

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
Si eres alguien como yo, disfrutas de la estructura, el orden y la simplicidad.
Pero en algunos casos, es mejor dar un paso atrás y permitir que se desarrolle un caos organizado. Esta es la base de algo llamado un lago de datos.
¿Qué es un lago de datos?
Definición de lago de datos
Un lago de datos es un repositorio para datos estructurados, no estructurados y semiestructurados. Los lagos de datos son muy diferentes de los almacenes de datos, ya que permiten que los datos estén en su forma más cruda sin necesidad de ser convertidos y analizados primero.
En términos más simples, todo tipo de datos generados tanto por humanos como por máquinas pueden cargarse en un lago de datos para su clasificación y análisis más adelante.
Los almacenes de datos, por otro lado, requieren que los datos estén debidamente estructurados antes de que se pueda realizar cualquier trabajo.
Para obtener una comprensión más profunda de los lagos de datos y por qué son el candidato óptimo para albergar big data, es importante profundizar en lo que los hace tan diferentes de los almacenes de datos.
¿Quieres aprender más sobre Soluciones de Almacén de Datos? Explora los productos de Almacén de Datos.
Lago de datos vs. almacén de datos
Tanto los lagos de datos como los almacenes de datos son repositorios para datos. Esa es prácticamente la única similitud entre los dos. Ahora, toquemos algunas de las diferencias clave:
- Los lagos de datos están diseñados para soportar todo tipo de datos, mientras que los almacenes de datos utilizan datos altamente estructurados, en la mayoría de los casos.
- Los lagos de datos almacenan todos los datos que pueden o no ser analizados en algún momento en el futuro. Este principio no se aplica a los almacenes de datos, ya que los datos irrelevantes suelen eliminarse debido al almacenamiento limitado.
- La escala entre los lagos de datos y los almacenes de datos es drásticamente diferente debido a nuestros puntos anteriores. Soportar todo tipo de datos y almacenar esos datos (incluso si no son inmediatamente útiles) significa que los lagos de datos necesitan ser altamente escalables.
- Gracias a los metadatos (datos sobre datos), los usuarios que trabajan con un lago de datos pueden obtener información básica sobre los datos rápidamente. En los almacenes de datos, a menudo se requiere un miembro del equipo de desarrollo para acceder a los datos, lo que podría crear un cuello de botella.
- Por último, la intensa gestión de datos requerida para los almacenes de datos significa que suelen ser más caros de mantener en comparación con los lagos de datos.
James Dixon, fundador y Director de Tecnología de Pentaho, acuñó el término "lago de datos" después de proporcionar una analogía que diferencia los lagos de datos de los almacenes de datos.
“Si piensas en un datamart como una tienda de agua embotellada, limpia y empaquetada y estructurada para un fácil consumo, el lago de datos es un gran cuerpo de agua en un estado más natural”, dijo Dixon. “El contenido del lago de datos fluye desde una fuente para llenar el lago, y varios usuarios del lago pueden venir a examinar, sumergirse o tomar muestras.”
