La technologie progresse à un rythme rapide, et bien que cela puisse parfois sembler accablant, elle rend nos tâches quotidiennes plus faciles.
De la commande de notre café du matin par commande vocale à la recherche de l'itinéraire le plus rapide pour se rendre au bureau, ces commodités sont devenues une seconde nature. Mais que se passerait-il si vos appareils pouvaient comprendre et interagir avec le monde qui nous entoure de la même manière qu'un humain ?
Avec la puissance de l'intelligence artificielle (IA) et de la technologie de vision par ordinateur, nous le pouvons maintenant.
Qu'est-ce que "you only look once" (YOLO) ?
"You only look once", ou YOLO, est un algorithme de détection d'objets en temps réel développé pour la première fois en 2015. Il prédit la probabilité qu'un objet soit présent dans une image ou une vidéo. C'est un algorithme spécifique qui améliore le domaine actuel de la détection d'objets dans la technologie de vision par ordinateur, où les objets dans les images sont localisés et identifiés.
YOLO n'a besoin de revoir le visuel qu'une seule fois pour faire ces prédictions, d'où son nom, et peut également être appelé détection d'objets en un seul coup (SSD). C'est une partie importante du processus de détection d'objets que de nombreux produits de logiciels de reconnaissance d'images utilisent pour comprendre ce que les médias visuels représentent.
En utilisant des réseaux neuronaux de bout en bout, cet algorithme peut prédire à la fois l'emplacement (boîtes englobantes) et l'identité (classification) des objets dans une image simultanément. Cela a été un saut par rapport aux algorithmes traditionnels de détection d'objets, qui réutilisaient des classificateurs existants pour prédire cette information.
Comment fonctionne "You Only Look Once"
YOLO repose sur un réseau neuronal convolutif (CNN) unique, un composant clé de l'apprentissage profond et un type de réseau IA qui filtre les entrées du modèle pour rechercher des motifs reconnaissables. Les couches de ces réseaux sont formatées pour détecter d'abord les motifs les plus simples, avant de passer à des motifs plus complexes.
Bien que les CNN soient utilisés pour plus que le traitement d'images, ils sont une partie fondamentale de l'architecture YOLO. Lorsqu'une image est entrée dans un modèle basé sur YOLO, elle passe par plusieurs étapes pour détecter les objets dans ce visuel. Voici un aperçu :
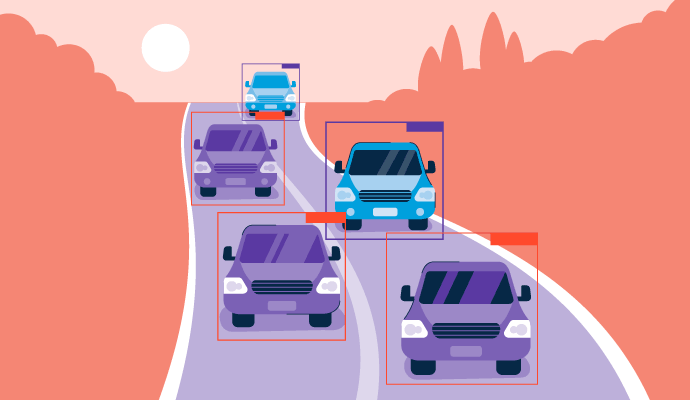
- Image d'entrée : L'image entière, qu'il s'agisse d'une photo statique, d'un graphique ou d'un format vidéo, est passée à travers le modèle. Les caractéristiques de l'image sont extraites et passées à travers des couches connectées pour prédire les classifications et les coordonnées des boîtes englobantes.
- Division en grille : L'image d'entrée est ensuite divisée en boîtes dans une formation de grille. Chaque petit carré ou cellule de la grille est chargé de détecter les objets dans sa section, tout en fournissant une valeur de probabilité ou de confiance pour tout objet détecté.
- Détection d'objets : Si une grille est prédite pour contenir un objet, elle sera mise en évidence comme des cellules significatives. Le modèle détermine ensuite le type d'objet et son emplacement dans la grille en un seul passage.
- Évaluation des boîtes englobantes : Le modèle dessine des boîtes autour des objets détectés, connues sous le nom de boîtes englobantes. Chaque cellule de la grille peut générer plusieurs boîtes englobantes s'il y a plus d'un objet dans cette cellule. Les boîtes englobantes peuvent également chevaucher les cellules pour englober complètement chaque objet dans l'image entière. Un score de confiance est attribué à chaque boîte englobante qui représente la probabilité que la prédiction soit correcte.
