Die Technologie entwickelt sich in rasantem Tempo weiter, und obwohl sie manchmal überwältigend erscheinen mag, erleichtert sie unsere täglichen Aufgaben.
Von der Bestellung unseres Morgenkaffees per Sprachbefehl bis hin zur Suche nach der schnellsten Route ins Büro sind diese Annehmlichkeiten zur zweiten Natur geworden. Aber was wäre, wenn Ihre Geräte die Welt um uns herum genauso verstehen und mit ihr interagieren könnten wie ein Mensch?
Mit der Kraft der künstlichen Intelligenz (KI) und der Computer-Vision-Technologie können wir das jetzt.
Was ist "You Only Look Once" (YOLO)?
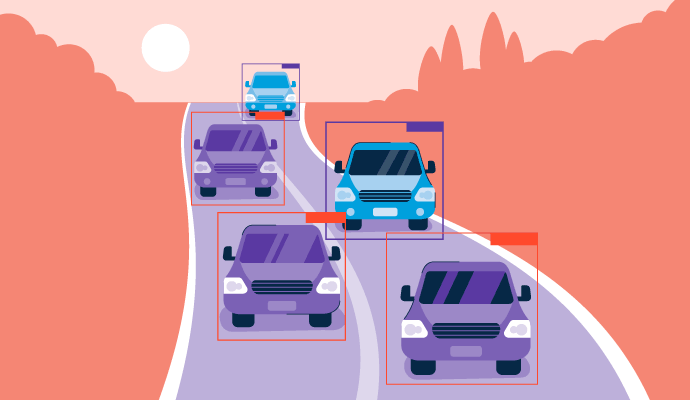
"You Only Look Once", oder YOLO, ist ein Echtzeit-Objekterkennungsalgorithmus, der erstmals 2015 entwickelt wurde. Er sagt die Wahrscheinlichkeit voraus, dass ein Objekt in einem Bild oder Video vorhanden ist. Es handelt sich um einen spezifischen Algorithmus, der das aktuelle Feld der Objekterkennung in der Computer-Vision-Technologie verbessert, bei dem Objekte in Bildern lokalisiert und identifiziert werden.
YOLO muss das Visuelle nur einmal überprüfen, um diese Vorhersagen zu treffen, daher der Name, und kann auch als Single-Shot-Objekterkennung (SSD) bezeichnet werden. Es ist ein wichtiger Teil des Objekterkennungsprozesses, den viele Bildverarbeitungssoftware-Produkte verwenden, um zu verstehen, was visuelle Medien darstellen.
Durch die Verwendung von End-to-End-Neuronalen Netzwerken kann dieser Algorithmus sowohl den Standort (Begrenzungsrahmen) als auch die Identität (Klassifizierung) von Objekten in einem Bild gleichzeitig vorhersagen. Dies war ein Sprung von traditionellen Objekterkennungs-Algorithmen, die bestehende Klassifikatoren umfunktionierten, um diese Informationen vorherzusagen.
Wie "You Only Look Once" funktioniert
YOLO basiert auf einem einzigen Convolutional Neural Network (CNN), einem Schlüsselelement des Deep Learning und einer Art von KI-Netzwerk, das Modelleingaben filtert, um nach erkennbaren Mustern zu suchen. Die Schichten in diesen Netzwerken sind so formatiert, dass sie zuerst die einfachsten Muster erkennen, bevor sie zu komplexeren übergehen.
Obwohl CNNs für mehr als nur die Bildverarbeitung verwendet werden, sind sie ein grundlegender Bestandteil der YOLO-Architektur. Wenn ein Bild in ein YOLO-basiertes Modell eingegeben wird, durchläuft es mehrere Schritte, um Objekte innerhalb dieses visuellen Mediums zu erkennen. Hier ist eine Aufschlüsselung:
- Eingabebild: Das gesamte Bild, sei es ein statisches Foto, eine Grafik oder ein Videoformat, wird durch das Modell geleitet. Merkmale des Bildes werden extrahiert und durch verbundene Schichten geleitet, um die Klassifikationen und Begrenzungsrahmenkoordinaten vorherzusagen.
