

Keerthi Rangan
Keerthi Rangan is a Senior SEO Specialist with a sharp focus on the IT management software market. Formerly a Content Marketing Specialist at G2, Keerthi crafts content that not only simplifies complex IT concepts but also guides organizations toward transformative software solutions. With a background in Python development, she brings a unique blend of technical expertise and strategic insight to her work. Her interests span network automation, blockchain, infrastructure as code (IaC), SaaS, and beyond—always exploring how technology reshapes businesses and how people work. Keerthi’s approach is thoughtful and driven by a quiet curiosity, always seeking the deeper connections between technology, strategy, and growth.
Le interruzioni sono implacabili e si verificano troppo frequentemente.
Quando accadono, è tipicamente nei momenti più inaspettati. Forse qualcuno inciampa su un cavo di alimentazione, si verifica un intoppo nella rete, o gli ingegneri spostano un disco e questo si corrompe.
Qualunque cosa accada, l'interruzione colpisce, e ci affrettiamo ad analizzare cosa è andato storto e a rimettere in funzione i server il prima possibile.
Il tempo di attività è sovrano. Aumentare il tempo di inattività del servizio può influire negativamente sui ricavi, sulla fiducia nel marchio, sulla perdita di dati e sul posizionamento nei motori di ricerca.
Un modo per gestire un guasto improvviso è utilizzare un componente di standby o failover. Il failover fornisce i mezzi per rispondere proattivamente piuttosto che reattivamente quando si verificano interruzioni inaspettate.
Con le organizzazioni che si stanno spostando verso la continuità aziendale nel cloud con software di disaster recovery as a service (DRaaS), è imperativo comprendere come il failover supporti le strategie di disaster recovery (DR) e i piani di continuità aziendale.
Cos'è il failover?
Il failover è una modalità operativa di backup in cui un sistema secondario assume le funzioni del sistema primario quando quest'ultimo diventa non disponibile. L'unità di backup si attiva automaticamente e senza soluzione di continuità, con poca o nessuna interruzione del servizio per gli utenti. Il failover è solitamente impiegato per sistemi critici e tolleranti ai guasti.
Il failover è una parte integrante del DRaaS per la continuità aziendale nel cloud. Il software DRaaS fornisce questa capacità di failover offrendo un rapido trasferimento del carico di lavoro se un servizio si interrompe.
Il failover è implementato in sistemi mission-critical dove l'integrità dei dati e il tempo di attività sono vitali. In caso di guasto, un sistema o una soluzione alternativa è immediatamente pronto a subentrare con poca interruzione dell'operazione regolare.
In breve, il failover è fondamentale per mantenerti online e operativo. Ad esempio, durante un guasto del data center primario, il failover deve trasferire il controllo dei sistemi mission-critical al data center secondario con minima interruzione dei servizi o perdita di dati.
Il failover può verificarsi in qualsiasi parte di un sistema:
- Un trigger hardware o software su un computer personale o dispositivo mobile può proteggere il dispositivo quando un componente, come una CPU o una cella della batteria, fallisce.
- Il failover può applicarsi a qualsiasi componente di rete individuale o sistema di componenti, come un canale di connessione, un dispositivo di archiviazione o un server web, all'interno di una rete.
- Il failover consente a molti server locali o basati su cloud di mantenere una connessione costante e sicura con poca o nessuna interruzione del servizio mentre si utilizza un database ospitato o un'applicazione web.
Le aziende stabiliscono la ridondanza in un guasto inaspettato utilizzando un computer, sistema o server di backup che è sempre pronto a entrare in azione automaticamente.
I progettisti di sistemi implementano la funzionalità di failover in server, supporto di database backend o reti che richiedono disponibilità costante e eccellente affidabilità. Il failover può:
- Proteggere il tuo database durante la manutenzione o un'interruzione del sistema. Ad esempio, se il server primario in loco si interrompe a causa di un guasto hardware, il server di backup (in loco o nel cloud) può rapidamente assumere i compiti di hosting senza intervento amministrativo.
- Può essere adattato alle tue configurazioni hardware e di rete specifiche. Mentre gestisci un database, un amministratore può impiegare non solo un sistema A o B di due server che funzionano in parallelo per proteggersi a vicenda, ma anche un server cloud per fornire risoluzione dei problemi, manutenzione e patching completi in loco, tutto senza influire sulla connettività.
