La tecnologia sta avanzando a un ritmo rapido e, sebbene a volte possa sembrare travolgente, sta rendendo i nostri compiti quotidiani più facili.
Dal ordinare il nostro caffè mattutino con un comando vocale al trovare il percorso più veloce per l'ufficio, queste comodità sono diventate una seconda natura. Ma cosa succederebbe se i tuoi dispositivi potessero comprendere e interagire con il mondo intorno a noi nello stesso modo in cui potrebbe farlo un essere umano?
Con la potenza dell'intelligenza artificiale (IA) e della tecnologia di visione artificiale, ora possiamo.
Cos'è You Only Look Once (YOLO)?
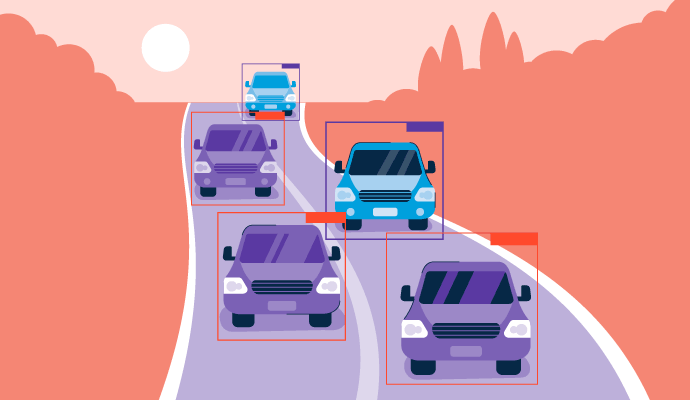
You Only Look Once, o YOLO, è un algoritmo di rilevamento degli oggetti in tempo reale sviluppato per la prima volta nel 2015. Prevede la probabilità che un oggetto sia presente all'interno di un'immagine o di un video. È un algoritmo specifico che migliora il campo attuale del rilevamento degli oggetti nella tecnologia di visione artificiale, dove gli oggetti nelle immagini sono localizzati e identificati.
YOLO ha bisogno di esaminare il visivo solo una volta per fare queste previsioni, da cui il suo nome, e può anche essere chiamato rilevamento degli oggetti a colpo singolo (SSD). È una parte importante del processo di rilevamento degli oggetti che molti software di riconoscimento delle immagini utilizzano per comprendere cosa sta rappresentando il media visivo.
Utilizzando reti neurali end-to-end, questo algoritmo può prevedere sia la posizione (scatole di delimitazione) che l'identità (classificazione) degli oggetti in un'immagine simultaneamente. Questo è stato un salto rispetto agli algoritmi tradizionali di rilevamento degli oggetti, che riutilizzavano classificatori esistenti per prevedere queste informazioni.
Come funziona You Only Look Once
YOLO si basa su una singola rete neurale convoluzionale (CNN), un componente chiave del deep learning e un tipo di rete AI che filtra gli input del modello per cercare schemi riconoscibili. Gli strati in queste reti sono formattati per rilevare prima i modelli più semplici, prima di passare a quelli più complessi.
Sebbene le CNN siano utilizzate per più del semplice elaborazione delle immagini, sono una parte fondamentale dell'architettura YOLO. Quando un'immagine viene inserita in un modello basato su YOLO, passa attraverso diversi passaggi per rilevare gli oggetti all'interno di quel visivo. Ecco una suddivisione:
- Immagine di input: L'intera immagine, sia essa una foto statica, un grafico o un formato video, viene passata attraverso il modello. Le caratteristiche dell'immagine vengono estratte e passate attraverso strati connessi per prevedere le classificazioni e le coordinate delle scatole di delimitazione.
- Divisione a griglia: L'immagine di input viene quindi divisa in caselle in una formazione a griglia. Ogni piccolo quadrato o cella della griglia è incaricato di rilevare oggetti all'interno della sua sezione, oltre a fornire un valore di probabilità o fiducia per qualsiasi oggetto rilevato.
- Rilevamento degli oggetti: Se una griglia è prevista per contenere un oggetto, verrà evidenziata come celle significative. Il modello determina quindi il tipo di oggetto e la sua posizione all'interno della griglia in un unico passaggio.
- Valutazione delle scatole di delimitazione: Il modello disegna scatole attorno agli oggetti rilevati, note come scatole di delimitazione. Ogni cella della griglia può generare più scatole di delimitazione se c'è più di un oggetto in quella cella. Le scatole di delimitazione possono anche sovrapporsi alle celle per comprendere completamente ogni oggetto nell'intera immagine. A ogni scatola di delimitazione viene assegnato un punteggio di fiducia che rappresenta quanto è probabile che la previsione sia corretta.