James Dixon
fundador y Director de Tecnología de Pentaho
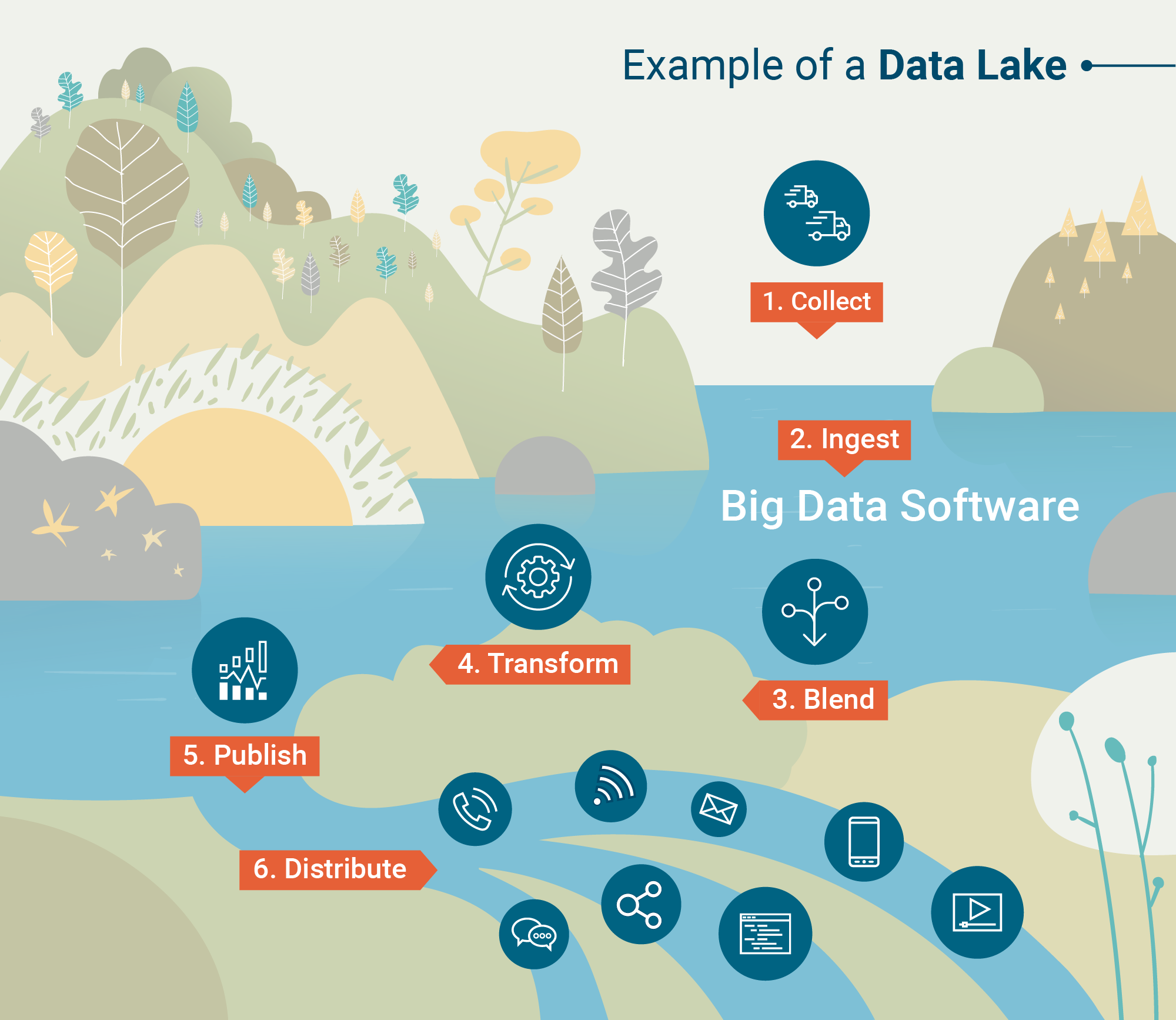
Arquitectura de lago de datos
Entonces, ¿cómo son capaces los lagos de datos de almacenar cantidades tan vastas y diversas de datos? ¿Cuál es la arquitectura subyacente de estos enormes repositorios?
Los lagos de datos se construyen sobre un modelo de datos esquema en lectura. Un esquema es esencialmente el esqueleto de una base de datos que describe su modelo y cómo se estructurarán los datos dentro de ella. Piensa en un plano.
El modelo de datos esquema en lectura significa que puedes cargar tus datos en el lago tal como están sin tener que preocuparte por su estructura. Esto permite mucha más flexibilidad.
Los almacenes de datos, por otro lado, están compuestos por modelos de datos esquema en escritura. Este es un modelo mucho más tradicional para bases de datos.
Cada conjunto de datos, cada relación y cada índice en el modelo de datos esquema en escritura debe definirse claramente de antemano. Esto limita la flexibilidad, especialmente al agregar nuevos conjuntos de datos o características que podrían crear brechas dentro de la base de datos.