- Rasterteilung: Das Eingabebild wird dann in Kästchen in einer Rasterformation unterteilt. Jedes kleine Quadrat oder jede Zelle des Rasters ist damit beauftragt, Objekte innerhalb seines Abschnitts zu erkennen und einen Wahrscheinlichkeits- oder Vertrauenswert für jedes erkannte Objekt bereitzustellen.
- Objekterkennung: Wenn ein Raster vorhergesagt wird, ein Objekt zu enthalten, wird es als signifikante Zellen hervorgehoben. Das Modell bestimmt dann den Objekttyp und seinen Standort innerhalb des Rasters in einem einzigen Durchgang.
- Bewertung der Begrenzungsrahmen: Das Modell zeichnet Kästchen um die erkannten Objekte, bekannt als Begrenzungsrahmen. Jede Rasterzelle kann mehrere Begrenzungsrahmen erzeugen, wenn sich mehr als ein Objekt in dieser Zelle befindet. Begrenzungsrahmen können auch Zellen überlappen, um jedes Objekt im gesamten Bild vollständig zu umfassen. Jedem Begrenzungsrahmen wird ein Vertrauenswert zugewiesen, der angibt, wie wahrscheinlich es ist, dass die Vorhersage korrekt ist.
- Ausgabe: Nachdem die Rasterquadrate bewertet wurden, listet die endgültige Ausgabe alle Objekte im Bild auf, zusammen mit jedem Begrenzungsrahmen und seinem Etikett. Als Teil der Nachbearbeitung wird eine nicht-maximale Unterdrückung (NMS) durchgeführt, um überlappende Kästchen zu entfernen und sicherzustellen, dass jedes Objekt nur durch ein Kästchen mit dem höchsten Vertrauenswert dargestellt wird. Dieser Schritt verbessert die Genauigkeit der Objekterkennung und macht den gesamten Prozess effizienter, indem er zusätzliches Rauschen herausfiltert, um eine sauberere Ausgabe zu erzeugen.
Möchten Sie mehr über Bildverarbeitungssoftware erfahren? Erkunden Sie Bilderkennung Produkte.
Arten von YOLO in der Objekterkennung
Seit seiner Entwicklung hat YOLO mehrere Iterationen durchlaufen, die aktualisierte Technologien integriert und einen schnelleren, effizienteren Arbeitsablauf geschaffen haben. Hier ist ein kurzer Überblick über YOLO v1-v6 und ein Blick darauf, wo wir heute stehen:
- YOLOv1: Der ursprüngliche Algorithmus konzentrierte sich hauptsächlich auf die Objekterkennung als Regressionsproblem anstelle der traditionellen Klassifikationsansätze, was zu dieser Zeit bahnbrechend war. Diese Grundlage wird noch heute in YOLO-Modellen verwendet.
- YOLOv2: Auch bekannt als YOLO 9000, baute diese Version auf den ursprünglichen Konzepten von YOLO auf und adressierte einige der Einschränkungen des ersten Modells. Ankerkästchen wurden als vorbestimmte Kästchen innerhalb des Rasters eingeführt, mit einzigartigen Seitenverhältnissen und Skalen. Dies erleichterte die Vorhersage von Begrenzungsrahmen und passte besser zu tatsächlichen Objekten im Bild. Die Version beinhaltete auch Updates, um hochauflösende Bilder ohne Verlangsamung der Verarbeitungszeiten zu handhaben.
- YOLOv3: Diese Version führte eine Technik namens "Feature Pyramid Network" (FPN) ein, die verwendet wurde, um unterschiedlich große Objekte im Bild zu erkennen. Die Verarbeitungsgeschwindigkeit wurde in der dritten Version von YOLO auch durch die Verwendung von Darknet-53 gesteigert.
- YOLOv4: Mit einer aktualisierten Version von Darknet, CSPDarnet, war die vierte Version von YOLO erheblich schneller und genauer als frühere Iterationen. Die Genauigkeit verbesserte sich im Durchschnitt um etwa 0,5 % dank der Einführung einer Technik namens "Cross-State Partial Connection" oder CSP, bei der mehrere Modelle gleichzeitig eingeführt wurden, um ihre Vorhersagefähigkeiten zu kombinieren.