- Output: Dopo che i quadrati della griglia sono stati valutati, l'output finale elencherà tutti gli oggetti all'interno dell'immagine, insieme a ciascuna scatola di delimitazione e alla sua etichetta. Come parte del post-elaborazione, avrà luogo la soppressione non massima (NMS) per rimuovere le scatole sovrapposte, garantendo che ogni oggetto sia rappresentato da una sola scatola con il punteggio di fiducia più alto. Questo passaggio migliora l'accuratezza del rilevamento degli oggetti e rende l'intero processo più efficiente filtrando il rumore aggiuntivo per creare un output più pulito.
Vuoi saperne di più su Software di Riconoscimento Immagini? Esplora i prodotti Riconoscimento delle immagini.
Tipi di YOLO nel rilevamento degli oggetti
Dalla sua creazione, YOLO ha attraversato diverse iterazioni che hanno integrato tecnologia aggiornata e hanno creato un flusso di lavoro più veloce ed efficiente. Ecco una breve panoramica di YOLO v1-v6 e uno sguardo a dove siamo oggi:
- YOLOv1: L'algoritmo originale era focalizzato principalmente sul rilevamento degli oggetti come un problema di regressione piuttosto che sugli approcci di classificazione tradizionali, il che era rivoluzionario all'epoca. Questa base è ancora utilizzata nei modelli YOLO oggi.
- YOLOv2: Conosciuto anche come YOLO 9000, questa versione ha costruito sui concetti originali di YOLO e ha affrontato alcune delle limitazioni del primo modello. Sono state introdotte le scatole di ancoraggio come scatole pre-determinate all'interno della griglia, con rapporti di aspetto e scale unici. Questo ha reso più facile prevedere le scatole di delimitazione e si adattava meglio agli oggetti reali nell'immagine. La versione includeva anche aggiornamenti per gestire immagini ad alta risoluzione senza rallentare i tempi di elaborazione.
- YOLOv3: Questa versione ha introdotto una tecnica nota come "rete piramidale di caratteristiche" (FPN), che è stata utilizzata per rilevare oggetti di dimensioni diverse all'interno dell'immagine. La velocità di elaborazione è stata anche aumentata nella terza versione di YOLO attraverso l'uso di Darknet-53.
- YOLOv4: Con una versione aggiornata di Darknet, CSPDarnet, la quarta versione di YOLO era significativamente più veloce e più accurata delle iterazioni precedenti. L'accuratezza è migliorata di circa lo 0,5% in media grazie all'introduzione di una tecnica nota come "connessione parziale incrociata" o CSP, dove più modelli sono stati introdotti contemporaneamente per combinare le loro capacità di previsione.
- YOLOv5: Introdotto nel 2020, la quinta versione di YOLO ha introdotto un'architettura di rete neurale aggiornata chiamata EfficientDet. EfficientDet era una serie di modelli di classificazione delle immagini progettati per migliorare l'accuratezza computazionale e l'uso della memoria pur raggiungendo i più alti livelli di accuratezza dell'output. Le scatole di ancoraggio non erano più necessarie con la versione 5, con un singolo strato convoluzionale in grado di prevedere direttamente le scatole di delimitazione degli oggetti, indipendentemente dalla loro forma o dimensione.
- YOLOv6: L'introduzione di una nuova rete neurale più leggera ha significato che la versione 6 di YOLO funzionava in modo più efficiente e con meno risorse necessarie. Durante l'addestramento è stata anche introdotta l'augmentazione dei dati, che consente al modello di riconoscere ancora gli oggetti quando sono capovolti, ruotati o scalati nell'immagine di input.
Gli aggiornamenti più recenti a YOLO, versioni dalla 7 alla 9, hanno continuato a vedere miglioramenti in termini di velocità e accuratezza mentre l'algoritmo viene adattato in base alle attuali scoperte nel deep learning. La capacità di apprendimento dell'algoritmo è aumentata significativamente con questi modelli più recenti, consentendo il rilevamento degli oggetti anche con dati di immagine sfocati o incompleti.
Industrie che utilizzano You Only Look Once
Ci sono numerosi modi in cui YOLO può essere implementato nella vita quotidiana, ma alcune industrie traggono più vantaggio da questa tecnologia rispetto ad altre.
Sicurezza
I sistemi di sorveglianza diventano più complessi ogni anno, aiutandoci a rimanere al sicuro ovunque ci troviamo. YOLO è spesso utilizzato per rilevare individui monitorati dalle forze dell'ordine attraverso sistemi di telecamere a circuito chiuso e di sicurezza, monitorando anche crimini come taccheggio o aggressioni in tempo reale.