- Sortie : Après que les carrés de la grille ont été évalués, la sortie finale listera tous les objets dans l'image, ainsi que chaque boîte englobante et son étiquette. Dans le cadre du post-traitement, une suppression non maximale (NMS) aura lieu pour supprimer les boîtes qui se chevauchent, garantissant que chaque objet est représenté par une seule boîte avec le score de confiance le plus élevé. Cette étape améliore la précision de la détection d'objets et rend l'ensemble du processus plus efficace en filtrant le bruit supplémentaire pour créer une sortie plus propre.
Vous voulez en savoir plus sur Logiciel de reconnaissance d'image ? Découvrez les produits Reconnaissance d'image.
Types de YOLO dans la détection d'objets
Depuis son développement, YOLO a traversé plusieurs itérations qui ont intégré des technologies mises à jour et ont créé un flux de travail plus rapide et plus efficace. Voici un bref aperçu de YOLO v1-v6 et un regard sur où nous en sommes aujourd'hui :
- YOLOv1 : L'algorithme original était principalement axé sur la détection d'objets comme un problème de régression plutôt que les approches de classification traditionnelles, ce qui était révolutionnaire à l'époque. Cette fondation est encore utilisée dans les modèles YOLO aujourd'hui.
- YOLOv2 : Également connu sous le nom de YOLO 9000, cette version a construit sur les concepts originaux de YOLO et a abordé certaines des limitations du premier modèle. Les boîtes d'ancrage ont été introduites comme des boîtes prédéterminées dans la grille, avec des rapports d'aspect et des échelles uniques. Cela a rendu la prédiction des boîtes englobantes plus facile et mieux adaptée aux objets réels dans l'image. La version comprenait également des mises à jour pour gérer des images à plus haute résolution sans ralentir les temps de traitement.
- YOLOv3 : Cette version a introduit une technique connue sous le nom de "réseau pyramidal de caractéristiques" (FPN), qui a été utilisée pour détecter des objets de tailles différentes dans l'image. La vitesse de traitement a également été augmentée dans la troisième version de YOLO grâce à l'utilisation de Darknet-53.
- YOLOv4 : Avec une version mise à jour de Darknet, CSPDarnet, la quatrième version de YOLO était significativement plus rapide et plus précise que les itérations précédentes. La précision s'est améliorée d'environ 0,5 % en moyenne grâce à l'introduction d'une technique connue sous le nom de "connexion partielle croisée" ou CSP, où plusieurs modèles ont été introduits en même temps pour combiner leurs capacités de prédiction.
- YOLOv5 : Introduite en 2020, la cinquième version de YOLO a introduit une architecture de réseau neuronal mise à jour appelée EfficientDet. EfficientDet était une série de modèles de classification d'images conçus pour améliorer la précision computationnelle et l'utilisation de la mémoire tout en atteignant les niveaux les plus élevés de précision de sortie. Les boîtes d'ancrage n'étaient plus nécessaires avec la version 5, une seule couche convolutive étant capable de prédire directement les boîtes englobantes des objets, quelle que soit leur forme ou leur taille.
- YOLOv6 : L'introduction d'un nouveau réseau neuronal plus léger signifiait que la version 6 de YOLO fonctionnait plus efficacement et avec moins de ressources nécessaires. L'augmentation des données a également été introduite pendant l'entraînement, ce qui permet au modèle de reconnaître encore des objets lorsqu'ils sont retournés, tournés ou mis à l'échelle dans l'image d'entrée.
Les mises à jour les plus récentes de YOLO, des versions 7 à 9, ont continué à voir des améliorations de vitesse et de précision à mesure que l'algorithme est adapté en fonction des percées actuelles de l'apprentissage profond. La capacité d'apprentissage de l'algorithme a considérablement augmenté avec ces nouveaux modèles, permettant à la détection d'objets d'être encore possible avec des données d'image floues ou incomplètes.
Industries qui utilisent "You Only Look Once"
Il existe de nombreuses façons dont YOLO peut être mis en œuvre dans la vie quotidienne, mais certaines industries bénéficient plus de cette technologie que d'autres.
Sécurité
Les systèmes de surveillance deviennent plus complexes chaque année, aidant à nous garder en sécurité où que nous soyons. YOLO est souvent utilisé pour détecter les individus surveillés par les forces de l'ordre à travers les systèmes de vidéosurveillance et de caméras de sécurité tout en surveillant également les crimes tels que le vol à l'étalage ou l'agression en temps réel.
