Stellen Sie sich vor, Sie könnten mühelos ein ganzes Buch von einer Sprache in eine andere übersetzen oder Seiten mit dichtem Text in ein paar klare Sätze zusammenfassen – alles mit nur wenigen Klicks.
Für Praktiker des maschinellen Lernens (ML) fühlt sich das Erreichen solcher Aufgaben an, als würde man durch ein Labyrinth von Komplexitäten navigieren. Sequenzielle Daten stellen einzigartige Herausforderungen dar: rauschende Eingaben, versteckte Abhängigkeiten und Vorhersagen, die ins Wanken geraten, wenn der Kontext verloren geht.
Seq2Seq-Modelle sind darauf ausgelegt, genau diese Herausforderungen zu bewältigen.
Was ist Seq2Seq?
Sequence-to-sequence (Seq2Seq) ist ein maschinelles Lernmodell, das darauf ausgelegt ist, eine Eingabesequenz in eine Ausgabesequenz abzubilden. Dieser Ansatz wird häufig bei Aufgaben verwendet, bei denen sich Eingabe und Ausgabe in der Länge unterscheiden, wie z.B. bei der Sprachübersetzung, Textzusammenfassung oder Sprach-zu-Text-Konvertierung.
Seq2Seq-Modelle werden häufig in Datenwissenschafts- und ML-Plattformen und Software zur Verarbeitung natürlicher Sprache (NLP) integriert und bieten robuste Lösungen für reale Anwendungen wie die maschinelle Übersetzung. Sie sind besonders effektiv bei Aufgaben der neuronalen maschinellen Übersetzung und ermöglichen eine nahtlose Textkonvertierung zwischen Sprachen wie Englisch und Französisch, während sie grammatikalische Genauigkeit und Flüssigkeit beibehalten.
Im Gegensatz zu traditionellen Algorithmen sind Seq2Seq-Modelle darauf ausgelegt, Sequenzen zu verarbeiten und dabei Kontext und Reihenfolge beizubehalten. Dies macht sie besonders geeignet für Aufgaben, bei denen die Bedeutung der Eingabe von der Reihenfolge der Datenpunkte abhängt, wie z.B. bei Sätzen oder Zeitreihendaten.
Lassen Sie uns erkunden, wie Seq2Seq funktioniert und warum es ein wesentliches Werkzeug für Anwendungen neuronaler Netzwerke ist. Wenn Sie bereit sind, reale Herausforderungen mit ML anzugehen, sind Sie hier genau richtig!
Wie funktioniert das Seq2Seq-Modell?
Seq2Seq-Modelle verlassen sich auf eine gut definierte Struktur, um Sequenzen zu verarbeiten und sinnvolle Ausgaben zu erzeugen. Durch eine sorgfältig gestaltete Architektur stellen sie sicher, dass sowohl Eingabe- als auch Ausgabesequenzen mit Präzision und Kohärenz behandelt werden.
Lassen Sie uns die Kernkomponenten dieser Architektur erkunden und wie sie zur Effektivität des Modells beitragen.
Architektur des Seq2Seq-Modells
Die Architektur des Seq2Seq-Modells umfasst typischerweise:
- Eingabeschicht. Diese Schicht nimmt die Eingabesequenz auf und wandelt sie in Einbettungen für die weitere Verarbeitung um. In praktischen Implementierungen repräsentieren Einbettungen oft Sequenzen von Wörtern, Tokens oder anderen Datenpunkten, abhängig von der Aufgabe, wie z.B. Textzusammenfassung oder Sprachübersetzung.
- Encoder. Der Encoder besteht typischerweise aus einem rekurrenten neuronalen Netzwerk (RNN), Long Short-Term Memory (LSTM) oder Gated Recurrent Unit (GRU), das die Eingabesequenz verarbeitet und einen Kontextvektor erzeugt, der die Sequenz zusammenfasst.
- Decoder. Wie der Encoder wird auch ein Decoder mit RNN-, LSTM- oder GRU-Architekturen aufgebaut. Er generiert die Ausgabesequenz, indem er sich auf den Kontextvektor stützt.