Sanità
Come altre forme di rilevamento degli oggetti e riconoscimento delle immagini, YOLO può essere utilizzato nella cura medica in tempo reale e nel trattamento delle immagini. Diversi studi hanno trovato un uso diffuso di YOLO in tutto questo settore, comprese le procedure chirurgiche in cui è necessario il rilevamento degli organi a causa della diversità biologica dei diversi pazienti.
Sia le scansioni 2D che 3D possono rapidamente e accuratamente individuare la posizione degli organi, fornendo informazioni su potenziali problemi che l'imaging medico è utilizzato per rilevare.
Agricoltura
Lo sviluppo dell'IA ha aiutato significativamente l'industria agricola, permettendo agli agricoltori di monitorare i loro raccolti in ogni momento senza la necessità di supervisione manuale. YOLO e la robotica agricola hanno sostituito la raccolta e la mietitura manuale in molti casi. È anche utilizzato per identificare quando i raccolti sono al loro massimo grado di maturazione per la raccolta in base alle caratteristiche di colore o dimensione degli oggetti (raccolti) nelle immagini.
Veicoli autonomi
Per le auto a guida autonoma, YOLO aiuta a identificare segnali stradali, pedoni e altri pericoli stradali con velocità e precisione, proprio come farebbe un guidatore umano.
Vantaggi di YOLO
Ci sono numerosi vantaggi che derivano dall'utilizzo di algoritmi come YOLO nei modelli di IA per il rilevamento degli oggetti, in particolare in termini di velocità e accuratezza.
- Applicazioni in tempo reale: Per le industrie dove la gestione del tempo e la reattività rapida sono essenziali, come le auto a guida autonoma e la sicurezza, YOLO è una delle migliori opzioni automatizzate per rilevare oggetti in un'immagine o video.
- Alti livelli di accuratezza: Con ogni nuova versione di YOLO, l'algoritmo diventa più accurato nel rilevamento degli oggetti con fiducia nei box di delimitazione dell'output. Sia le classificazioni che le posizioni degli oggetti nelle immagini sono più accurate ogni volta.
- Efficienza a colpo singolo: Invece di aspettare che le immagini passino attraverso diversi strati di una rete neurale, YOLO può elaborare le informazioni in un unico passaggio per migliorare la sua efficienza e velocità complessive.
- Capacità di valutare immagini di diverse scale: YOLO è ora in grado di elaborare immagini con diversi rapporti di aspetto e determinare oggetti di dimensioni diverse all'interno di modelli che utilizzano scatole di ancoraggio così come quelli senza.
Principali strumenti di riconoscimento delle immagini utilizzati per You Only Look Once
YOLO può essere utilizzato solo per un ruolo specifico nel riconoscimento delle immagini, il rilevamento degli oggetti, ma questi strumenti possono essere aggiunti ai flussi di lavoro per completare molti altri compiti. Il rilevamento degli oggetti è solo una parte di come le immagini sono elaborate utilizzando l'IA, con aspetti come il restauro delle immagini e la ricostruzione della scena anche possibili con questo software.
Per essere inclusi nella categoria del riconoscimento delle immagini, le piattaforme devono:
- Fornire un algoritmo di deep learning specificamente per il riconoscimento delle immagini
- Connettersi con pool di dati di immagini per apprendere una soluzione o funzione specifica
- Consumare i dati delle immagini come input e fornire un output
- Fornire capacità di riconoscimento delle immagini ad altre applicazioni, processi o servizi
* Di seguito sono riportate le cinque principali soluzioni di software di riconoscimento delle immagini dal Grid Report di G2 dell'estate 2024. Alcune recensioni possono essere modificate per chiarezza.
1. Google Cloud Vision API
Google Cloud Vision API è in grado di rilevare e classificare più oggetti all'interno delle immagini utilizzando un algoritmo pre-addestrato che può essere adattato ai propri modelli. Questo software aiuta gli sviluppatori a utilizzare la potenza del machine learning con un'accuratezza di previsione leader nel settore.
Cosa piace di più agli utenti:
“La cosa più utile che ho sperimentato riguardo a questo particolare strumento Vision API di Google è la sua integrazione delle funzionalità di rilevamento nei nostri progetti di Deep e Machine learning. La sua API ci sta aiutando a rilevare qualsiasi oggetto e a etichettarlo con comprensione umana e a formare un modello di machine learning.”
- Recensione di Google Cloud Vision API, Kunal D.
