

Amal Joby
Amal is a Research Analyst at G2 researching the cybersecurity, blockchain, and machine learning space. He's fascinated by the human mind and hopes to decipher it in its entirety one day. In his free time, you can find him reading books, obsessing over sci-fi movies, or fighting the urge to have a slice of pizza.
Immagina un mondo in cui i computer possono imparare e adattarsi da soli. Non più bloccati a fare solo ciò che programmiamo loro di fare, le macchine saranno in grado di comprendere, analizzare e persino prevedere il comportamento delle persone. Questo non è solo un sogno; è una realtà verso cui ci stiamo rapidamente muovendo.
Nel mondo odierno pieno di informazioni, la quantità di dati può essere travolgente. Mentre è facile raccogliere dati, la vera sfida è trovare intuizioni utili da tutte quelle informazioni. È qui che entra in gioco il machine learning.
Cos'è il machine learning?
Il machine learning è una parte dell'intelligenza artificiale che si concentra sulla creazione di algoritmi che possono imparare dai dati. Utilizzando dati passati, possono prevedere risultati futuri, dando alle macchine un modo più intelligente di analizzare grandi quantità di informazioni e scoprire connessioni nascoste che gli esseri umani potrebbero perdere.
Vari strumenti di machine learning aiutano gli sviluppatori a costruire e distribuire sistemi intelligenti. Questi strumenti consentono alle aziende di indovinare quali prodotti i clienti sono più propensi ad acquistare e quali contenuti online apprezzeranno.
Un uso comune del machine learning è nei sistemi di raccomandazione. Grandi aziende come Google, Netflix e Amazon utilizzano questi sistemi per apprendere le preferenze degli utenti, aiutandoli a offrire suggerimenti personalizzati di prodotti e servizi.
Storia del machine learning
Il machine learning esiste da un po' di tempo, ed è evidente nel modo in cui ci riferiamo ai computer oggi—"macchine" è un termine che è diventato meno comune.
Di seguito è riportata una breve panoramica dell'evoluzione del machine learning, tracciando il suo percorso dall'inizio all'applicazione diffusa.
- Prima degli anni '20: Thomas Bayes, Andrey Markov, Adrien-Marie Legendre e altri matematici acclamati pongono le basi necessarie per le tecniche fondamentali del machine learning.
- 1943: Il primo modello matematico di reti neurali viene presentato in un articolo scientifico da Walter Pitts e Warren McCulloch.
- 1949: Viene pubblicato "The Organization of Behavior", un libro di Donald Hebb. Questo libro esplora come il comportamento si relaziona all'attività cerebrale e alle reti neurali.
- 1950: Alan Turing cerca di descrivere l'IA e si interroga se le macchine abbiano la capacità di apprendere.
- 1951: Marvin Minsky e Dean Edmonds costruiscono la prima rete neurale artificiale.
- 1956: John McCarthy, Marvin Minsky, Nathaniel Rochester e Claude Shannon organizzano il Workshop di Dartmouth. L'evento è spesso indicato come il "luogo di nascita dell'IA", e il termine intelligenza artificiale è stato coniato nello stesso evento.
Nota: Arthur Samuel è considerato il padre del machine learning perché ha coniato il termine nel 1959.
- 1965: Alexey (Oleksii) Ivakhnenko e Valentin Lapa sviluppano il primo percettrone multistrato. Ivakhnenko è spesso considerato il padre del deep learning (DL).
- 1967: Viene concepito l'algoritmo del vicino più prossimo.
- 1979: Il computer scientist Kunihiko Fukushima pubblica il suo lavoro sul neocognitron: una rete multilivello gerarchica utilizzata per rilevare modelli. Il neocognitron ha anche ispirato le reti neurali convoluzionali (CNN).
- 1985: Terrence Sejnowski inventa NETtalk. Questo programma impara a pronunciare le parole (inglesi) nello stesso modo in cui fanno i bambini.
- 1995: Tin Kam Ho introduce le foreste di decisioni casuali in un articolo.
- 1997: Deep Blue, il computer scacchistico di IBM, batte Garry Kasparov, il campione mondiale di scacchi.