- Aufmerksamkeitsmechanismus (falls verwendet). Der Aufmerksamkeitsmechanismus wird oft als Teil des Decoders implementiert, wo er während des Dekodierungsprozesses dynamisch relevante Teile der Eingabesequenz auswählt, um die Genauigkeit zu verbessern.
1. Die Rolle des Encoders
Die Aufgabe des Encoders besteht darin, die Eingabesequenz zu verstehen und zusammenzufassen, oft indem er die Sequenz in eine Einbettung fester Größe abbildet. Diese Einbettungen helfen, kritische Merkmale zu bewahren, insbesondere bei Aufgaben wie der maschinellen Übersetzung von Englisch nach Französisch. Der Encoder aktualisiert seinen versteckten Kontextzustand bei jedem Zeitschritt, um wesentliche Abhängigkeiten zu bewahren.
Gleichung zur Aktualisierung des versteckten Zustands des Encoders:
ht=tanh(W_h*h_(t-1)+W_x*x_t+b_h)Wo:
- ht ist der versteckte Zustand zum Zeitpunkt t
- h_(t-1) ist der vorherige versteckte Zustand
- x_t ist die Eingabe zum Zeitpunkt t
- W_h und W_x sind Gewichtsmatrizen
- b_h ist der Bias-Term
- tanh ist die Aktivierungsfunktion
Wichtige Punkte über den Encoder:
- Er verarbeitet Eingaben ein Element nach dem anderen (z.B. Wort für Wort oder Zeichen für Zeichen).
- Bei jedem Schritt aktualisiert er den internen Zustand des Encoders basierend auf dem aktuellen Element und den vorherigen Zuständen.
- Er erzeugt einen Kontextvektor, der die Informationen enthält, die der Decoder benötigt, um die Ausgabe zu erzeugen.
2. Die Rolle des Decoders
Der Decoder beginnt mit dem Kontextvektor des Encoders und sagt die Ausgabesequenz Schritt für Schritt voraus. Er aktualisiert seinen versteckten Zustand basierend auf dem vorherigen Zustand, dem Kontextvektor und dem zuletzt vorhergesagten Wort.
Gleichung zur Aktualisierung des versteckten Zustands des Decoders:
st=tanh(W_s*s_(t-1)+ W_y*y_(t-1)+ W_c*c_t+b_s)Wo:
- st: Versteckter Zustand des Decoders zum Zeitpunkt t
- s_(t-1): Vorheriger versteckter Zustand des Decoders
- y_(t-1): Vorherige Ausgabe oder vorhergesagtes Token
- c_t: Kontextvektor (aus der Encoder-Ausgabe)
- W_s, W_y, W_c: Gewichtsmatrizen
- b_s: Bias-Term
- tanh: Aktivierungsfunktion
Wichtige Punkte über den Decoder:
- Der Decoder erzeugt die Ausgabe Schritt für Schritt und sagt das nächste Element basierend auf dem Kontextvektor und den vorherigen Vorhersagen voraus.
- Er fährt fort, bis er ein einzigartiges Token (z.B. <END>) ausgibt, das das Ende der Sequenz signalisiert.
3. Der Aufmerksamkeitsmechanismus
Aufmerksamkeit ist eine leistungsstarke Erweiterung, die oft zu Seq2Seq-Modellen hinzugefügt wird, insbesondere bei der Verarbeitung längerer Sätze. Anstatt sich ausschließlich auf einen Kontextvektor zu verlassen, ermöglicht Aufmerksamkeit dem Decoder, während der Erzeugung jedes Wortes auf verschiedene Teile der Eingabesequenz zu schauen.
Seq2Seq mit Aufmerksamkeit berechnet Aufmerksamkeitswerte, um während des Dekodierens dynamisch auf verschiedene Teile der Eingabesequenz zu fokussieren.