- Consentire operazioni di manutenzione per funzionare automaticamente senza monitoraggio. Un passaggio automatico durante gli aggiornamenti periodici del software fornisce una protezione senza soluzione di continuità contro i rischi di sicurezza informatica.
Sapevi che? Un passaggio è essenzialmente lo stesso di un failover; tuttavia, a differenza di un failover, non è automatizzato e richiede un'interazione umana. Le soluzioni di failover automatizzate proteggono la maggior parte dei sistemi.
Perché il failover è importante?
Sopportare o tollerare semplicemente il tempo di inattività o le interruzioni non è sufficiente nel mercato globale competitivo di oggi. Grazie al failover e alle sue tecnologie, i clienti possono essere sicuri di poter contare su una connessione sicura senza interruzioni inaspettate.
L'integrazione del failover può essere un onere indesiderato e costoso, ma è una polizza assicurativa vitale che garantisce sicurezza e protezione.
Quindi, qual è il motivo principale per cui un'azienda ha un sistema di failover? L'obiettivo principale del failover è prevenire o ridurre il fallimento totale del sistema. Il failover è un componente essenziale del piano DR di ogni azienda. Se l'architettura di rete è configurata correttamente, il failover e il failback forniranno una protezione completa contro la maggior parte, se non tutte, le interruzioni del servizio.
Eventuali intoppi legittimi sono principalmente causati dalla quantità di dati da commutare, dalla larghezza di banda disponibile e da come i dati vengono spostati, duplicati o copiati nel secondo sito. La priorità di un ingegnere di sistemi dovrebbe essere ridurre il trasferimento dei dati migliorando la qualità della sincronizzazione tra due siti.
Dopo aver garantito la qualità della trasmissione dei dati, il problema successivo è determinare come attivare il failover riducendo al minimo il tempo di cambio.
Gli amministratori IT possono anche attivare un failover per facilitare la manutenzione e l'aggiornamento del sistema primario. Questo è noto come failover pianificato.
Vuoi saperne di più su Soluzioni di Disaster Recovery as a Service (DRaaS)? Esplora i prodotti Ripristino di emergenza come servizio (DRaaS).
Come funziona il failover?
Il failover coinvolge il ripristino dei dati, le impostazioni delle applicazioni e il supporto dell'infrastruttura a un componente di sistema di standby. Per l'utente finale, l'operazione è senza soluzione di continuità. Il funzionamento normale continua nonostante le inevitabili interruzioni indotte dai guasti delle apparecchiature grazie alla capacità di failover automatizzato.
Un sistema di failover richiede un collegamento diretto al sistema primario per funzionare con successo. Questo è noto come "battito cardiaco". Il battito cardiaco invia un impulso dal sistema primario al sistema di failover ogni pochi minuti. La soluzione di failover rimarrà inattiva finché l'impulso rimane stabile.
Un sistema di battito cardiaco è comune nell'automazione del failover. Nella sua forma più basilare, questo metodo collega due siti fisicamente tramite un cavo o in modalità wireless su una rete. Quando la regolarità del collegamento del battito cardiaco viene interrotta, il sistema di failover si attiverà e assumerà tutte le funzioni del sistema primario. Puoi solitamente progettare le tue soluzioni di failover per avvisare immediatamente il tuo staff IT di un guasto in modo che possano lavorare per ripristinare il sistema primario il più rapidamente possibile.
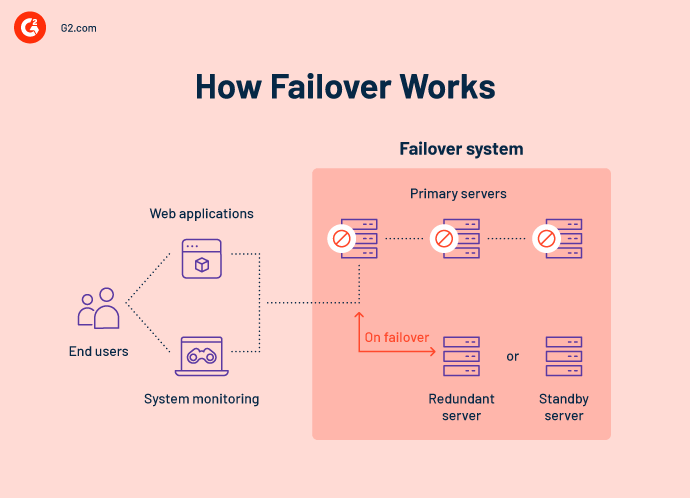
In base alla complessità del servizio, un sistema può persino avere un terzo sito che esegue i componenti fondamentali necessari per evitare il tempo di inattività durante il passaggio. Percorsi multipli, componenti ridondanti e supporto remoto o basato su cloud forniscono un percorso sicuro e sempre connesso.