- 2000: Il termine deep learning viene menzionato per la prima volta dal ricercatore di reti neurali Igor Aizenberg.
- 2009: Fei-Fei Li lancia ImageNet, un grande database di immagini ampiamente utilizzato per la ricerca sul riconoscimento degli oggetti visivi.
- 2011: Il laboratorio X di Google sviluppa Google Brain, un algoritmo di intelligenza artificiale. Più tardi nello stesso anno, IBM Watson batte i concorrenti umani nel quiz televisivo Jeopardy!.
- 2014: Ian Goodfellow e i suoi colleghi sviluppano una rete generativa avversaria (GAN). Nello stesso anno, Facebook sviluppa DeepFace, un sistema di riconoscimento facciale basato sul deep learning che può individuare volti umani nelle immagini con un'accuratezza del 97,25%. Successivamente, Google introduce al pubblico un sistema di machine learning su larga scala chiamato Sibyl.
- 2015: AlphaGo diventa la prima IA a battere un giocatore professionista a Go.
- 2020: Open AI annuncia GPT-3, un robusto algoritmo di elaborazione del linguaggio naturale con la capacità di generare testo simile a quello umano.
Vuoi saperne di più su Software di apprendimento automatico? Esplora i prodotti Apprendimento automatico.
Machine learning vs. deep learning
Sebbene sia il machine learning che il deep learning siano sottocategorie dell'intelligenza artificiale, differiscono per ambito e complessità.
Il ML coinvolge l'addestramento di modelli sui dati per fare previsioni o decisioni utilizzando varie tecniche, come alberi decisionali, macchine a vettori di supporto e k-nearest neighbors. In questo approccio, l'intervento umano è spesso necessario per identificare le caratteristiche rilevanti e garantire che i modelli migliorino nel tempo, un concetto comunemente noto come human-in-the-loop.
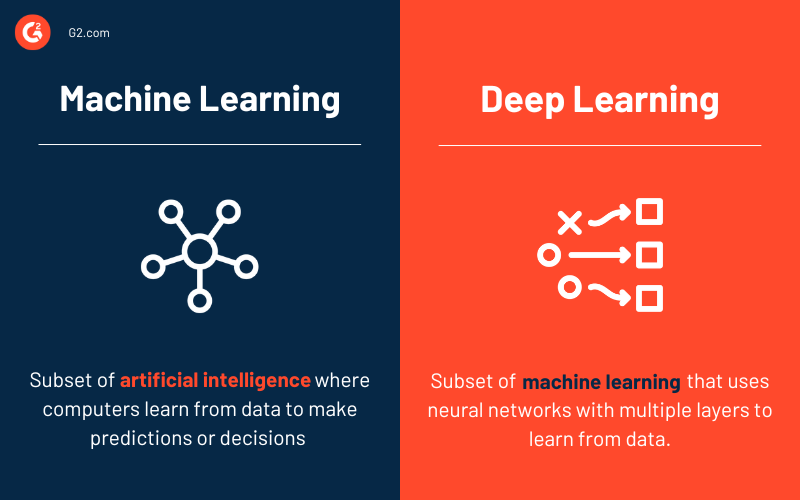
Al contrario, il DL è una sottocategoria più avanzata del ML che utilizza reti neurali artificiali ispirate al cervello umano, comprendenti strati di nodi interconnessi (neuroni). I modelli DL eccellono nell'elaborazione di grandi quantità di dati e possono identificare automaticamente caratteristiche cruciali senza guida umana.
Ad esempio, nei compiti di riconoscimento delle immagini, il deep learning può rilevare autonomamente bordi, forme e oggetti complessi, mentre i metodi ML tradizionali richiedono tipicamente che gli umani specifichino queste caratteristiche in anticipo.
Come funziona il machine learning
Alla sua base, gli algoritmi di machine learning analizzano e identificano modelli dai dataset, quindi utilizzano tali informazioni per fare previsioni migliorate su nuovi dati non visti. Questo processo rispecchia il modo in cui gli esseri umani apprendono e migliorano. Quando prendiamo decisioni, spesso ci affidiamo a esperienze passate per valutare meglio nuove situazioni. Allo stesso modo, un modello di machine learning esamina i dati storici per fare previsioni o decisioni informate.