Formel für Aufmerksamkeitsgewichte:
α_ij = exp(e_ij) / Σ_k exp(e_ik)Wo:
- αij: Aufmerksamkeitsgewicht für Abfrage i und Schlüssel j
- e_ij: Rohwert der Aufmerksamkeit zwischen Abfrage i und Schlüssel j
- exp: Exponentialfunktion
- Σ_k exp(e_ik): Summe der Exponentialwerte für alle Schlüssel k (Normalisierungsterm)
Diese Softmax-Operation stellt sicher, dass die Aufmerksamkeitsgewichte über alle Schlüssel hinweg 1 ergeben.
Warum Aufmerksamkeit für Seq2Seq-Modelle entscheidend ist
Die Hinzufügung des Aufmerksamkeitsmechanismus hat Seq2Seq robuster und skalierbarer gemacht. Hier ist, wie:
- Bessere Handhabung langer Sequenzen: Kontextvektoren könnten ohne Aufmerksamkeit Schwierigkeiten haben, alle relevanten Informationen zu bewahren. Dies kann zu schlechter Ausgabequalität bei langen Texten führen.
- Adaptiver Fokus: Aufmerksamkeit ermöglicht es dem Modell, den Fokus auf spezifische Eingabeelemente bei jedem Dekodierschritt anzupassen, was zu genaueren Übersetzungen oder Zusammenfassungen führt.
- Grundlage von Transformern: Aufmerksamkeit ist auch ein Kernkonzept in modernen Transformer-Architekturen wie BERT, GPT und T5, die auf Seq2Seq-Modellen aufbauen, um noch komplexere NLP-Aufgaben zu bewältigen.
4. Training des Seq2Seq-Modells
Das Training von Seq2Seq-Modellen erfordert einen großen Datensatz gepaarter Sequenzen (zum Beispiel Satzpaare in zwei Sprachen). Das Modell lernt, indem es seine Ausgabe mit der korrekten Produktion vergleicht und Anpassungen vornimmt, bis es die Fehler minimiert. Im Laufe der Zeit verbessert es sich bei der Transformation von Sequenzen.
Möchten Sie mehr über Software für die Verarbeitung natürlicher Sprache (NLP) erfahren? Erkunden Sie Natürliche Sprachverarbeitung (NLP) Produkte.
Wie man ein Seq2Seq-Modell in PyTorch implementiert
PyTorch ist ein beliebtes Deep-Learning-Framework zur Implementierung von Seq2Seq-Modellen, da es Flexibilität und Benutzerfreundlichkeit bietet.
Hier ist eine Schritt-für-Schritt-Anleitung zum Aufbau einer Encoder-Decoder-Architektur in PyTorch, die sequenzielle Daten verarbeitet und sinnvolle Ausgaben erzeugt.
Schritt 1: Bibliotheken importieren
Um das Modell zu definieren und zu trainieren, importieren Sie die erforderlichen Bibliotheken wie PyTorch, NumPy und andere Hilfsprogramme.

Quelle: ChatGPT
Schritt 2: Hyperparameter definieren
Legen Sie die Schlüsselparameter für das Modell fest, einschließlich Eingabegröße (Anzahl der Merkmale in der Eingabe), Ausgabegröße (Merkmale in der Ausgabe), versteckte Dimensionen (Größe der versteckten Schichten) und Lernrate (steuert die Trainingsgeschwindigkeit des Modells).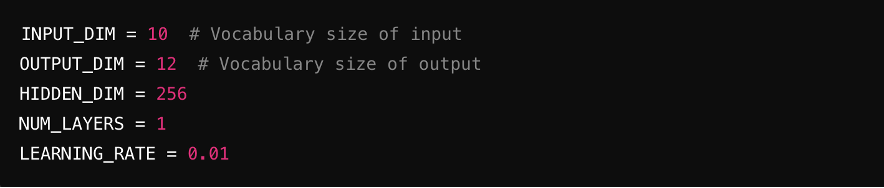
Quelle: ChatGPT
Schritt 3: Den Encoder definieren
Erstellen Sie den Encoder, typischerweise unter Verwendung eines RNN, LSTM oder GRU. Er verarbeitet den Eingabesatz Schritt für Schritt und fasst die Informationen in einem Kontextvektor zusammen, der in seinem versteckten Zustand gespeichert ist.