La virtualizzazione replica un ambiente informatico eseguendo software host su una VM. Pertanto, il meccanismo di failover può essere indipendente dall'hardware.
Questa procedura è solitamente eseguita da un particolare pezzo di software o hardware che abilita questa funzione complessa. Le soluzioni migliori offrono automazione e orchestrazione per facilitare i processi di recupero. Questi sistemi possono anche ripristinare i dati da momenti piuttosto che ore o addirittura giorni fa.
L'integrità del servizio è fondamentale per ridurre al minimo il tempo di inattività durante il failover. Avrai bisogno di una soluzione DRaaS che conosca i tuoi servizi e possa ripristinarli nel loro insieme (piuttosto che semplicemente i componenti), risultando in un ritorno più rapido alle normali operazioni IT.
Cos'è un cluster di failover?
Un cluster di failover è una raccolta di server informatici che lavorano insieme per offrire disponibilità continua (CA), tolleranza ai guasti (FT) o alta disponibilità (HA). Le aziende possono costruire topologie di rete di cluster di failover interamente su hardware fisico o incorporare macchine virtuali (VM).
Quando uno dei server in un cluster di failover si guasta, il meccanismo di failover viene attivato. Questo riduce il tempo di inattività trasferendo istantaneamente il carico di lavoro dell'elemento malfunzionante a un altro nodo nel cluster.
Disponibilità continua vs. tolleranza ai guasti vs. alta disponibilità
- La disponibilità continua è proattiva. Si concentra sulla ridondanza, il rilevamento dei guasti e la prevenzione degli errori. Tali sistemi consentono la pianificazione della manutenzione e gli aggiornamenti durante l'orario lavorativo regolare senza interrompere il servizio.
- Un sistema tollerante ai guasti non ha interruzioni del servizio ma costa leggermente di più. Si basa su hardware dedicato che rileva un guasto e passa istantaneamente a un componente hardware ridondante. Sebbene la transizione sembri fluida e fornisca un servizio continuo, si paga un prezzo significativo per il costo e le prestazioni dell'hardware. Questo perché i componenti ridondanti non eseguono alcun elaborazione. Più importante, il paradigma FT ignora gli errori software, la causa più comune di tempo di inattività.
- Un sistema ad alta disponibilità (HA) causa un'interruzione minima del servizio. HA combina software con hardware standard del settore per ridurre il tempo di inattività ripristinando i servizi quando i sistemi falliscono. Tali sistemi sono una soluzione eccellente per i servizi che devono essere rapidamente ripristinati e resistere a una breve interruzione durante il guasto.
Lo scopo principale di un cluster di failover è fornire HA o CA per applicazioni e servizi. I cluster CA, spesso noti come cluster tolleranti ai guasti, riducono il tempo di inattività quando un sistema primario si arresta, consentendo agli utenti finali di continuare ad accedere ai servizi e alle applicazioni senza interruzioni.
D'altra parte, i cluster HA forniscono un recupero automatizzato, poco tempo di inattività e zero perdita di dati nonostante il rischio di una leggera interruzione dell'operazione. La maggior parte delle soluzioni di cluster di failover fornisce strumenti di gestione del cluster di failover che consentono agli amministratori di controllare il processo.
Un cluster è generalmente composto da due o più server o nodi che sono comunemente collegati programmaticamente e fisicamente utilizzando cavi. Alcuni sistemi di failover utilizzano tecnologie di clustering aggiuntive, come il bilanciamento del carico, l'elaborazione parallela o concorrente e le soluzioni di archiviazione.
Cos'è il test di failover?
Il test di failover conferma la capacità di un sistema di dedicare risorse adeguate al recupero a seguito di un guasto del sistema. In altre parole, il test di failover valuta la capacità di failover del sistema. Il test verificherà se il sistema può gestire risorse aggiuntive e migrare le attività ai sistemi di backup in caso di terminazione o guasto imprevisto.
Ad esempio, il test di failover e recupero verifica la capacità del sistema di gestire e alimentare una CPU aggiuntiva o molti server una volta raggiunta una soglia di prestazioni che viene frequentemente superata durante guasti significativi. Questo sottolinea il legame critico tra test di failover, resilienza e sicurezza.