Cosa non piace agli utenti:
“Per le immagini di bassa qualità, a volte dà la risposta sbagliata poiché alcuni cibi hanno lo stesso colore. Non ci fornisce l'opzione di personalizzare o addestrare il modello per il nostro caso d'uso specifico. La parte di configurazione è complessa.”
- Recensione di Google Cloud Vision API, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit è una libreria di machine learning open source e multipiattaforma. Attrae sviluppatori e ingegneri AI per le sue opzioni di riconoscimento dei gesti e delle immagini in tempo reale che si integrano nei loro algoritmi e modelli.
Cosa piace di più agli utenti:
“Il suo ampio set di algoritmi e l'interfaccia facile da usare lo rendono adatto sia per i principianti che per gli utenti avanzati.”
- Recensione di Gesture Recognition Toolkit, Ram M.
Cosa non piace agli utenti:
“Gesture Recognition Toolkit ha occasionali ritardi e un processo di implementazione meno fluido. I tempi di risposta del supporto clienti potrebbero essere più rapidi.”
- Recensione di Gesture Recognition Toolkit, Civic V.
3. SuperAnnotate
SuperAnnotate è una piattaforma per costruire, perfezionare e gestire i tuoi modelli AI con i dati di addestramento di altissima qualità e leader nel settore. La tecnologia avanzata di annotazione e gli strumenti di garanzia della qualità ti consentono di costruire modelli di machine learning di successo e dataset di alto livello.
Cosa piace di più agli utenti:
“Stavo cercando uno strumento per annotare immagini biologiche. Dopo aver provato molti strumenti, ho trovato due delle migliori piattaforme per me. Una di queste è Superannotate. Queste piattaforme avevano il set più ampio di strumenti di annotazione, inclusi esattamente quelli di cui avevo bisogno. Gli strumenti sono comodi da usare.”
- Recensione di SuperAnnotate, Artem M.
Cosa non piace agli utenti:
“Abbiamo avuto alcuni problemi con flussi di lavoro personalizzati che il team ha implementato per progetti specifici sulla loro piattaforma. Per alcuni flussi di lavoro personalizzati, abbiamo notato che lo strumento di analisi riportava erroneamente il tempo impiegato per l'annotazione.”
- Recensione di SuperAnnotate, Rohan K.
4. Syte
Syte è la prima piattaforma di scoperta di prodotti al mondo alimentata dall'IA che aiuta sia i consumatori che i rivenditori a connettersi con i prodotti. La ricerca tramite fotocamera, la personalizzazione e gli strumenti in-store come il riconoscimento delle immagini offrono un'esperienza istantanea e intuitiva per gli acquirenti.
Cosa piace di più agli utenti:
“Il team offre costantemente preziose intuizioni e alternative per migliorare la funzionalità e l'efficacia dello strumento Shop Similar. Lavorare con Syte facilita il raggiungimento dei KPI specifici del nostro sito.”
- Recensione di Syte, Gabriella M.
Cosa non piace agli utenti:
“C'è stata qualche difficoltà nell'abilitare diversi account alla dashboard di analisi. Sarebbe bello non avere restrizioni su questi accessi (utenti diversi dovrebbero poter accedervi).”
- Recensione di Syte, Antonio R.
5. Dataloop
Dataloop è una piattaforma di sviluppo AI che consente alle aziende di costruire facilmente le proprie applicazioni AI con dataset intuitivi. Gli strumenti all'interno del software consentono ai team di ottimizzare l'annotazione delle immagini, la selezione dei modelli e le distribuzioni dei modelli per un'applicazione su larga scala.
Cosa piace di più agli utenti:
“Dataloop ha anche un gran numero di funzionalità che lo rendono conveniente per molti utenti di diversi progetti. Dopo ogni aggiornamento vengono fornite istruzioni che spiegano le modifiche, rendendo facile implementarle.”
- Recensione di Dataloop, Mzamil J.
Cosa non piace agli utenti:
“Ho avuto difficoltà con alcune curve di apprendimento ripide, dipendenza dall'infrastruttura e limitazioni di personalizzazione. Questi hanno in qualche modo limitato il mio utilizzo.”
- Recensione di Dataloop, Dennis R.

Inizia a lavorare con l'IA perché YOLO!
In meno di un decennio, YOLO ha fatto progressi significativi ed è diventato il metodo di riferimento per il rilevamento degli oggetti per molte industrie. Grazie al suo approccio efficiente e accurato al riconoscimento delle immagini, è ideale per le esigenze in tempo reale mentre esplori il mondo dell'IA.
Scopri di più su reti neurali artificiali e su come i modelli sono progettati per imitare il cervello umano.
Modificato da Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.