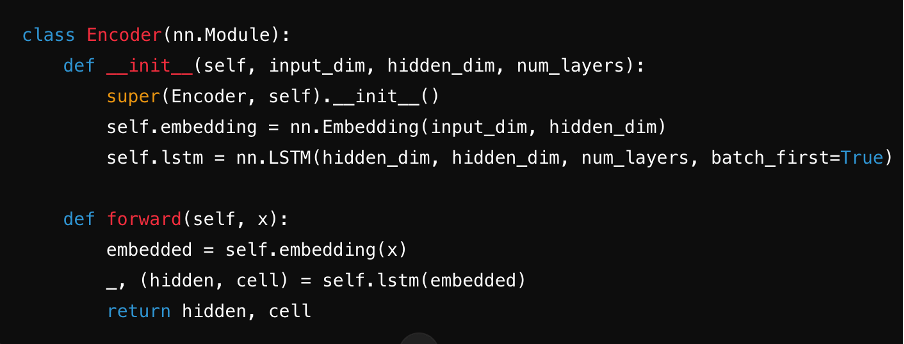
Quelle: ChatGPT
Schritt 4: Den Decoder definieren
Entwerfen Sie den Decoder, der die Ausgabesequenz erzeugt. Er verwendet den Kontextvektor des Encoders und seine versteckten Zustände, um jede Ausgabe Schritt für Schritt vorherzusagen.
Schritt 5: In ein Seq2Seq-Modell integrieren
Integrieren Sie den Encoder und Decoder in ein einziges Seq2Seq-Modell. Während dieses Schritts verwenden Sie oft lineare Schichten und Softmax-Funktionen, um Vorhersagen für jeden Zeitschritt der Zielsequenz zu erzeugen. Dies stellt einen nahtlosen Transfer des Kontextvektors, der Einbettungen und der versteckten Zustände zwischen den Komponenten sicher und optimiert die Effizienz des Modells.
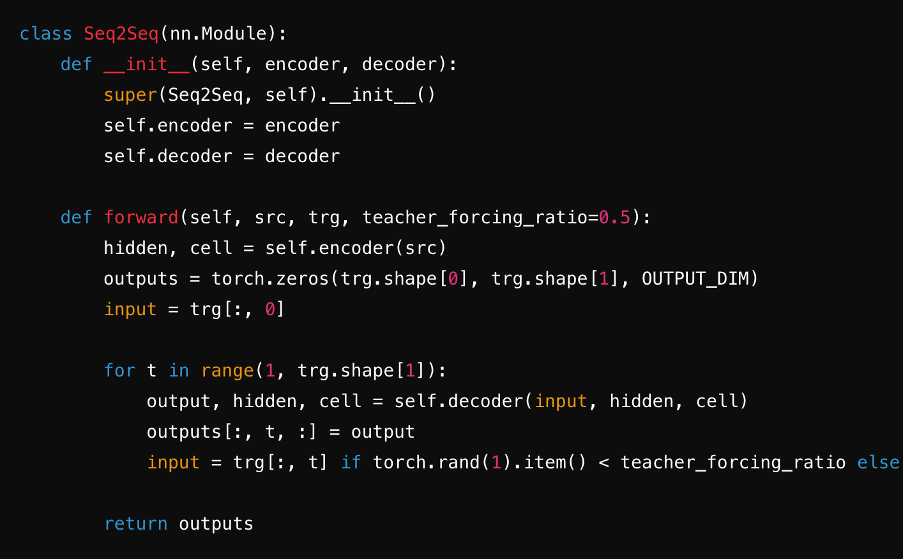
Quelle: ChatGPT
Schritt 6: Das Modell trainieren
Implementieren Sie eine Trainingsschleife, in der das Modell lernt, indem es seine Vorhersagen mit der Wahrheit vergleicht. Optimieren Sie die Parameter mit einer Verlustfunktion und einem Algorithmus wie Adam oder SGD. Durchlaufen Sie Epochen, aktualisieren Sie Gewichte, um den Verlust zu minimieren und die Leistung im Laufe der Zeit zu verbessern.

