
Chayanika Sen
Chayanika is a B2B Tech and SaaS content writer. She specializes in writing data-driven and actionable content in the form of articles, guides, and case studies. She's also a trained classical dancer and a passionate traveler.
Imagina traducir sin esfuerzo un libro completo de un idioma a otro o condensar páginas de texto denso en unas pocas oraciones claras, todo con solo unos pocos clics.
Para los practicantes de aprendizaje automático (ML), lograr tales tareas se siente como navegar por un laberinto de complejidades. Los datos secuenciales presentan desafíos únicos: entradas ruidosas, dependencias ocultas y predicciones que fallan cuando se pierde el contexto.
Los modelos Seq2Seq están diseñados para abordar estos desafíos exactos.
¿Qué es Seq2Seq?
Sequence-to-sequence (Seq2Seq) es un modelo de aprendizaje automático diseñado para mapear una secuencia de entrada a una secuencia de salida. Este enfoque se utiliza ampliamente en tareas donde la entrada y la salida difieren en longitud, como la traducción de idiomas, la resumición de texto o la conversión de voz a texto.
Los modelos Seq2Seq se integran comúnmente en plataformas de ciencia de datos y ML y software de procesamiento de lenguaje natural (NLP), proporcionando soluciones robustas para aplicaciones del mundo real como la traducción automática. Son particularmente efectivos en tareas de traducción automática neuronal, permitiendo una conversión de texto fluida entre idiomas como el inglés y el francés, manteniendo la precisión gramatical y la fluidez.
A diferencia de los algoritmos tradicionales, los modelos Seq2Seq están diseñados para manejar secuencias manteniendo el contexto y el orden. Esto los hace altamente adecuados para tareas donde el significado de la entrada depende del orden de los puntos de datos, como oraciones o datos de series temporales.
Exploremos cómo funciona Seq2Seq y por qué es una herramienta esencial para aplicaciones de redes neuronales. ¡Si estás ansioso por abordar desafíos del mundo real con ML, estás en el lugar correcto!
¿Cómo funciona el modelo Seq2Seq?
Los modelos Seq2Seq dependen de una estructura bien definida para procesar secuencias y generar salidas significativas. A través de una arquitectura cuidadosamente diseñada, se aseguran de que tanto las secuencias de entrada como las de salida se manejen con precisión y coherencia.
Exploremos los componentes principales de esta arquitectura y cómo contribuyen a la efectividad del modelo.
Arquitectura del modelo Seq2Seq
La arquitectura del modelo Seq2Seq típicamente incluye:
- Capa de entrada. Esta capa toma la secuencia de entrada y la convierte en embeddings para su posterior procesamiento. En implementaciones prácticas, los embeddings a menudo representan secuencias de palabras, tokens u otros puntos de datos, dependiendo de la tarea, como la resumición de texto o la traducción de idiomas.
- Codificador. El codificador típicamente consiste en una red neuronal recurrente (RNN), memoria a largo plazo (LSTM) o unidad recurrente con compuerta (GRU), que procesa la secuencia de entrada y produce un vector de contexto que resume la secuencia.
- Decodificador. Al igual que el codificador, un decodificador también se construye utilizando arquitecturas RNN, LSTM o GRU. Genera la secuencia de salida basándose en el vector de contexto.
- Mecanismo de atención (si se usa). El mecanismo de atención a menudo se implementa como parte del decodificador, donde selecciona dinámicamente partes relevantes de la secuencia de entrada durante el proceso de decodificación para mejorar la precisión.
1. El papel del codificador
El trabajo del codificador es entender y resumir la secuencia de entrada, a menudo mapeando la secuencia en un embedding de tamaño fijo. Estos embeddings ayudan a preservar características críticas, especialmente para tareas como la traducción automática de inglés a francés. El codificador actualiza su estado de contexto oculto con cada paso de tiempo para retener dependencias esenciales.
Ecuación de actualización del estado oculto del codificador:
ht=tanh(W_h*h_(t-1)+W_x*x_t+b_h)Dónde:
- ht es el estado oculto en el tiempo t
- h_(t-1) es el estado oculto anterior
- x_t es la entrada en el tiempo t
- W_h y W_x son matrices de pesos
- b_h es el término de sesgo
- tanh es la función de activación
Puntos clave sobre el codificador:
- Procesa las entradas un elemento a la vez (por ejemplo, palabra por palabra o carácter por carácter).
- En cada paso, actualiza el estado interno del codificador basado en el elemento actual y los estados anteriores.
- Produce un vector de contexto que contiene la información que el decodificador necesita para generar la salida.
2. El papel del decodificador
El decodificador comienza con el vector de contexto del codificador y predice la secuencia de salida un paso a la vez. Actualiza su estado oculto basado en el estado anterior, el vector de contexto y la última palabra predicha.