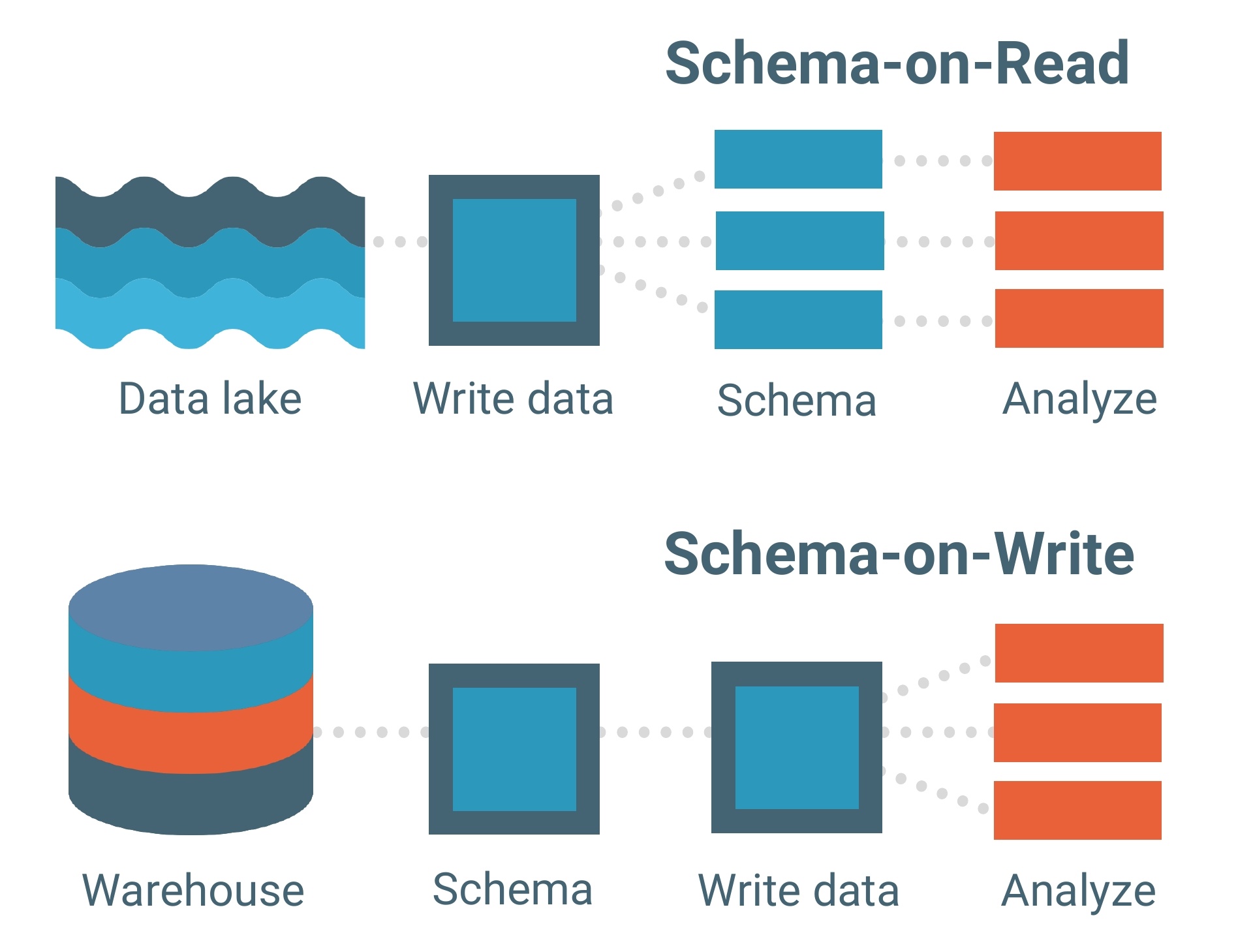
El modelo de datos esquema en lectura actúa como la columna vertebral de un lago de datos, pero el marco de procesamiento (o motor) es cómo los datos realmente se cargan en uno.
A continuación se presentan los dos marcos de procesamiento que "ingieren" datos en los lagos de datos:
- Procesamiento por lotes – Millones de bloques de datos procesados durante largos períodos de tiempo (de horas a días). El método menos sensible al tiempo para procesar big data.
- Procesamiento en tiempo real – Pequeños lotes de datos procesados en tiempo real. El procesamiento en tiempo real se está volviendo cada vez más valioso para las empresas que aprovechan el análisis en tiempo real.

Hadoop, Apache Spark y Apache Storm se encuentran entre las herramientas de procesamiento de big data más comúnmente utilizadas que son capaces de realizar procesamiento por lotes o en tiempo real.