Il test di failover è il processo di simulazione di un guasto in un server o sistema primario per valutare l'efficacia dei suoi meccanismi di failover. Gli aspetti chiave includono:
- Scopo: Verificare che i sistemi di backup possano subentrare senza problemi durante guasti imprevisti.
- Scenari: Coinvolge il test di vari scenari di guasto come crash del server o interruzioni di rete.
- Automatizzato vs. manuale: Questo può essere fatto manualmente o con strumenti automatizzati.
- Recovery time objective (RTO): Misura quanto rapidamente il sistema si riprende
- Integrità dei dati: Garantisce che i dati rimangano intatti durante il processo di failover.
Tipi di configurazioni di failover
La tecnica del sistema di failover utilizza tecnologie di clustering esistenti per consentire esecuzioni ridondanti, aumentando l'affidabilità e l'accessibilità delle risorse IT.
Esistono due configurazioni di base per i sistemi di failover ad alta disponibilità: attivo-attivo e attivo-passivo. Sebbene entrambe le tecniche di implementazione migliorino l'affidabilità, raggiungono il failover in modi diversi.
1. Configurazione attivo-attivo
Una configurazione ad alta disponibilità attivo-attivo consiste tipicamente in almeno due nodi che eseguono attivamente e contemporaneamente lo stesso tipo di servizio. Il cluster attivo-attivo esegue il bilanciamento del carico distribuendo i carichi di lavoro uniformemente su tutti i nodi, limitando qualsiasi nodo dal sovraccarico. Poiché sono disponibili più nodi, i tempi di risposta e di throughput migliorano.
Le configurazioni e le specifiche dei singoli nodi dovrebbero essere identiche per garantire che il cluster HA funzioni senza problemi e raggiunga la ridondanza. I bilanciatori di carico assegnano gli utenti ai nodi del cluster in base a un algoritmo. Ad esempio, un algoritmo round-robin distribuisce uniformemente gli utenti ai server in base a quando si uniscono.
L'uso di entrambi i nodi è diviso circa 50/50, anche se ciascun nodo può gestire l'intero carico indipendentemente. Tuttavia, se un nodo di configurazione attivo-attivo gestisce regolarmente più della metà del carico, la perdita del nodo potrebbe causare un calo delle prestazioni.
Poiché entrambi i percorsi sono attivi, il tempo di interruzione durante un guasto è quasi trascurabile con un sistema HA attivo-attivo.
2. Configurazione attivo-passivo
In una configurazione attivo-passivo, nota anche come configurazione di standby attivo, ci sono almeno due nodi, ma non tutti sono attivi. In una configurazione a due nodi, il primo nodo è operativo e il secondo nodo rimane passivo o in standby come sistema di failover.
Questo stato operativo di standby può essere supportato se il nodo primario attivo fallisce. D'altra parte, gli utenti si connettono solo al server attivo fino a quando non si verifica un guasto. Il nodo inattivo viene attivato per assumere l'elaborazione da una risorsa IT offline, e il carico di lavoro correlato viene instradato al nodo secondario, che assume l'operazione.
Il tempo di interruzione è più lungo in una configurazione attivo-passivo perché il sistema deve spostarsi da un nodo all'altro.
Failover vs. failback
Il failover e il failback sono elementi di continuità aziendale che consentono alle operazioni digitali regolari di continuare anche se il sito di produzione primario non è disponibile. Considera i processi di failover e failback vitali per un solido framework di disaster recovery.