- YOLOv5: Eingeführt im Jahr 2020, führte die fünfte Version von YOLO eine aktualisierte neuronale Netzwerkarchitektur namens EfficientDet ein. EfficientDet war eine Reihe von Bildklassifikationsmodellen, die darauf ausgelegt waren, die Rechengenauigkeit und den Speicherverbrauch zu verbessern und gleichzeitig die höchsten Genauigkeitsstufen der Ausgabe zu erreichen. Ankerkästchen waren mit Version 5 nicht mehr erforderlich, da eine einzige Faltungsschicht in der Lage war, Begrenzungsrahmen von Objekten direkt vorherzusagen, unabhängig von ihrer Form oder Größe.
- YOLOv6: Die Einführung eines neuen, leichteren neuronalen Netzwerks bedeutete, dass Version 6 von YOLO effizienter lief und weniger Ressourcen benötigte. Während des Trainings wurde auch die Datenaugmentation eingeführt, die es dem Modell ermöglicht, Objekte auch dann zu erkennen, wenn sie im Eingabebild gedreht, skaliert oder gespiegelt sind.
Die neuesten Updates zu YOLO, Versionen 7 bis 9, haben weiterhin größere Geschwindigkeits- und Genauigkeitsverbesserungen erfahren, da der Algorithmus basierend auf aktuellen Durchbrüchen im Deep Learning angepasst wird. Die Lernkapazität des Algorithmus hat sich mit diesen neueren Modellen erheblich erhöht, sodass die Objekterkennung auch bei verschwommenen oder unvollständigen Bilddaten möglich ist.
Branchen, die "You Only Look Once" nutzen
Es gibt zahlreiche Möglichkeiten, wie YOLO im Alltag implementiert werden kann, aber einige Branchen profitieren mehr von dieser Technologie als andere.
Sicherheit
Überwachungssysteme werden jedes Jahr komplexer und helfen, uns überall sicher zu halten. YOLO wird häufig verwendet, um Personen zu erkennen, die von Strafverfolgungsbehörden durch CCTV- und Sicherheitskamerasysteme überwacht werden, während gleichzeitig Verbrechen wie Ladendiebstahl oder Übergriffe in Echtzeit überwacht werden.
Gesundheitswesen
Wie andere Formen der Objekterkennung und Bildverarbeitung kann YOLO in der Echtzeit-Medizinversorgung und Bildbehandlung eingesetzt werden. Mehrere Studien haben eine weit verbreitete Nutzung von YOLO in dieser Branche festgestellt, einschließlich chirurgischer Eingriffe, bei denen die Erkennung von Organen aufgrund der biologischen Vielfalt verschiedener Patienten erforderlich ist.
Sowohl 2D- als auch 3D-Scans können schnell und genau die Organplatzierung bestimmen und Einblicke in potenzielle Probleme bieten, die durch medizinische Bildgebung erkannt werden sollen.
Landwirtschaft
Die Entwicklung von KI hat der Landwirtschaft erheblich geholfen, Landwirten die Möglichkeit zu geben, ihre Ernten jederzeit zu überwachen, ohne dass eine manuelle Überwachung erforderlich ist. YOLO und landwirtschaftliche Roboter haben in vielen Fällen das manuelle Pflücken und Ernten ersetzt. Es wird auch verwendet, um zu bestimmen, wann die Ernte basierend auf Farb- oder Größenmerkmalen der Objekte (Ernten) in Bildern am reifsten ist.
Autonome Fahrzeuge
Für selbstfahrende Autos hilft YOLO, Verkehrsschilder, Fußgänger und andere Straßenhindernisse mit Geschwindigkeit und Präzision zu identifizieren, ähnlich wie ein menschlicher Fahrer.
Vorteile von YOLO
Es gibt zahlreiche Vorteile, die mit der Verwendung von Algorithmen wie YOLO in KI-Modellen zur Objekterkennung einhergehen, insbesondere in Bezug auf Geschwindigkeit und Genauigkeit.
- Echtzeitanwendungen: Für Branchen, in denen Zeitmanagement und schnelle Reaktionsfähigkeit entscheidend sind, wie selbstfahrende Autos und Sicherheit, ist YOLO eine der besten automatisierten Optionen zur Objekterkennung in einem Bild oder Video.
