

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
Se sei una persona come me, ti piace la struttura, l'ordine e la semplicità.
Ma in alcuni casi, è meglio fare un passo indietro e permettere che si sviluppi un caos organizzato. Questa è la base di qualcosa chiamato data lake.
Cos'è un data lake?
Definizione di data lake
Un data lake è un deposito per dati strutturati, non strutturati e semi-strutturati. I data lake sono molto diversi dai data warehouse poiché permettono ai dati di essere nella loro forma più grezza senza bisogno di essere convertiti e analizzati prima.
In termini più semplici, tutti i tipi di dati generati sia dagli esseri umani che dalle macchine possono essere caricati in un data lake per essere classificati e analizzati in seguito.
I data warehouse, d'altra parte, richiedono che i dati siano correttamente strutturati prima che si possa fare qualsiasi lavoro.
Per ottenere una comprensione più profonda dei data lake e del perché siano la scelta ottimale per ospitare big data, è importante approfondire ciò che li rende così diversi dai data warehouse.
Vuoi saperne di più su Soluzioni di Data Warehouse? Esplora i prodotti Data Warehouse.
Data lake vs. data warehouse
Sia i data lake che i data warehouse sono depositi per dati. Questa è circa l'unica somiglianza tra i due. Ora, tocchiamo alcune delle differenze chiave:
- I data lake sono progettati per supportare tutti i tipi di dati, mentre i data warehouse utilizzano dati altamente strutturati – nella maggior parte dei casi.
- I data lake memorizzano tutti i dati che potrebbero o meno essere analizzati in futuro. Questo principio non si applica ai data warehouse poiché i dati irrilevanti vengono tipicamente eliminati a causa dello spazio di archiviazione limitato.
- La scala tra data lake e data warehouse è drasticamente diversa a causa dei nostri punti precedenti. Supportare tutti i tipi di dati e memorizzare quei dati (anche se non sono immediatamente utili) significa che i data lake devono essere altamente scalabili.