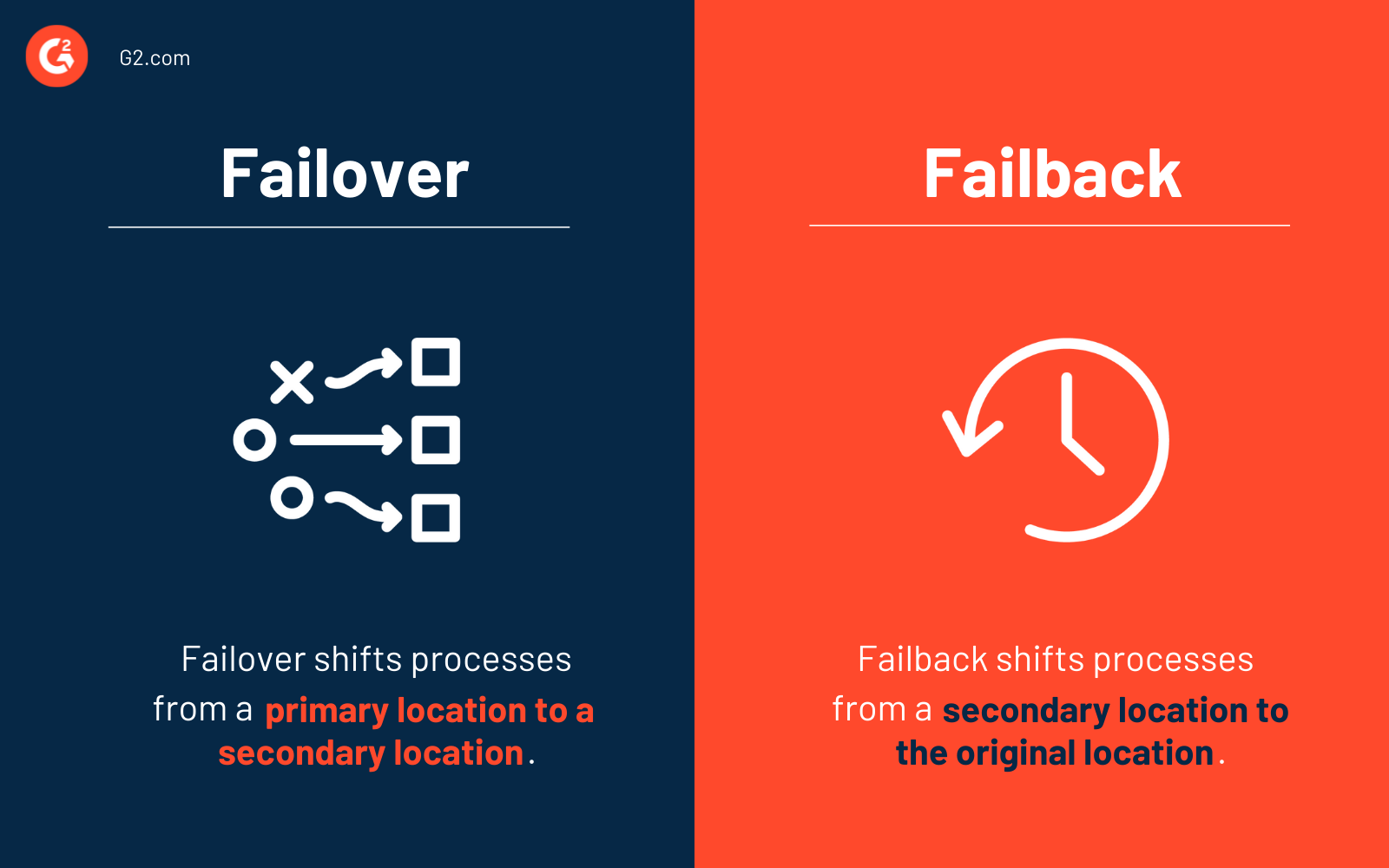
Il processo di failover sposta la produzione dal sito primario a una posizione secondaria. Questo sito di recupero contiene tipicamente una copia replicata di tutti i sistemi e dati del tuo sito di produzione primario. Durante un failover, tutti gli aggiornamenti sono memorizzati virtualmente.
Il failback è una misura di continuità aziendale dispiegata quando il sito di produzione primario è di nuovo operativo dopo che un disastro (o un evento programmato) è stato affrontato. La produzione viene ripristinata al suo vecchio (o nuovo) sito durante un failback, e tutte le modifiche registrate nell'archiviazione virtuale vengono sincronizzate.
Vantaggi del failover
Per le aziende incentrate sul web, il tempo di attività del servizio è fondamentale poiché influisce su tutte le operazioni. Dalla crescita organizzativa alla fidelizzazione dei clienti e alle relazioni, l'alta disponibilità è il criterio essenziale che le aziende non possono ignorare. I vantaggi dei sistemi di failover includono:
- Protezione dal tempo di inattività: Implementare sistemi di failover efficaci per i componenti mission-critical dello stack IT di un'organizzazione dovrebbe ridurre significativamente il tempo di inattività causato da interruzioni del servizio. Se anche uno dei componenti critici del sistema fallisce, impedirà il corretto funzionamento di ogni componente che interagisce con esso.