Ecuación de actualización del estado oculto del decodificador:
st=tanh(W_s*s_(t-1)+ W_y*y_(t-1)+ W_c*c_t+b_s)Dónde:
- st: Estado oculto del decodificador en el tiempo t
- s_(t-1): Estado oculto anterior del decodificador
- y_(t-1): Salida anterior o token predicho
- c_t: Vector de contexto (de la salida del codificador)
- W_s, W_y, W_c: Matrices de pesos
- b_s: Término de sesgo
- tanh: Función de activación
Puntos clave sobre el decodificador:
- El decodificador genera la salida un paso a la vez, prediciendo el siguiente elemento basado en el vector de contexto y las predicciones anteriores.
- Continúa hasta que emite un token único (por ejemplo, <END>) que señala la finalización de la secuencia.
3. El mecanismo de atención
La atención es una mejora poderosa que a menudo se agrega a los modelos Seq2Seq, especialmente al manejar oraciones más largas. En lugar de depender únicamente de un vector de contexto, la atención permite que el decodificador observe diferentes partes de la secuencia de entrada mientras genera cada palabra.
Seq2Seq con atención calcula puntuaciones de atención para enfocarse dinámicamente en diferentes partes de la secuencia de entrada durante la decodificación.
Fórmula de peso de atención:
α_ij = exp(e_ij) / Σ_k exp(e_ik)Dónde:
- αij: Peso de atención para la consulta i y la clave j
- e_ij: Puntuación de atención en bruto entre la consulta i y la clave j
- exp: Función exponencial
- Σ_k exp(e_ik): Suma de puntuaciones exponenciales para todas las claves k (término de normalización)
Esta operación softmax asegura que los pesos de atención sumen 1 en todas las claves.
Por qué la atención es crítica para los modelos Seq2Seq
La adición del mecanismo de atención ha hecho que Seq2Seq sea más robusto y escalable. Así es cómo:
- Mejor manejo de secuencias largas: Los vectores de contexto podrían tener dificultades para retener toda la información relevante sin atención. Esto puede llevar a una mala calidad de salida en textos largos.
- Enfoque adaptativo: La atención permite que el modelo ajuste el enfoque en elementos de entrada específicos en cada paso de decodificación, ayudando a crear traducciones o resúmenes más precisos.
- Fundamento de los transformadores: La atención también es un concepto central en arquitecturas modernas de transformadores como BERT, GPT y T5, que se basan en modelos Seq2Seq para manejar tareas de NLP aún más complejas.
4. Entrenamiento del modelo Seq2Seq
Entrenar modelos Seq2Seq requiere un gran conjunto de datos de secuencias emparejadas (por ejemplo, pares de oraciones en dos idiomas). El modelo aprende comparando su salida con la producción correcta y ajustando hasta minimizar los errores. Con el tiempo, mejora en la transformación de secuencias.
¿Quieres aprender más sobre Software de Procesamiento de Lenguaje Natural (PLN)? Explora los productos de Procesamiento de Lenguaje Natural (PLN).
Cómo implementar un modelo Seq2Seq en PyTorch
PyTorch es un marco de aprendizaje profundo popular para implementar modelos Seq2Seq porque ofrece flexibilidad y facilidad de uso.
Aquí tienes una guía paso a paso para construir una arquitectura codificador-decodificador en PyTorch que procese datos secuenciales y produzca salidas significativas.
Paso 1: Importar bibliotecas
Para definir y entrenar el modelo, importa las bibliotecas necesarias, como PyTorch, NumPy y otras utilidades.

Fuente: ChatGPT
Paso 2: Definir hiperparámetros
Establece los parámetros clave para el modelo, incluyendo el tamaño de entrada (número de características en la entrada), tamaño de salida (características en la salida), dimensiones ocultas (tamaño de las capas ocultas) y tasa de aprendizaje (controla la velocidad de entrenamiento del modelo).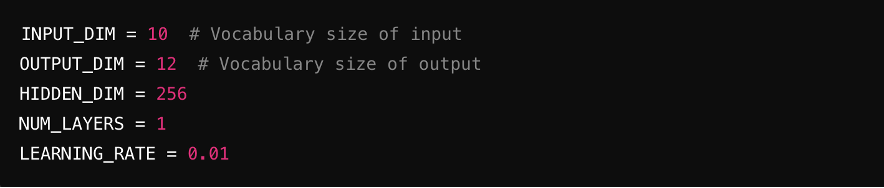
Fuente: ChatGPT
Paso 3: Definir el codificador
Crea el codificador, típicamente usando una RNN, LSTM o GRU. Procesa la oración de entrada paso a paso, resumiendo la información en un vector de contexto almacenado en su estado oculto.