Per semplificare il concetto, immagina di giocare al gioco del dinosauro in Google Chrome (quello che appare quando non c'è internet). La sfida è saltare sopra i cactus o abbassarsi sotto gli uccelli. Un umano impara questo attraverso tentativi ed errori, riconoscendo rapidamente che è necessario evitare gli ostacoli per rimanere nel gioco.
Un'applicazione di machine learning imparerebbe in modo simile. Uno sviluppatore potrebbe programmare l'applicazione per saltare ogni volta che il T-Rex incontra un'area densa di pixel scuri, con il tasso di successo di quell'azione che aumenta nel tempo. Incontrando più ostacoli e regolando in base ai risultati, l'IA potrebbe affinare le sue previsioni su quando saltare o abbassarsi.
Prendiamo un altro esempio:
Considera questa sequenza:
3 → 9
4 → 16
5 → 25
Se ti venisse chiesto di prevedere il numero che si abbina a 6, probabilmente diresti 36. Lo hai fatto riconoscendo un modello (ogni numero è elevato al quadrato). Un modello di machine learning funziona allo stesso modo—analizzando dati precedenti per fare previsioni basate su modelli.
Alla sua essenza, il machine learning è pura matematica. Ogni algoritmo di machine learning si basa su funzioni matematiche che vengono modificate man mano che apprende. Ciò significa che il processo di apprendimento stesso è radicato nella matematica—trasformando i dati in intuizioni azionabili.
4 metodi di machine learning
Esistono numerosi metodi di machine learning attraverso i quali i sistemi di IA possono apprendere dai dati. Questi metodi sono categorizzati in base alla natura dei dati (etichettati o non etichettati) e ai risultati che ci si aspetta. In generale, ci sono quattro tipi di machine learning: supervisionato, non supervisionato, semi-supervisionato e apprendimento per rinforzo
1. Apprendimento supervisionato
L'apprendimento supervisionato è un approccio di machine learning in cui un data scientist agisce come un tutor e allena il sistema di IA fornendo regole di base e dataset etichettati. I dataset includeranno dati di input etichettati e risultati di output attesi. In questo metodo di machine learning, al sistema viene esplicitamente detto cosa cercare nei dati di input.
In termini più semplici, gli algoritmi di apprendimento supervisionato apprendono per esempio. Tali esempi sono collettivamente indicati come dati di addestramento. Una volta che un modello di machine learning è addestrato utilizzando il dataset di addestramento, vengono forniti i dati di test per determinare l'accuratezza del modello.
L'apprendimento supervisionato può essere ulteriormente classificato in due tipi: classificazione e regressione.
2. Apprendimento non supervisionato
L'apprendimento non supervisionato è una tecnica di machine learning in cui il data scientist lascia che il sistema di IA apprenda osservando. Il dataset di addestramento conterrà solo i dati di input e nessun dato di output corrispondente.
A differenza dell'apprendimento supervisionato, l'apprendimento non supervisionato richiede enormi quantità di dati non etichettati da osservare, trovare modelli e apprendere. L'apprendimento non supervisionato potrebbe essere un obiettivo in sé, ad esempio, scoprire modelli nascosti nei dataset o un metodo per l'apprendimento delle caratteristiche.
I problemi di apprendimento non supervisionato sono generalmente raggruppati in problemi di clustering e associazione.
3. Apprendimento semi-supervisionato
L'apprendimento semi-supervisionato è un amalgama di apprendimento supervisionato e non supervisionato. In questo processo di machine learning, il data scientist allena il sistema solo un po' in modo che ottenga una panoramica di alto livello.
Inoltre, una piccola percentuale dei dati di addestramento sarà etichettata, mentre il resto sarà non etichettato. A differenza dell'apprendimento supervisionato, questo metodo di apprendimento richiede che il sistema apprenda le regole e la strategia osservando i modelli nel dataset.
L'apprendimento semi-supervisionato è utile quando non si dispone di dati etichettati sufficienti o il processo di etichettatura è costoso ma si desidera creare un modello di machine learning accurato.