Quelle: ChatGPT
Wichtige Anwendungen von Seq2Seq-Modellen in der NLP
Seq2Seq ist ein führender Algorithmus des maschinellen Lernens für NLP aufgrund seiner Flexibilität und Genauigkeit bei der Bewältigung komplexer Sprachaufgaben. Durch den Einsatz von Sequence-to-Sequence-Lernen mit neuronalen Netzwerken zeichnen sich diese Modelle bei Anwendungen wie aus:
- Sprachübersetzung. Seq2Seq ist hervorragend darin, Text zwischen Sprachen zu übersetzen. Ihre Fähigkeit, grammatikalische Nuancen zu erfassen und die Flüssigkeit beizubehalten, macht sie ideal für die Unterstützung von Diensten wie Google Translate.
- Textzusammenfassung. Durch die Identifizierung und Verdichtung wesentlicher Informationen erstellen Seq2Seq-Modelle prägnante Zusammenfassungen von Artikeln, Berichten oder anderen langen Texten, ohne die Bedeutung zu verlieren.
- Konversationelle KI und Chatbots. Seq2Seq-Modelle erzeugen natürliche, kontextbewusste Antworten, was sie für Chatbots, virtuelle Assistenten und automatisierte Kundendienstsysteme unverzichtbar macht. Ihre Fähigkeit, kohärenten und menschenähnlichen Text zu erzeugen, ist auch für automatisierte E-Mail-Antworten oder die Erstellung von Geschichten von Vorteil.
- Anpassungsfähig für Daten variabler Länge. Die Encoder-Decoder-Struktur ermöglicht es Seq2Seq, Daten unterschiedlicher Länge zu verarbeiten, was sie für Aufgaben wie Fragebeantwortung oder Codegenerierung geeignet macht.
Vorteile von Seq2Seq-Modellen
Sequence-to-Sequence-Modelle bieten einzigartige Flexibilität und Präzision. Lassen Sie uns die wichtigsten Vorteile untersuchen, die Seq2Seq zu einem leistungsstarken Werkzeug machen.
- Vielseitigkeit: Seq2Seq-Modelle können vielfältige Aufgaben wie Sprachübersetzung, Zusammenfassung, Texterzeugung und mehr bewältigen. Ihre Encoder-Decoder-Architektur macht sie anpassungsfähig an verschiedene Herausforderungen mit sequenziellen Daten.
- Kontextbewahrung: Diese Modelle bewahren den Kontext von Eingabesequenzen, was sie besonders nützlich für Aufgaben macht, die lange Sätze oder Absätze betreffen, bei denen die Bedeutung von früheren Teilen der Sequenz abhängt.
- Genauigkeit: Da Seq2Seq-Modelle hoch skalierbar sind und auf großen Datensätzen trainiert werden können, verbessern sich ihre Genauigkeit und Zuverlässigkeit im Laufe der Zeit.
- Robustheit gegenüber rauschenden Daten: Durch die effektive Erfassung sequentieller Abhängigkeiten mindern Seq2Seq-Modelle Fehler, die durch rauschende oder unvollständige Daten entstehen.
Nachteile von Seq2Seq-Modellen
Das Verständnis der Einschränkungen von Seq2Seq-Modellen ist entscheidend, um zu bestimmen, wann und wie man sie effektiv implementiert. Lassen Sie uns einige der potenziellen Nachteile erkunden.
- Hohe Rechenanforderungen: Die Implementierung von Seq2Seq-Modellen auf ressourcenarmen Geräten ist schwierig, da sie viel Speicher und Rechenkapazität erfordern, insbesondere in Kombination mit Aufmerksamkeitsmechanismen.