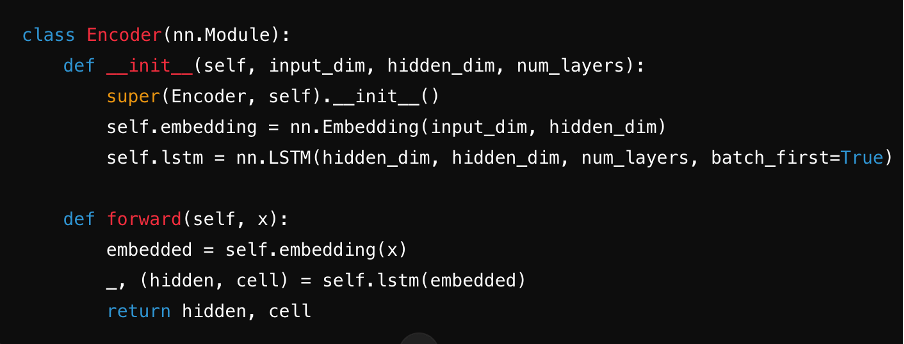
Fuente: ChatGPT
Paso 4: Definir el decodificador
Diseña el decodificador, que genera la secuencia de salida. Utiliza el vector de contexto del codificador y sus estados ocultos para predecir cada paso de salida.
Paso 5: Combinar en un modelo Seq2Seq
Integra el codificador y el decodificador en un solo modelo Seq2Seq. Durante este paso, a menudo usarás capas lineales y funciones softmax para generar predicciones para cada paso de tiempo de la secuencia objetivo. Esto asegura una transferencia sin problemas del vector de contexto, embeddings y estados ocultos entre componentes, optimizando la eficiencia del modelo.
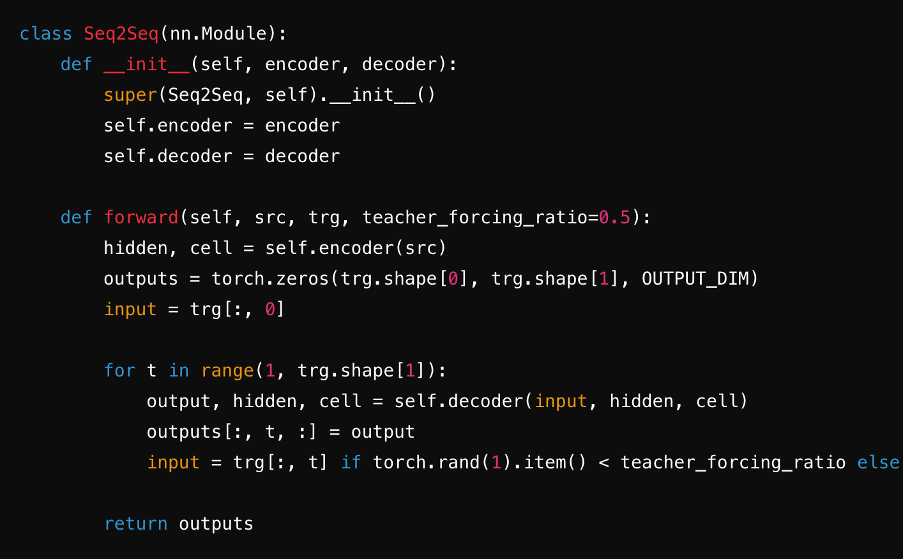
Fuente: ChatGPT
Paso 6: Entrenar el modelo
Implementa un bucle de entrenamiento donde el modelo aprende comparando sus predicciones con la verdad del terreno. Optimiza los parámetros usando una función de pérdida y un algoritmo como Adam o SGD. Itera a través de épocas, actualizando pesos para minimizar la pérdida y mejorar el rendimiento con el tiempo.

Fuente: ChatGPT
Aplicaciones clave de los modelos Seq2Seq en NLP
Seq2Seq es un algoritmo de aprendizaje automático destacado para NLP debido a su flexibilidad y precisión en el manejo de tareas complejas de lenguaje. Al emplear el aprendizaje de secuencia a secuencia con redes neuronales, estos modelos sobresalen en aplicaciones como:
- Traducción de idiomas. Seq2Seq sobresale en la traducción de texto entre idiomas. Su capacidad para capturar matices gramaticales y mantener la fluidez los hace ideales para impulsar servicios como Google Translate.
- Resumición de texto. Al identificar y condensar información esencial, los modelos Seq2Seq crean resúmenes concisos de artículos, informes u otros textos extensos sin perder el significado.
- IA conversacional y chatbots. Los modelos Seq2Seq generan respuestas naturales y conscientes del contexto, lo que los hace esenciales para chatbots, asistentes virtuales y sistemas automatizados de servicio al cliente. Su capacidad para producir texto coherente y similar al humano también es beneficiosa para respuestas automáticas de correo electrónico o generación de historias.