Santé
Comme d'autres formes de détection d'objets et de reconnaissance d'images, YOLO peut être utilisé dans les soins médicaux en temps réel et le traitement d'imagerie. Plusieurs études ont trouvé une utilisation répandue de YOLO dans cette industrie, y compris les procédures chirurgicales où la détection d'organes est nécessaire en raison de la diversité biologique des différents patients. Les scans 2D et 3D peuvent rapidement et précisément localiser le placement des organes, fournissant un aperçu des problèmes potentiels que l'imagerie médicale est utilisée pour détecter.
Agriculture
Le développement de l'IA a considérablement aidé l'industrie agricole, permettant aux agriculteurs de surveiller leurs cultures à tout moment sans avoir besoin de supervision manuelle. YOLO et la robotique agricole ont remplacé la cueillette et la récolte manuelles dans de nombreux cas. Il est également utilisé pour identifier quand les cultures sont à leur maturité optimale pour la cueillette en fonction des caractéristiques de couleur ou de taille des objets (cultures) dans les images.
Véhicules autonomes
Pour les voitures autonomes, YOLO aide à identifier les panneaux de signalisation, les piétons et autres dangers routiers avec rapidité et précision, tout comme le ferait un conducteur humain.
Avantages de YOLO
Il existe de nombreux avantages à utiliser des algorithmes comme YOLO dans les modèles d'IA pour la détection d'objets, en particulier en termes de vitesse et de précision.
- Applications en temps réel : Pour les industries où la gestion du temps et la réactivité rapide sont essentielles, comme les voitures autonomes et la sécurité, YOLO est l'une des meilleures options automatisées pour détecter des objets dans une image ou une vidéo.
- Niveaux élevés de précision : Avec chaque nouvelle version de YOLO, l'algorithme devient plus précis dans la détection d'objets avec confiance dans les boîtes englobantes de sortie. Les classifications et les emplacements des objets dans les images sont plus précis à chaque fois.
- Efficacité en un seul coup : Au lieu d'attendre que les images soient passées à travers plusieurs couches d'un réseau neuronal, YOLO peut traiter l'information en une seule étape pour améliorer son efficacité et sa vitesse globales.
- Capacité à évaluer des images de différentes échelles : YOLO est maintenant capable de traiter des images avec différents rapports d'aspect et de déterminer des objets de tailles différentes dans des modèles qui utilisent des boîtes d'ancrage ainsi que ceux sans.
Principaux outils de reconnaissance d'images utilisés pour "You Only Look Once"
YOLO peut n'être utilisé que pour un rôle spécifique dans la reconnaissance d'images, la détection d'objets, mais ces outils peuvent être ajoutés aux flux de travail pour accomplir de nombreuses autres tâches. La détection d'objets n'est qu'une partie de la façon dont les images sont traitées à l'aide de l'IA, avec des aspects tels que la restauration d'images et la reconstruction de scènes également possibles avec ce logiciel.
Pour être inclus dans la catégorie de reconnaissance d'images, les plateformes doivent :
- Fournir un algorithme d'apprentissage profond spécifiquement pour la reconnaissance d'images
- Se connecter à des pools de données d'images pour apprendre une solution ou une fonction spécifique
- Consommer les données d'image comme une entrée et fournir une sortie
- Fournir des capacités de reconnaissance d'images à d'autres applications, processus ou services
* Ci-dessous se trouvent les cinq principales solutions logicielles de reconnaissance d'images du rapport Grid de l'été 2024 de G2. Certains avis peuvent être édités pour plus de clarté.
1. Google Cloud Vision API
Google Cloud Vision API est capable de détecter et de classer plusieurs objets dans des images en utilisant un algorithme pré-entraîné qui peut être adapté à vos propres modèles. Ce logiciel aide les développeurs à utiliser la puissance de l'apprentissage automatique avec une précision de prédiction de pointe dans l'industrie.
Ce que les utilisateurs aiment le plus :
"La chose la plus utile que j'ai expérimentée à propos de cet outil Vision API de Google est son intégration de fonctionnalités de détection dans nos projets d'apprentissage profond et d'apprentissage automatique. Son API nous aide à détecter n'importe quels objets et à les étiqueter avec une compréhension humaine et à former un modèle d'apprentissage automatique."
- Google Cloud Vision API Review, Kunal D.
Ce que les utilisateurs n'aiment pas :
"Pour les images de mauvaise qualité, il donne parfois la mauvaise réponse car certains aliments ont la même couleur. Il ne nous fournit pas l'option de personnaliser ou d'entraîner le modèle pour notre cas d'utilisation spécifique. La partie configuration est complexe."