- Grazie ai metadati (dati sui dati), gli utenti che lavorano con un data lake possono ottenere rapidamente una visione di base sui dati. Nei data warehouse, spesso è necessario un membro del team di sviluppo per accedere ai dati – il che potrebbe creare un collo di bottiglia.
- Infine, la gestione intensiva dei dati richiesta per i data warehouse significa che sono tipicamente più costosi da mantenere rispetto ai data lake.
James Dixon, fondatore e Chief Technology Officer di Pentaho, ha coniato il termine "data lake" dopo aver fornito un'analogia che differenzia i data lake dai data warehouse.
“Se pensi a un datamart come a un negozio di acqua in bottiglia – purificata e confezionata e strutturata per un facile consumo – il data lake è un grande corpo d'acqua in uno stato più naturale,” ha detto Dixon. “I contenuti del data lake fluiscono da una fonte per riempire il lago, e vari utenti del lago possono venire a esaminare, immergersi o prendere campioni.”
James Dixon
fondatore e Chief Technology Officer di Pentaho
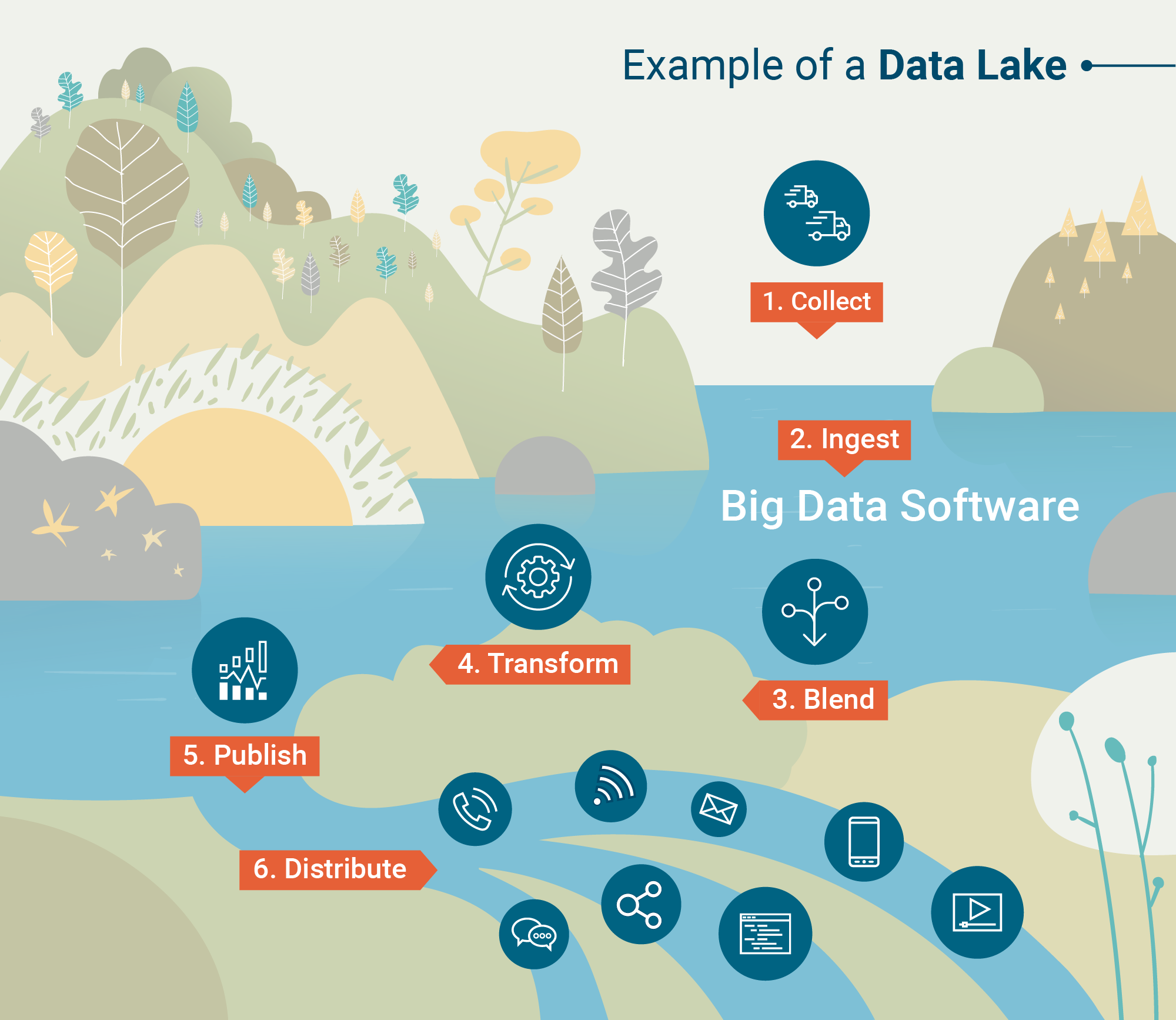
Architettura del data lake
Quindi, come fanno i data lake a essere in grado di memorizzare quantità così vaste e diverse di dati? Qual è l'architettura sottostante di questi enormi depositi?
I data lake sono costruiti su un modello di dati schema-on-read. Uno schema è essenzialmente lo scheletro di un database che ne delinea il modello e come i dati saranno strutturati al suo interno. Pensalo come un progetto.
Il modello di dati schema-on-read significa che puoi caricare i tuoi dati nel lago così come sono senza doverti preoccupare della loro struttura. Questo permette molta più flessibilità.
I data warehouse, d'altra parte, sono composti da modelli di dati schema-on-write. Questo è un modello molto più tradizionale per i database.
Ogni set di dati, ogni relazione e ogni indice nel modello di dati schema-on-write deve essere chiaramente definito in anticipo. Questo limita la flessibilità, specialmente quando si aggiungono nuovi set di dati o funzionalità che potrebbero potenzialmente creare lacune all'interno del database.