- Adaptabilidad para datos de longitud variable. La estructura codificador-decodificador permite que Seq2Seq maneje datos de longitudes variables, lo que lo hace adecuado para tareas como respuesta a preguntas o generación de código.
Ventajas de los modelos Seq2Seq
Los modelos de secuencia a secuencia ofrecen una flexibilidad y precisión únicas. Examinemos las ventajas clave que hacen de Seq2Seq una herramienta poderosa.
- Versatilidad: Los modelos Seq2Seq pueden manejar tareas diversas como traducción de idiomas, resumición, generación de texto y más. Su arquitectura codificador-decodificador los hace adaptables a varios desafíos de datos secuenciales.
- Preservación del contexto: Estos modelos mantienen el contexto de las secuencias de entrada, lo que los hace especialmente útiles para tareas que involucran oraciones largas o párrafos donde el significado depende de partes anteriores de la secuencia.
- Precisión: Dado que los modelos Seq2Seq son altamente escalables y pueden entrenarse en grandes conjuntos de datos, su precisión y fiabilidad mejoran con el tiempo.
- Robustez ante datos ruidosos: Al capturar dependencias secuenciales de manera efectiva, los modelos Seq2Seq mitigan errores que surgen de datos ruidosos o incompletos.
Desventajas de los modelos Seq2Seq
Entender las limitaciones de los modelos Seq2Seq es crucial para determinar cuándo y cómo implementarlos de manera efectiva. Exploremos algunos de los posibles inconvenientes.
- Altos requisitos computacionales: Implementar modelos Seq2Seq en dispositivos de bajos recursos es difícil ya que demandan mucha memoria y capacidad de procesamiento, particularmente cuando se combinan con mecanismos de atención.
- Dificultad para manejar secuencias muy largas: Incluso con características como la atención, los modelos Seq2Seq pueden tener problemas para procesar secuencias de entrada prolongadas. Esto puede resultar en pérdida de contexto o bajo rendimiento en tareas que involucran múltiples dependencias.
- Dependencia de datos de entrenamiento extensos: Para entrenar modelos Seq2Seq de manera efectiva, se requieren grandes conjuntos de datos de alta calidad. En ausencia de datos confiables o insuficientes, se puede obtener una salida de baja calidad y resultados poco confiables.
- Riesgo de sesgo de exposición: Los modelos Seq2Seq son guiados por las respuestas correctas (datos forzados por el profesor) durante el entrenamiento. Sin embargo, el modelo tiene que depender de sus predicciones durante el uso real. Si comete un error temprano, los errores pueden acumularse y afectar la salida final.
El futuro de los modelos Seq2Seq en el lenguaje y la IA
Los modelos Seq2Seq tienen un futuro prometedor en el lenguaje y la IA, particularmente como elementos fundamentales para modelos de lenguaje modernos como GPT y BERT.
Con avances en técnicas de embedding, entrenamiento adaptativo con optimización de gradiente y traducción automática neuronal, Seq2Seq está preparado para abordar desafíos de NLP aún más complejos.
- Expansión de aplicaciones: Seq2Seq probablemente se expandirá a más áreas, como servicio al cliente automatizado, escritura creativa y chatbots avanzados, haciendo que las interacciones sean más fluidas e intuitivas.
- Mejor manejo de contextos complejos: Los mecanismos de atención mejorados y las innovaciones basadas en transformadores están ayudando a los modelos Seq2Seq a entender matices de lenguaje más profundos.
- Adaptabilidad a idiomas de bajos recursos: Con más investigación, los modelos Seq2Seq pueden ser capaces de soportar una gama más amplia de idiomas, incluyendo aquellos con menos datos de entrenamiento.
- Integración con IA avanzada: Seq2Seq es fundamental para modelos más nuevos como GPT y BERT, que seguirán empujando los límites en el procesamiento del lenguaje natural.
Desbloqueando nuevos horizontes con modelos Seq2Seq
Los modelos Seq2Seq han revolucionado la forma en que procesamos y entendemos el lenguaje en la IA, ofreciendo una versatilidad y precisión incomparables. Desde traducir idiomas sin problemas hasta generar texto similar al humano, son la columna vertebral de las aplicaciones modernas de NLP.
A medida que los avances como los mecanismos de atención y los transformadores evolucionan, los modelos Seq2Seq solo se volverán más poderosos y eficientes, abordando desafíos cada vez más complejos en el lenguaje y las redes neuronales. Ya sea un entusiasta del ML o un practicante experimentado, explorar Seq2Seq abre la puerta a crear soluciones más innovadoras y conscientes del contexto.
El futuro de la IA es secuencial, ¿estás listo para dar el paso?
Descubre las mejores soluciones LLM para construir y escalar tus modelos de aprendizaje automático.