Algunas herramientas son particularmente útiles para procesar datos no estructurados como la actividad de sensores, imágenes, publicaciones en redes sociales y actividad de clics en internet. Otras herramientas priorizan la velocidad de procesamiento y la utilidad con programas de aprendizaje automático.
Una vez que los datos se procesan e ingieren en el lago de datos, es hora de hacer uso de ellos.
¿Para qué se utilizan los lagos de datos?
Los almacenes de datos dependen de la estructura y los datos limpios, mientras que los lagos de datos permiten que los datos estén en su forma más natural. Esto se debe a que las herramientas analíticas avanzadas y el software de minería de datos toman datos en bruto y los transforman en información útil.
Análisis de big data
El análisis de big data se sumergirá en un lago de datos en un intento de descubrir patrones, tendencias del mercado y preferencias de los clientes para ayudar a las empresas a hacer predicciones informadas más rápidamente. Esto se hace a través de cuatro análisis diferentes.
- Análisis descriptivo – Un análisis retrospectivo que examina "dónde" puede haber ocurrido un problema para una empresa. La mayoría de los análisis de big data hoy en día son en realidad descriptivos porque se pueden generar rápidamente.
- Análisis diagnóstico – Otro análisis retrospectivo que examina "por qué" puede haber ocurrido un problema específico para una empresa. Esto es un poco más profundo que el análisis descriptivo.
- Análisis predictivo – Cuando se aplican software de IA y aprendizaje automático, este análisis puede proporcionar a una organización modelos predictivos de lo que puede ocurrir a continuación. Debido a la complejidad de generar análisis predictivos, aún no se ha adoptado ampliamente.
- Análisis prescriptivo – El futuro del análisis de big data son los análisis prescriptivos que no solo ayudan en los esfuerzos de toma de decisiones, sino que incluso pueden proporcionar a una organización un conjunto de respuestas. Hay un uso muy alto de aprendizaje automático con estos análisis.
Minería de datos
La minería de datos se define como "descubrimiento de conocimiento en bases de datos", y es cómo los científicos de datos descubren patrones y verdades previamente no vistas a través de varios modelos.
Por ejemplo, un análisis de agrupamiento es un tipo de técnica de minería de datos que se puede aplicar a un conjunto dentro de un lago de datos. Esto agrupará grandes cantidades de datos en función de sus similitudes.
A través de herramientas de visualización de datos, la minería de datos ayuda a aclarar la naturaleza caótica de los datos no estructurados y en bruto.
Desafíos de los lagos de datos
Los lagos de datos pueden ser flexibles, escalables y rápidos de cargar, pero eso tiene un precio.
Ingerir datos no estructurados requiere una falta de gobernanza de datos y procesos que aseguren que se están mirando los datos correctos. Para la mayoría de las empresas, especialmente aquellas que aún no han adoptado big data, tener datos desorganizados y no limpiados no es una opción.
El mal uso de los metadatos o los procesos para mantener el lago de datos bajo control puede llevar a algo llamado un pantano de datos. ¿Te meterías a nadar en un pantano?
También está el problema de la seguridad de los datos.
Los lagos de datos son un concepto bastante nuevo en TI, lo que significa que algunas de las herramientas aún están resolviendo los problemas de seguridad. Uno de estos problemas es asegurar que solo las personas correctas tengan acceso a los datos sensibles cargados en el lago.
Pero como cualquier nueva tecnología, estos problemas se resolverán con el tiempo.
| CONSEJO: ¿Listo para sumergirte más en el mundo de los datos? Aprende los conceptos básicos de la gestión de datos maestros (MDM) y por qué es importante para las empresas. |
El papel de los lagos de datos con big data
A pesar de algunos de los desafíos de los lagos de datos, el hecho es que más del 80 por ciento de todos los datos no están estructurados. A medida que más empresas recurren a big data para futuras oportunidades, la aplicación de los lagos de datos aumentará.
Datos no estructurados como publicaciones en redes sociales, grabaciones de llamadas telefónicas y actividad de clics contienen información valiosa que no puede ser retenida en almacenes de datos.
Mientras que los almacenes de datos son fuertes en estructura y seguridad, big data simplemente necesita estar sin restricciones para que pueda fluir libremente en los lagos de datos.
Consulta nuestra guía completa sobre datos estructurados vs no estructurados para una explicación más detallada o lee sobre la importancia de la ingeniería de big data.