- Previene la perdita di entrate: Se uno strumento aziendale vitale, come il tuo servizio di elaborazione dei pagamenti, non è disponibile per un lungo periodo, la redditività della tua organizzazione ne risentirà. Poiché le azioni dei consumatori sono volatili, anche un solo incontro negativo può far sì che i clienti smettano definitivamente di utilizzare la tua azienda.
Le sfide del failover
Troppo spesso, il failover è un ripensamento o un'ultima risorsa. Tuttavia, pianificando e testando le procedure di failover in anticipo, i responsabili IT possono prevenire il tempo di inattività e raggiungere livelli costanti di qualità del servizio, specialmente quando accade l'inaspettato.
Un processo di failover ben oliato comporta costi elevati e può aumentare la probabilità di errore umano in caso di guasti. Tuttavia, implementare procedure efficaci può ridurre il rischio di perdita nei sistemi critici e minimizzare le potenziali interruzioni della qualità del servizio.
Anche se il failover sembra un salvatore in tutta la sua gloria, implementare una strategia di failover comporta sfide significative.
Costo aumentato
Impostare, mantenere e monitorare una strategia di failover affidabile e protetta è costoso. Questo è particolarmente vero se vuoi garantire che ogni componente di un paesaggio complesso e interconnesso abbia il suo meccanismo di failover unico.
Per costruire sistemi di failover affidabili che funzionino automaticamente con poco tempo di inattività, devi investire denaro in sistemi ad alta larghezza di banda che possano gestire scambi di dati sincroni. La maggior parte delle spese complessive per i sistemi di failover può essere attribuita all'affidamento a competenze di terze parti per installare e gestire i sistemi.
Processi di gestione del sistema e di assicurazione della qualità (QA) lunghi
Un sistema di failover necessita della stessa manutenzione e convalida QA dei sistemi primari per proteggere efficacemente la tecnologia della tua organizzazione. Eseguire i tuoi sistemi primari e di failover su versioni separate annulla l'avere sistemi identici e sincronizzati in primo luogo, richiedendo più sforzo durante i periodi di manutenzione stretti.
Devi anche assicurarti che i tuoi sistemi di failover possano interagire frequentemente e impegnarsi con i vari componenti dell'ambiente. Queste convalide possono aumentare sostanzialmente il tempo assegnato al tuo staff IT per i test e la QA.
Casi d'uso del failover
Il failover può verificarsi in qualsiasi parte di un sistema, inclusi un computer, una rete, un dispositivo di archiviazione o un server web. Ecco alcuni modi in cui il failover può aiutare le organizzazioni a creare un'infrastruttura resiliente.
- Il failover del server applicativo protegge numerosi server che eseguono applicazioni. Questi server di failover dovrebbero idealmente funzionare su host separati e dovrebbero avere tutti nomi di dominio distinti.
- Il failover del sistema dei nomi di dominio (DNS) garantisce che i servizi di rete o i siti web rimangano disponibili durante un'interruzione. Genera un record DNS per un sistema che include due o più indirizzi IP o connessioni di failover. Questo consente agli utenti di reindirizzare il traffico da un sistema in fallimento verso un sito ridondante e attivo.
- Il failover del protocollo di configurazione host dinamico (DHCP) distribuisce due o più server DHCP per gestire lo stesso pool di indirizzi. Questo consente a ciascun server DHCP di supportare l'altro in caso di perdita di rete. Condividono la responsabilità dell'assegnazione del lease per quel gruppo in ogni momento.
- Il failover del server SQL elimina qualsiasi potenziale punto singolo di guasto impiegando archiviazione dati condivisa e numerose connessioni di rete tramite un network-attached storage (NAS).
Failover con grazia
Sebbene l'integrazione del failover possa essere costosa, considera l'enorme costo del tempo di inattività. Pensa al failover come a una polizza assicurativa essenziale per la sicurezza e la protezione.
Il failover dovrebbe essere un componente chiave della tua strategia di disaster recovery. La tua priorità dovrebbe essere limitare i trasferimenti di dati per evitare colli di bottiglia mantenendo una sincronizzazione di alta qualità tra i sistemi primari e di backup da un approccio di ingegneria dei sistemi.
Scopri come creare un robusto piano di disaster recovery che salvaguardi le tue operazioni e protegga i tuoi beni preziosi.
Questo articolo è stato originariamente pubblicato nel 2022. È stato aggiornato con nuove informazioni.