4. Apprendimento per rinforzo
L'apprendimento per rinforzo (RL) è una tecnica di apprendimento che consente a un sistema di IA di apprendere in un ambiente interattivo. Un programmatore utilizzerà un approccio di ricompensa-penalità per insegnare al sistema, permettendogli di apprendere attraverso tentativi ed errori e ricevere feedback dalle proprie azioni.
In parole povere, nell'apprendimento per rinforzo, il sistema di IA affronta una situazione simile a un gioco in cui deve massimizzare la ricompensa.
Sebbene il programmatore definisca le regole del gioco, l'individuo non fornisce alcun suggerimento su come risolvere o vincere il gioco. Il sistema deve trovare la sua strada conducendo numerosi tentativi casuali e imparando a migliorare da ogni passo.
Casi d'uso del machine learning
I progetti di machine learning hanno rivoluzionato quasi ogni settore che ha subito una trasformazione digitale. Ecco solo alcuni dei molti casi d'uso impattanti dei progetti di machine learning in vari settori.
Riconoscimento delle immagini
Le macchine stanno diventando sempre più abili nell'elaborazione delle immagini. Infatti, i modelli di machine learning sono migliori e più veloci nel riconoscere e classificare le immagini rispetto agli esseri umani.
Questa applicazione del machine learning è chiamata riconoscimento delle immagini o visione artificiale. È alimentata da algoritmi di deep learning e utilizza immagini come dati di input. Probabilmente hai visto questa impresa in azione quando hai caricato una foto su Facebook e l'app ha suggerito di taggare i tuoi amici riconoscendo i loro volti.
Software di gestione delle relazioni con i clienti (CRM)
Il machine learning consente alle applicazioni CRM di decodificare le domande "perché".
Perché un prodotto specifico supera gli altri? Perché i clienti compiono una determinata azione sul sito web? Perché i clienti non sono soddisfatti di un prodotto?
Analizzando i dati storici raccolti dalle applicazioni CRM, i modelli di machine learning possono aiutare a costruire strategie di vendita migliori e persino prevedere le tendenze di mercato emergenti. Il ML può anche trovare modi per ridurre i tassi di abbandono, migliorare il valore del ciclo di vita del cliente e aiutare le aziende a rimanere un passo avanti.
Oltre all'analisi dei dati, all'automazione del marketing e all'analisi predittiva, il machine learning concede alle aziende la possibilità di essere disponibili 24/7 grazie alla sua incarnazione come chatbot.
Diagnosi del paziente
È sicuro dire che le cartelle cliniche cartacee sono un ricordo del passato. Molti ospedali e cliniche hanno ora adottato cartelle cliniche elettroniche (EHR), che rendono l'archiviazione delle informazioni sui pazienti più sicura ed efficiente.
Poiché le EHR convertono le informazioni sui pazienti in un formato digitale, l'industria sanitaria può implementare il machine learning ed eliminare processi tediosi. Ciò significa anche che i medici possono analizzare i dati dei pazienti in tempo reale e persino prevedere la possibilità di epidemie di malattie.
Oltre a migliorare l'accuratezza della diagnosi medica, gli algoritmi di machine learning possono aiutare i medici a rilevare il cancro al seno e prevedere il tasso di progressione di una malattia.
Ottimizzazione dell'inventario
Se un materiale specifico è immagazzinato in eccesso, potrebbe non essere utilizzato prima che si deteriori. D'altra parte, se c'è una carenza, la catena di approvvigionamento sarà influenzata. La chiave è mantenere l'inventario considerando la domanda del prodotto.
La domanda di un prodotto può essere prevista in base ai dati storici. Ad esempio, il gelato viene venduto più frequentemente durante la stagione estiva (anche se non sempre e ovunque). Tuttavia, numerosi altri fattori influenzano la domanda, tra cui il giorno della settimana, la temperatura, le festività imminenti e altro ancora.
Calcolare tali fattori micro e macro è praticamente impossibile per gli esseri umani. Non sorprende che l'elaborazione di tali volumi massicci di dati sia una specialità delle applicazioni di machine learning.
Ad esempio, sfruttando il database enorme di The Weather Company , IBM Watson ha scoperto che le vendite di yogurt aumentano quando il vento è sopra la media e le vendite di autogas aumentano quando la temperatura è più fredda della media.
