implementación menos fluido. Los tiempos de respuesta del soporte al cliente podrían ser más rápidos."
- Reseña de Gesture Recognition Toolkit, Civic V.
3. SuperAnnotate
SuperAnnotate es una plataforma para construir, ajustar y gestionar tus modelos de IA con los datos de entrenamiento de la más alta calidad y líderes en la industria. La tecnología avanzada de anotación y las herramientas de aseguramiento de calidad te permiten construir modelos de aprendizaje automático exitosos y conjuntos de datos de alto nivel.
Lo que más les gusta a los usuarios:
"Estaba buscando una herramienta para anotar imágenes biológicas. Después de probar muchas herramientas, encontré dos de las mejores plataformas para mí. Una de ellas es Superannotate. Estas plataformas tenían el conjunto más amplio de herramientas de anotación, incluidas exactamente las que necesitaba. Las herramientas son convenientes de usar."
- Reseña de SuperAnnotate, Artem M.
Lo que no les gusta a los usuarios:
"Hemos tenido algunos problemas con flujos de trabajo personalizados que el equipo implementó para proyectos específicos en su plataforma. Para ciertos flujos de trabajo personalizados, notamos que la herramienta de análisis estaba informando incorrectamente el tiempo tomado para la anotación."
- Reseña de SuperAnnotate, Rohan K.
4. Syte
Syte es la primera plataforma de descubrimiento de productos impulsada por IA del mundo que ayuda tanto a consumidores como a minoristas a conectarse con productos. La búsqueda por cámara, la personalización y las herramientas en tienda como el reconocimiento de imágenes hacen que la experiencia de compra sea instantánea e intuitiva.
Lo que más les gusta a los usuarios:
"El equipo ofrece constantemente ideas valiosas y alternativas para mejorar la funcionalidad y efectividad de la herramienta Shop Similar. Trabajar con Syte facilita el logro de los KPI específicos de nuestro sitio."
- Reseña de Syte, Gabriella M.
Lo que no les gusta a los usuarios:
"Hubo cierta dificultad para habilitar diferentes cuentas en el panel de análisis. Sería bueno no tener restricciones en estos inicios de sesión (diferentes usuarios deberían poder acceder a él)."
- Reseña de Syte, Antonio R.
5. Dataloop
Dataloop es una plataforma de desarrollo de IA que permite a las empresas construir sus propias aplicaciones de IA fácilmente y con conjuntos de datos intuitivos. Las herramientas dentro del software permiten a los equipos optimizar la anotación de imágenes, la selección de modelos y los despliegues de modelos para una aplicación a gran escala.
Lo que más les gusta a los usuarios:
"Dataloop también tiene una gran cantidad de características que lo hacen conveniente para muchos usuarios de diferentes proyectos. Después de cada actualización, se proporcionan instrucciones que explican los cambios, lo que facilita su implementación."
- Reseña de Dataloop, Mzamil J.
Lo que no les gusta a los usuarios:
"He tenido desafíos con algunas curvas de aprendizaje pronunciadas, dependencia de infraestructura y limitaciones de personalización. Estos, de alguna manera, me han limitado en su uso."
- Reseña de Dataloop, Dennis R.

¡Empieza a trabajar con IA porque YOLO!
En menos de una década, YOLO ha hecho un progreso significativo y se ha convertido en el método preferido de detección de objetos para muchas industrias. Gracias a su enfoque eficiente y preciso para el reconocimiento de imágenes, es ideal para necesidades en tiempo real mientras exploras el mundo de la IA.
Aprende más sobre redes neuronales artificiales y cómo los modelos están diseñados para imitar el cerebro humano.
Editado por Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.