- Schwierigkeit bei der Handhabung sehr langer Sequenzen: Selbst mit Funktionen wie Aufmerksamkeit können Seq2Seq-Modelle Schwierigkeiten haben, lange Eingabesequenzen zu verarbeiten. Dies kann zu Kontextverlust oder schlechter Leistung bei Aufgaben mit mehreren Abhängigkeiten führen.
- Abhängigkeit von umfangreichen Trainingsdaten: Um Seq2Seq-Modelle effektiv zu trainieren, sind große, qualitativ hochwertige Datensätze erforderlich. In Abwesenheit zuverlässiger Daten oder bei unzureichenden Daten können schlechte Ausgabequalität und unzuverlässige Ergebnisse erzielt werden.
- Risiko der Expositionsverzerrung: Seq2Seq-Modelle werden während des Trainings von den richtigen Antworten (lehrerforcierte Daten) geleitet. Bei der tatsächlichen Nutzung muss sich das Modell jedoch auf seine Vorhersagen verlassen. Wenn es frühzeitig einen Fehler macht, können sich die Fehler summieren und die endgültige Ausgabe beeinflussen.
Die Zukunft von Seq2Seq-Modellen in Sprache und KI
Seq2Seq-Modelle haben eine vielversprechende Zukunft in Sprache und KI, insbesondere als grundlegende Elemente für moderne Sprachmodelle wie GPT und BERT.
Mit Fortschritten in Einbettungstechniken, adaptivem Training mit Gradientenoptimierung und neuronaler maschineller Übersetzung ist Seq2Seq bereit, noch komplexere NLP-Herausforderungen zu bewältigen.
- Erweiterung der Anwendungen: Seq2Seq wird sich wahrscheinlich auf mehr Bereiche ausdehnen, wie z.B. automatisierten Kundendienst, kreatives Schreiben und fortschrittliche Chatbots, um Interaktionen reibungsloser und intuitiver zu gestalten.
- Bessere Handhabung komplexer Kontexte: Verbesserte Aufmerksamkeitsmechanismen und transformerbasierte Innovationen helfen Seq2Seq-Modellen, tiefere Sprachnuancen zu verstehen.
- Anpassungsfähigkeit an ressourcenarme Sprachen: Mit mehr Forschung könnten Seq2Seq-Modelle in der Lage sein, ein breiteres Spektrum an Sprachen zu unterstützen, einschließlich solcher mit weniger Trainingsdaten.
- Integration mit fortschrittlicher KI: Seq2Seq ist grundlegend für neuere Modelle wie GPT und BERT, die weiterhin die Grenzen der Verarbeitung natürlicher Sprache verschieben werden.
Neue Horizonte mit Seq2Seq-Modellen erschließen
Seq2Seq-Modelle haben revolutioniert, wie wir Sprache in der KI verarbeiten und verstehen, und bieten unvergleichliche Vielseitigkeit und Präzision. Vom nahtlosen Übersetzen von Sprachen bis hin zur Erzeugung menschenähnlicher Texte sind sie das Rückgrat moderner NLP-Anwendungen.
Da sich Fortschritte wie Aufmerksamkeitsmechanismen und Transformer weiterentwickeln, werden Seq2Seq-Modelle nur noch leistungsfähiger und effizienter, um zunehmend komplexe Herausforderungen in Sprache und neuronalen Netzwerken zu bewältigen. Ob ML-Enthusiast oder erfahrener Praktiker, die Erkundung von Seq2Seq öffnet die Tür zur Schaffung innovativerer, kontextbewusster Lösungen.
Die Zukunft der KI ist sequenziell – sind Sie bereit, in sie einzutreten?
Entdecken Sie die besten LLM-Lösungen zum Aufbau und zur Skalierung Ihrer maschinellen Lernmodelle.

Chayanika Sen
Chayanika is a B2B Tech and SaaS content writer. She specializes in writing data-driven and actionable content in the form of articles, guides, and case studies. She's also a trained classical dancer and a passionate traveler.