Inoltre, le auto a guida autonoma, la previsione della domanda, il riconoscimento vocale, i sistemi di raccomandazione e il rilevamento delle anomalie non sarebbero stati possibili senza il machine learning.
Come costruire un modello di machine learning
Creare un modello di machine learning è proprio come sviluppare un prodotto. C'è una fase di ideazione, validazione e test, per citare alcuni processi. In generale, la costruzione di un modello di machine learning può essere suddivisa in cinque passaggi.
Raccolta e preparazione del dataset di addestramento
Nel regno del machine learning, nulla è più importante dei dati di addestramento di qualità.
Come accennato in precedenza, il dataset di addestramento è una raccolta di punti dati. Questi punti dati aiutano il modello a capire come affrontare il problema che è inteso a risolvere. Tipicamente, il dataset di addestramento contiene immagini, testo, video o audio.
Il dataset di addestramento è simile a un libro di matematica con problemi di esempio. Maggiore è il numero di esempi, meglio è. Oltre alla quantità, anche la qualità del dataset è importante poiché il modello deve essere altamente accurato. Il dataset di addestramento deve anche riflettere le condizioni del mondo reale in cui il modello sarà utilizzato.
Il dataset di addestramento può essere completamente etichettato, non etichettato o parzialmente etichettato. Come accennato in precedenza, la natura del dataset dipende dal metodo di machine learning che scegli.
In ogni caso, il dataset di addestramento deve essere privo di dati duplicati. Un dataset di alta qualità passerà attraverso numerose fasi del processo di pulizia e conterrà tutti gli attributi essenziali che si desidera che il modello apprenda.
Tieni sempre a mente questa frase: spazzatura in, spazzatura fuori.
Scegliere un algoritmo
Un algoritmo è una procedura o un metodo per risolvere un problema. Nel linguaggio del machine learning, un algoritmo è una procedura eseguita sui dati per creare un modello di machine learning. La regressione lineare, la regressione logistica, i vicini più prossimi (KNN) e Naive Bayes sono alcuni degli algoritmi di machine learning più popolari.
La scelta di un algoritmo dipende dal problema che intendi risolvere, dal tipo di dati (etichettati o non etichettati) e dalla quantità di dati disponibili.
Se stai utilizzando dati etichettati, puoi considerare i seguenti algoritmi:
- Alberi decisionali
- Regressione lineare
- Regressione logistica
- Macchina a vettori di supporto (SVM)
- Foresta casuale
Se stai utilizzando dati non etichettati, puoi considerare i seguenti algoritmi:
- Algoritmo di clustering K-means
- Algoritmo Apriori
- Scomposizione del valore singolare
- Reti neurali
Inoltre, se desideri addestrare il modello a fare previsioni, scegli l'apprendimento supervisionato. Se desideri addestrare il modello a trovare modelli o dividere i dati in cluster, opta per l'apprendimento non supervisionato.
Addestrare l'algoritmo
In questa fase, l'algoritmo passa attraverso numerose iterazioni. Dopo ogni iterazione, i pesi e i bias all'interno dell'algoritmo vengono regolati confrontando l'output con i risultati attesi. Il processo continua fino a quando l'algoritmo diventa accurato, che è il modello di machine learning.
Validare il modello
Per molti, il dataset di validazione è sinonimo di dataset di test. In breve, è un dataset non utilizzato durante la fase di addestramento e viene introdotto al modello per la prima volta. Il dataset di validazione è fondamentale per valutare l'accuratezza del modello e capire se soffre di overfitting, un'ottimizzazione errata di un modello quando diventa eccessivamente sintonizzato sul suo dataset di addestramento.
Se l'accuratezza del modello è inferiore o uguale al 50%, è improbabile che sia utile per applicazioni nel mondo reale. Idealmente, il modello deve avere un'accuratezza del 90% o più.
Testare il modello
Una volta che il modello è addestrato e validato, deve essere testato utilizzando dati del mondo reale per verificarne l'accuratezza. Questo passaggio potrebbe far sudare il data scientist poiché il modello sarà testato su un dataset più ampio, a differenza della fase di addestramento o validazione.