- Hohe Genauigkeit: Mit jeder neuen Version von YOLO wird der Algorithmus genauer bei der Objekterkennung mit Vertrauen in die Ausgabe der Begrenzungsrahmen. Sowohl die Klassifikationen als auch die Standorte von Objekten in Bildern werden jedes Mal genauer.
- Einzelschuss-Effizienz: Anstatt darauf zu warten, dass Bilder durch mehrere Schichten eines neuronalen Netzwerks geleitet werden, kann YOLO Informationen in einem einzigen Schritt verarbeiten, um seine Gesamteffizienz und Geschwindigkeit zu verbessern.
- Fähigkeit, Bilder unterschiedlicher Maßstäbe zu bewerten: YOLO ist jetzt in der Lage, Bilder mit unterschiedlichen Seitenverhältnissen zu verarbeiten und unterschiedlich große Objekte innerhalb von Modellen zu bestimmen, die Ankerkästchen verwenden, sowie solche ohne.
Top-Bildverarbeitungstools, die für "You Only Look Once" verwendet werden
YOLO mag nur für eine spezifische Rolle in der Bildverarbeitung, der Objekterkennung, verwendet werden, aber diese Tools können in Arbeitsabläufe integriert werden, um viele weitere Aufgaben zu erledigen. Die Objekterkennung ist nur ein Teil davon, wie Bilder mit KI verarbeitet werden, wobei Aspekte wie Bildwiederherstellung und Szenenrekonstruktion mit dieser Software ebenfalls möglich sind.
Um in die Kategorie der Bildverarbeitung aufgenommen zu werden, müssen Plattformen:
- Einen Deep-Learning-Algorithmus speziell für die Bildverarbeitung bereitstellen
- Mit Bilddatensätzen verbunden sein, um eine spezifische Lösung oder Funktion zu erlernen
- Die Bilddaten als Eingabe konsumieren und eine Ausgabe bereitstellen
- Bildverarbeitungsfähigkeiten für andere Anwendungen, Prozesse oder Dienste bereitstellen
* Unten sind die fünf führenden Bildverarbeitungssoftwarelösungen aus dem G2 Summer 2024 Grid Report aufgeführt. Einige Bewertungen können zur Klarheit bearbeitet worden sein.
1. Google Cloud Vision API
Google Cloud Vision API kann mehrere Objekte innerhalb von Bildern mit einem vortrainierten Algorithmus erkennen und klassifizieren, der in Ihre eigenen Modelle integriert werden kann. Diese Software hilft Entwicklern, die Kraft des maschinellen Lernens mit branchenführender Vorhersagegenauigkeit zu nutzen.
Was Benutzer am meisten mögen:
„Das hilfreichste, was ich über dieses spezielle Vision-API-Tool von Google erlebt habe, ist seine Integrationsfunktion zur Erkennung in unseren Deep- und Machine-Learning-Projekten. Seine API hilft uns, Objekte zu erkennen und sie mit menschlichem Verständnis zu kennzeichnen und ein maschinelles Lernmodell zu bilden.“
- Google Cloud Vision API Review, Kunal D.
Was Benutzer nicht mögen:
„Bei Bildern von geringer Qualität gibt es manchmal die falsche Antwort, da einige Lebensmittel die gleiche Farbe haben. Es bietet uns nicht die Möglichkeit, das Modell für unseren spezifischen Anwendungsfall anzupassen oder zu trainieren. Der Konfigurationsteil ist komplex.“
- Google Cloud Vision API Review, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit ist eine plattformübergreifende und quelloffene maschinelle Lernbibliothek. Es spricht Entwickler und KI-Ingenieure an, da es Echtzeit-Gesten- und Bildverarbeitungsoptionen bietet, die in ihre eigenen Algorithmen und Modelle integriert werden können.
Was Benutzer am meisten mögen:
„Sein umfangreiches Set an Algorithmen und die benutzerfreundliche Oberfläche machen es sowohl für Anfänger als auch für fortgeschrittene Benutzer geeignet.“
- Gesture Recognition Toolkit Review, Ram M.