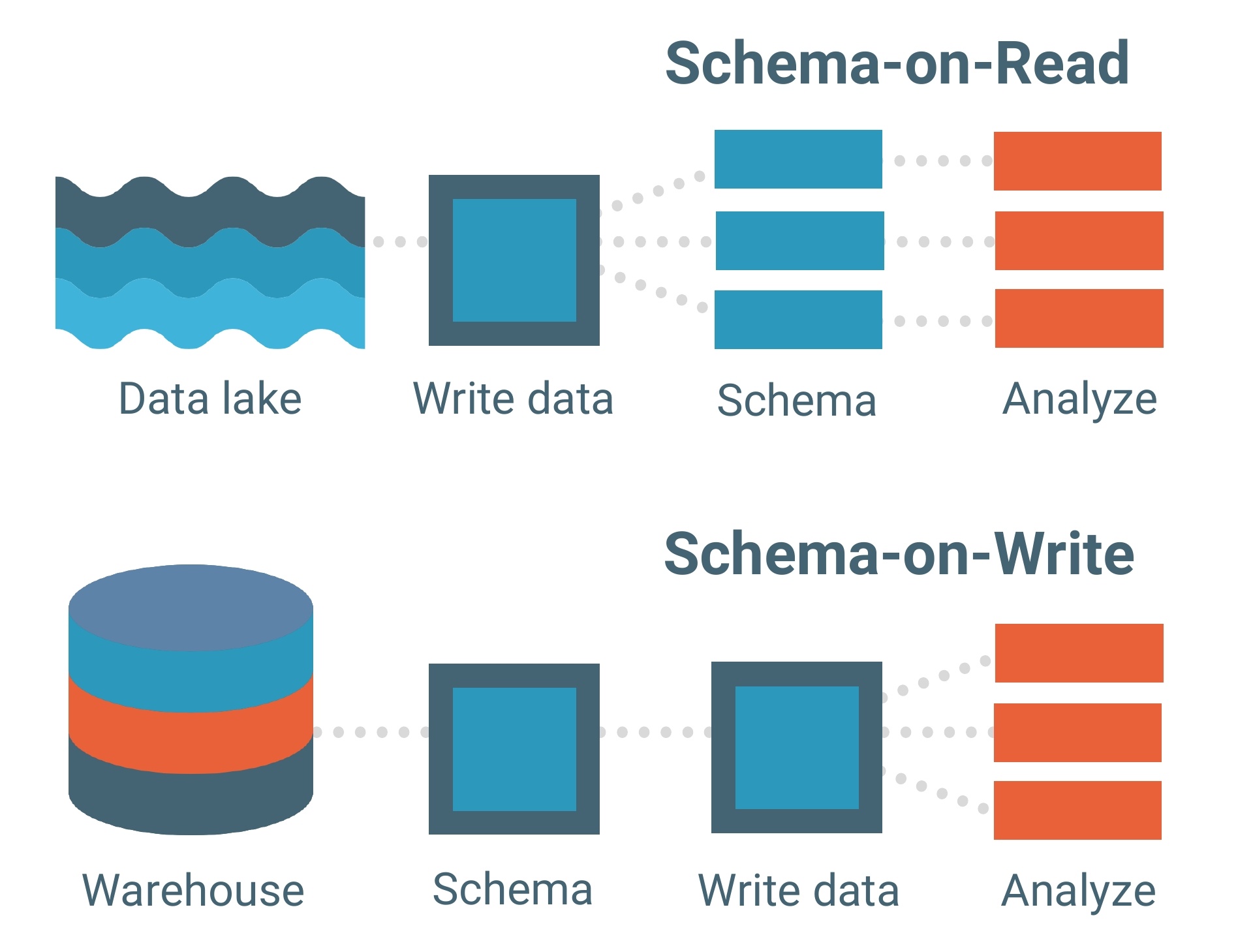
Il modello di dati schema-on-read funge da spina dorsale di un data lake, ma il framework di elaborazione (o motore) è come i dati vengono effettivamente caricati in uno.
Di seguito sono riportati i due framework di elaborazione che "ingeriscono" i dati nei data lake:
- Elaborazione batch – Milioni di blocchi di dati elaborati in lunghi periodi di tempo (da ore a giorni). Il metodo meno sensibile al tempo per l'elaborazione dei big data.
- Elaborazione in streaming – Piccoli lotti di dati elaborati in tempo reale. L'elaborazione in streaming sta diventando sempre più preziosa per le aziende che sfruttano l'analisi in tempo reale.

Hadoop, Apache Spark e Apache Storm sono tra gli strumenti di elaborazione dei big data più comunemente usati che sono in grado di elaborare sia in batch che in streaming.
Alcuni strumenti sono particolarmente utili per l'elaborazione di dati non strutturati come l'attività dei sensori, le immagini, i post sui social media e l'attività di clickstream su Internet. Altri strumenti danno priorità alla velocità di elaborazione e all'utilità con i programmi di apprendimento automatico.