In un senso più semplice, la fase di test ti permette di verificare quanto bene il modello ha imparato a svolgere il compito specifico. È anche la fase in cui puoi determinare se il modello funzionerà su un dataset più ampio.
Il modello migliora nel tempo e con l'accesso a nuovi dataset. Ad esempio, il filtro antispam della tua casella di posta elettronica migliora periodicamente quando segnali determinati messaggi come spam e falsi positivi come non spam.
I migliori software di machine learning
Come accennato in precedenza, gli algoritmi di machine learning sono in grado di fare previsioni o decisioni basate sui dati. Questi algoritmi concedono alle applicazioni la capacità di offrire funzionalità di automazione e IA. Interessante, la maggior parte degli utenti finali non è consapevole dell'uso degli algoritmi di machine learning in tali applicazioni intelligenti.
Per qualificarsi per l'inclusione nella categoria del machine learning, un prodotto deve:
- Offrire un prodotto o un algoritmo in grado di apprendere e migliorare sfruttando i dati
- Essere la fonte delle capacità di apprendimento intelligente nelle applicazioni software
- Essere in grado di utilizzare input di dati da diversi pool di dati
- Avere la capacità di produrre un output che risolva un problema particolare basato sui dati appresi
* Di seguito sono riportati i cinque principali software di machine learning dal Fall 2024 Grid® Report di G2. Alcune recensioni possono essere modificate per chiarezza.
1. Vertex AI
Vertex AI è una piattaforma unificata che semplifica lo sviluppo e la distribuzione di modelli ML. Offre un set completo di strumenti e servizi, tra cui preparazione dei dati, addestramento del modello, valutazione e distribuzione, rendendo più facile per sviluppatori e data scientist costruire e gestire applicazioni ML.
Cosa piace di più agli utenti:
"Per un progetto personale, ho deciso di costruire un chatbot AI conversazionale mirato a rendere la chat più umana. Inizialmente ho usato Dialogflow, ma le risposte non suonavano naturali. Ho avuto difficoltà a organizzare le conversazioni, pianificare i flussi utente e gestire gli errori.
Poi, ho trovato il Vertex AI Agent Builder (precedentemente chiamato Vertex AI Search and Conversations). Utilizzare l'API Agent Builder mi ha fatto risparmiare molto tempo su problemi di autenticazione e accesso. Alla fine, sono riuscito a creare un chatbot che suona naturale, utilizzando una base di conoscenza che ho costruito con LLM e RAG."
- Recensione di Vertex AI, Tejashri P.
Cosa non piace agli utenti:
"C'è una mancanza di documentazione approfondita per alcune funzionalità avanzate e casi d'uso più complessi. Inoltre, a seconda del carico di lavoro e della configurazione, i tempi di addestramento possono a volte sembrare più lenti rispetto all'utilizzo di hardware dedicato per l'esecuzione dei modelli."
- Recensione di Vertex AI, Manoj P.
2. Amazon Forecast
Amazon Forecast è un servizio di machine learning completamente gestito che utilizza algoritmi avanzati per generare previsioni accurate per dati di serie temporali. Sfrutta la stessa tecnologia utilizzata da Amazon.com per prevedere le tendenze future per milioni di prodotti. Prevedendo accuratamente la domanda futura di prodotti e servizi, le aziende possono ottimizzare l'inventario, ridurre gli sprechi e migliorare la pianificazione.
Cosa piace di più agli utenti:
"Amazon Forecast è un servizio di analisi predittiva facile da usare che gestisce automaticamente grandi volumi di dati, rendendolo ideale per una varietà di esigenze di previsione. Con i suoi algoritmi avanzati, genera previsioni altamente accurate, aiutando le aziende a prendere decisioni informate basate su intuizioni affidabili."
- Recensione di Amazon Forecast, Annette J.
Cosa non piace agli utenti:
"L'accuratezza e l'efficacia delle previsioni generate da Amazon Forecast dipendono molto dalla qualità e dalla rilevanza dei dati di input. Se i dati storici utilizzati per l'addestramento includono anomalie, outlier o altri problemi di qualità, possono influenzare negativamente l'accuratezza della previsione."