Was Benutzer nicht mögen:
„Das Gesture Recognition Toolkit hat gelegentlich Verzögerungen und einen weniger reibungslosen Implementierungsprozess. Die Reaktionszeiten des Kundensupports könnten schneller sein.“
- Gesture Recognition Toolkit Review, Civic V.
3. SuperAnnotate
SuperAnnotate ist eine Plattform zum Erstellen, Feinabstimmen und Verwalten Ihrer KI-Modelle mit den hochwertigsten, branchenführenden Trainingsdaten. Fortschrittliche Anmerkungstechnologie und Qualitätssicherungswerkzeuge ermöglichen es Ihnen, erfolgreiche maschinelle Lernmodelle und hochwertige Datensätze zu erstellen.
Was Benutzer am meisten mögen:
„Ich suchte nach einem Tool zur Annotation biologischer Bilder. Nachdem ich viele Tools ausprobiert hatte, fand ich zwei der besten Plattformen für mich. Eine davon ist Superannotate. Diese Plattformen hatten das breiteste Set an Annotationswerkzeugen, einschließlich genau derjenigen, die ich benötigte. Die Werkzeuge sind bequem zu verwenden.“
- SuperAnnotate Review, Artem M.
Was Benutzer nicht mögen:
„Wir hatten einige Probleme mit benutzerdefinierten Workflows, die das Team für spezifische Projekte auf ihrer Plattform implementiert hat. Bei bestimmten benutzerdefinierten Workflows haben wir festgestellt, dass das Analysetool die für die Annotation benötigte Zeit falsch meldete.“
- SuperAnnotate Review, Rohan K.
4. Syte
Syte ist die weltweit erste KI-gestützte Produkterkennungsplattform, die sowohl Verbrauchern als auch Einzelhändlern hilft, mit Produkten in Kontakt zu treten. Kamerasuche, Personalisierung und In-Store-Tools wie Bildverarbeitung sorgen für ein sofortiges und intuitives Erlebnis für Käufer.
Was Benutzer am meisten mögen:
„Das Team bietet konsequent wertvolle Einblicke und Alternativen, um die Funktionalität und Effektivität des Shop Similar Tools zu verbessern. Die Zusammenarbeit mit Syte erleichtert das Erreichen der spezifischen KPIs unserer Website.“
- Syte Review, Gabriella M.
Was Benutzer nicht mögen:
„Es gab einige Schwierigkeiten bei der Aktivierung verschiedener Konten für das Analysetool-Dashboard. Es wäre schön, keine Einschränkungen bei diesen Anmeldungen zu haben (verschiedene Benutzer sollten darauf zugreifen können).“
- Syte Review, Antonio R.
5. Dataloop
Dataloop ist eine KI-Entwicklungsplattform, die es Unternehmen ermöglicht, ihre eigenen KI-Anwendungen einfach und mit intuitiven Datensätzen zu erstellen. Werkzeuge innerhalb der Software ermöglichen es Teams, die Bildannotation, die Modellauswahl und die Bereitstellung von Modellen für den großflächigen Einsatz zu optimieren.
Was Benutzer am meisten mögen:
„Dataloop hat auch eine große Anzahl von Funktionen, die es für viele Benutzer verschiedener Projekte bequem machen. Nach jedem Update werden Anweisungen bereitgestellt, die die Änderungen erklären und somit die Implementierung erleichtern.“
- Dataloop Review, Mzamil J.
Was Benutzer nicht mögen:
„Ich hatte Herausforderungen mit einigen steilen Lernkurven, Infrastrukturabhängigkeit und Anpassungsbeschränkungen. Diese haben mich in gewisser Weise in der Nutzung eingeschränkt.“
- Dataloop Review, Dennis R.

Beginnen Sie mit der Arbeit mit KI, denn YOLO!
In weniger als einem Jahrzehnt hat YOLO erhebliche Fortschritte gemacht und ist die bevorzugte Methode der Objekterkennung für viele Branchen geworden. Dank seines effizienten und genauen Ansatzes zur Bildverarbeitung ist es ideal für Echtzeitanforderungen, während Sie die Welt der KI erkunden.
Erfahren Sie mehr über künstliche neuronale Netze und wie Modelle entworfen werden, um das menschliche Gehirn nachzuahmen.
Bearbeitet von Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.