- Google Cloud Vision API Review, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit est une bibliothèque d'apprentissage automatique multiplateforme et open source. Il séduit les développeurs et les ingénieurs en IA pour ses options de reconnaissance de gestes et d'images en temps réel qui s'intègrent dans leurs propres algorithmes et modèles.
Ce que les utilisateurs aiment le plus :
"Son ensemble étendu d'algorithmes et son interface facile à utiliser le rendent adapté aux débutants comme aux utilisateurs avancés."
- Gesture Recognition Toolkit Review, Ram M.
Ce que les utilisateurs n'aiment pas :
"Gesture Recognition Toolkit a des lags occasionnels et un processus de mise en œuvre moins fluide. Les temps de réponse du support client pourraient être plus rapides."
- Gesture Recognition Toolkit Review, Civic V.
3. SuperAnnotate
SuperAnnotate est une plateforme pour construire, affiner et gérer vos modèles d'IA avec les données d'entraînement de la plus haute qualité, leader de l'industrie. La technologie d'annotation avancée et les outils d'assurance qualité vous permettent de construire des modèles d'apprentissage automatique réussis et des ensembles de données de haut niveau.
Ce que les utilisateurs aiment le plus :
"Je cherchais un outil pour annoter des images biologiques. Après avoir essayé de nombreux outils, j'ai trouvé deux des meilleures plateformes pour moi-même. L'une d'elles est Superannotate. Ces plateformes avaient le plus large ensemble d'outils d'annotation, y compris exactement ceux dont j'avais besoin. Les outils sont pratiques à utiliser."
- SuperAnnotate Review, Artem M.
Ce que les utilisateurs n'aiment pas :
"Nous avons eu quelques problèmes avec les flux de travail personnalisés que l'équipe a mis en œuvre pour des projets spécifiques sur leur plateforme. Pour certains flux de travail personnalisés, nous avons remarqué que l'outil d'analyse rapportait mal le temps pris pour l'annotation."
- SuperAnnotate Review, Rohan K.
4. Syte
Syte est la première plateforme de découverte de produits alimentée par l'IA au monde, aidant à la fois les consommateurs et les détaillants à se connecter avec des produits. La recherche par caméra, la personnalisation et les outils en magasin comme la reconnaissance d'images offrent une expérience instantanée et intuitive pour les acheteurs.
Ce que les utilisateurs aiment le plus :
"L'équipe offre constamment des idées précieuses et des alternatives pour améliorer la fonctionnalité et l'efficacité de l'outil Shop Similar. Travailler avec Syte facilite l'atteinte des KPI spécifiques de notre site."
- Syte Review, Gabriella M.
Ce que les utilisateurs n'aiment pas :
"Il y a eu quelques difficultés à activer différents comptes sur le tableau de bord d'analyse. Ce serait bien de ne pas avoir de restrictions sur ces connexions (différents utilisateurs devraient pouvoir y accéder)."
- Syte Review, Antonio R.
5. Dataloop
Dataloop est une plateforme de développement d'IA qui permet aux entreprises de construire facilement leurs propres applications d'IA avec des ensembles de données intuitifs. Les outils au sein du logiciel permettent aux équipes d'optimiser l'annotation d'images, la sélection de modèles et les déploiements de modèles pour une application à grande échelle.
Ce que les utilisateurs aiment le plus :
"Dataloop a également un grand nombre de fonctionnalités qui le rendent pratique pour de nombreux utilisateurs de différents projets. Après chaque mise à jour, des instructions sont fournies qui expliquent les changements, ce qui facilite leur mise en œuvre."
- Dataloop Review, Mzamil J.
Ce que les utilisateurs n'aiment pas :
"J'ai eu des défis avec certaines courbes d'apprentissage abruptes, la dépendance à l'infrastructure et les limitations de personnalisation. Ceux-ci m'ont en quelque sorte limité dans son utilisation."
- Dataloop Review, Dennis R.

Commencez à travailler avec l'IA parce que YOLO !
En moins d'une décennie, YOLO a fait des progrès significatifs et est devenu la méthode de détection d'objets de référence pour de nombreuses industries. Grâce à son approche efficace et précise de la reconnaissance d'images, il est idéal pour les besoins en temps réel alors que vous explorez le monde de l'IA.
En savoir plus sur les réseaux neuronaux artificiels et comment les modèles sont conçus pour imiter le cerveau humain.
Édité par Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.