- Recensione di Amazon Forecast, Saurabh M.
3. Google Cloud TPU
Google Cloud TPU è un circuito integrato specifico per applicazioni di machine learning progettato per eseguire modelli di machine learning con servizi di IA su Google Cloud. Offre più di 100 petaflops di prestazioni in un solo pod, che è sufficiente potenza computazionale per le esigenze aziendali e di ricerca.
Cosa piace di più agli utenti:
"Amo il fatto che siamo stati in grado di costruire un servizio di IA all'avanguardia orientato alla sicurezza della rete grazie all'esecuzione ottimale dei modelli di machine learning all'avanguardia. La potenza di Google Cloud TPU è senza pari: fino a 11,5 petaflops e 4 TB HBM. La cosa migliore di tutte, l'interfaccia di Google Cloud Platform è semplice e facile da usare."
- Recensione di Google Cloud TPU, Isabelle F.
Cosa non piace agli utenti:
"Vorrei che ci fosse integrazione con i word processor."
- Recensione di Google Cloud TPU, Kevin C.
4. Jarvis
Jarvis di NVIDIA è una piattaforma di machine learning che fornisce un'interfaccia user-friendly per costruire e distribuire modelli ML. Semplifica il processo di preparazione dei dati, selezione del modello, addestramento e valutazione. Jarvis ML offre modelli pre-costruiti per compiti comuni come la classificazione delle immagini, l'elaborazione del linguaggio naturale e la previsione di serie temporali.
Cosa piace di più agli utenti:
"Jarvis è simile ad altre tecnologie di IA, ma ciò che apprezzo di più è la sua funzione di input tramite comando vocale, che migliora la produttività. Inoltre, fornisce suggerimenti di contenuti creativi per i creatori di blog, rendendolo uno strumento prezioso per la generazione di contenuti."
- Recensione di Jarvis, Akshit N.
Cosa non piace agli utenti:
"La funzione di voce è efficace, ma gli utenti abituati a Google Voice potrebbero trovare la fluidità input-output meno soddisfacente rispetto ad altre opzioni vocali. Sebbene l'interfaccia utente appaia visivamente attraente, è essenziale che l'API configurata dietro l'interfaccia utente funzioni bene."
- Recensione di Jarvis, Adithya K.
5. Aerosolve
Aerosolve è una piattaforma software di machine learning progettata principalmente per applicazioni di analisi predittiva e scienza dei dati. È particolarmente nota per la sua facilità d'uso, permettendo agli utenti di costruire modelli complessi senza richiedere competenze di programmazione estese.
Cosa piace di più agli utenti:
"Sono impressionato dalle sue capacità avanzate. È molto facile da usare, con un'implementazione fluida e un'integrazione semplice. Inoltre, il supporto clienti è decente, rendendo l'esperienza complessiva positiva."
- Recensione di Aerosolve, Rahul S.
Cosa non piace agli utenti:
"Aerosolve è carente in aree come le capacità di elaborazione delle immagini."
- Recensione di Aerosolve, Aurelija A.
Per l'elenco più aggiornato con una recensione approfondita, leggi questa guida di G2 sui migliori strumenti ML per il 2026.
L'IA è il cervello, il ML è il muscolo!
Il machine learning è il muscolo che consente all'IA di apprendere, adattarsi e svolgere compiti complessi. Dalla scienza dei dati all'ingegneria dell'IA, il machine learning viene utilizzato ovunque.
Man mano che il machine learning continua a evolversi, possiamo aspettarci di vedere applicazioni ancora più innovative. Dalle auto a guida autonoma alla medicina personalizzata, il machine learning sta trasformando le industrie e migliorando le nostre vite.
Tuttavia, con questo progresso arriva la responsabilità di garantire che queste tecnologie siano sviluppate e utilizzate in modo etico. Affrontando preoccupazioni come la privacy dei dati e i bias, possiamo sfruttare il potere dell'IA attraverso il machine learning e creare un futuro più personalizzato, inclusivo e intelligente.
Scopri le statistiche sul machine learning che plasmeranno il panorama futuro.
Questo articolo è stato originariamente pubblicato nel 2021. È stato aggiornato con nuove informazioni.