Una volta che i dati sono stati elaborati e ingeriti nel data lake, è il momento di farne uso.
A cosa servono i data lake?
I data warehouse si basano sulla struttura e sui dati puliti, mentre i data lake permettono ai dati di essere nella loro forma più naturale. Questo perché strumenti analitici avanzati e software di mining prendono dati grezzi e li trasformano in informazioni utili.
Analisi dei big data
L'analisi dei big data esplorerà un data lake nel tentativo di scoprire modelli, tendenze di mercato e preferenze dei clienti per aiutare le aziende a fare previsioni informate più velocemente. Questo viene fatto attraverso quattro diverse analisi.
- Analisi descrittiva – Un'analisi retrospettiva che esamina "dove" potrebbe essersi verificato un problema per un'azienda. La maggior parte delle analisi dei dati oggi sono effettivamente descrittive perché possono essere generate rapidamente.
- Analisi diagnostica – Un'altra analisi retrospettiva che esamina "perché" un problema specifico potrebbe essersi verificato per un'azienda. Questa è leggermente più approfondita rispetto all'analisi descrittiva.
- Analisi predittiva – Quando vengono applicati software di intelligenza artificiale e apprendimento automatico, questa analisi può fornire a un'organizzazione modelli predittivi di ciò che potrebbe accadere in seguito. A causa della complessità della generazione di analisi predittive, non è ancora ampiamente adottata.
- Analisi prescrittiva – Il futuro dell'analisi dei big data è rappresentato dalle analisi prescrittive che non solo assistono negli sforzi decisionali, ma potrebbero persino essere in grado di fornire a un'organizzazione un insieme di risposte. C'è un livello molto alto di utilizzo dell'apprendimento automatico con queste analisi.
Data mining
Il data mining è definito come "scoperta della conoscenza nei database", ed è il modo in cui i data scientist scoprono modelli e verità precedentemente non visti attraverso vari modelli.
Ad esempio, un'analisi di clustering è un tipo di tecnica di data mining che può essere applicata a un set all'interno di un data lake. Questo raggrupperà grandi quantità di dati in base alle loro somiglianze.
Attraverso strumenti di visualizzazione dei dati, il data mining aiuta a chiarire la natura caotica dei dati non strutturati e grezzi.
Le sfide dei data lake
I data lake possono essere flessibili, scalabili e veloci da caricare, ma ciò comporta un prezzo.
L'ingestione di dati non strutturati richiede una mancanza di governance dei dati e processi che garantiscano che i dati giusti vengano esaminati. Per la maggior parte delle aziende – specialmente quelle che non hanno ancora adottato i big data – avere dati non organizzati e non puliti non è un'opzione.
L'uso improprio dei metadati o dei processi per mantenere il data lake sotto controllo può effettivamente portare a qualcosa chiamato data swamp. Non andresti a nuotare in una palude, vero?
C'è anche il problema della sicurezza dei dati.
I data lake sono un concetto abbastanza nuovo nell'IT, il che significa che alcuni degli strumenti stanno ancora risolvendo i problemi di sicurezza. Uno di questi problemi è garantire che solo le persone giuste abbiano accesso ai dati sensibili caricati nel lago.
Ma come qualsiasi nuova tecnologia, questi problemi si risolveranno con il tempo.
| CONSIGLIO: Pronto a fare un'immersione più profonda nel mondo dei dati? Impara le basi della gestione dei dati master (MDM) e perché è importante per le aziende. |
Il ruolo dei data lake con i big data
Nonostante alcune delle sfide dei data lake, il fatto rimane che oltre l'80% di tutti i dati è non strutturato. Man mano che più aziende si rivolgono ai big data per opportunità future, l'applicazione dei data lake aumenterà.
Dati non strutturati come i post sui social media, le registrazioni delle chiamate telefoniche e l'attività di clickstream contengono informazioni preziose che non possono essere trattenute nei data warehouse.
Mentre i data warehouse sono forti nella struttura e nella sicurezza, i big data semplicemente devono essere non confinati in modo che possano fluire liberamente nei data lake.
Consulta la nostra guida completa su dati strutturati vs non strutturati per una spiegazione più approfondita o leggi sull'importanza dell'ingegneria dei big data.