

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
Wenn Sie jemand wie ich sind, genießen Sie Struktur, Ordnung und Einfachheit.
Aber in manchen Fällen ist es am besten, einen Schritt zurückzutreten und das organisierte Chaos sich entfalten zu lassen. Dies ist die Grundlage von etwas, das als Data Lake bezeichnet wird.
Was ist ein Data Lake?
Definition eines Data Lakes
Ein Data Lake ist ein Speicherort für strukturierte, unstrukturierte und semi-strukturierte Daten. Data Lakes unterscheiden sich stark von Data Warehouses, da sie es ermöglichen, Daten in ihrer rohesten Form zu speichern, ohne dass sie vorher umgewandelt und analysiert werden müssen.
Einfacher ausgedrückt, können alle Arten von Daten, die sowohl von Menschen als auch von Maschinen erzeugt werden, in einen Data Lake geladen werden, um später klassifiziert und analysiert zu werden.
Data Warehouses hingegen erfordern, dass Daten richtig strukturiert sind, bevor irgendeine Arbeit erledigt werden kann.
Um ein tieferes Verständnis für Data Lakes und warum sie der optimale Kandidat für die Speicherung von Big Data sind, ist es wichtig, sich damit zu befassen, was sie so anders macht als Data Warehouses.
Möchten Sie mehr über Datenlagerlösungen erfahren? Erkunden Sie Datenlagerhaus Produkte.
Data Lake vs. Data Warehouse
Sowohl Data Lakes als auch Data Warehouses sind Speicherorte für Daten. Das ist ungefähr die einzige Ähnlichkeit zwischen den beiden. Lassen Sie uns nun einige der wichtigsten Unterschiede ansprechen:
- Data Lakes sind darauf ausgelegt, alle Arten von Daten zu unterstützen, während Data Warehouses in den meisten Fällen hochstrukturierte Daten verwenden.
- Data Lakes speichern alle Daten, die möglicherweise irgendwann in der Zukunft analysiert werden. Dieses Prinzip gilt nicht für Data Warehouses, da irrelevante Daten aufgrund begrenzten Speicherplatzes typischerweise eliminiert werden.
- Der Umfang zwischen Data Lakes und Data Warehouses ist aufgrund unserer vorherigen Punkte drastisch unterschiedlich. Die Unterstützung aller Arten von Daten und die Speicherung dieser Daten (auch wenn sie nicht sofort nützlich sind) bedeutet, dass Data Lakes hoch skalierbar sein müssen.
- Dank Metadaten (Daten über Daten) können Benutzer, die mit einem Data Lake arbeiten, schnell grundlegende Einblicke in die Daten gewinnen. In Data Warehouses erfordert es oft ein Mitglied des Entwicklungsteams, um auf die Daten zuzugreifen – was zu einem Engpass führen könnte.
- Schließlich bedeutet das intensive Datenmanagement, das für Data Warehouses erforderlich ist, dass sie typischerweise teurer zu warten sind als Data Lakes.
James Dixon, Gründer und Chief Technology Officer von Pentaho, prägte den Begriff „Data Lake“, nachdem er eine Analogie zur Unterscheidung von Data Lakes und Data Warehouses bereitgestellt hatte.
„Wenn Sie sich einen Datenmarkt als einen Laden mit abgefülltem Wasser vorstellen – gereinigt und verpackt und strukturiert für den einfachen Konsum – ist der Data Lake ein großer Wasserkörper in einem natürlicheren Zustand“, sagte Dixon. „Der Inhalt des Data Lakes strömt aus einer Quelle, um den See zu füllen, und verschiedene Benutzer des Sees können kommen, um ihn zu untersuchen, einzutauchen oder Proben zu entnehmen.“
James Dixon
Gründer und Chief Technology Officer von Pentaho
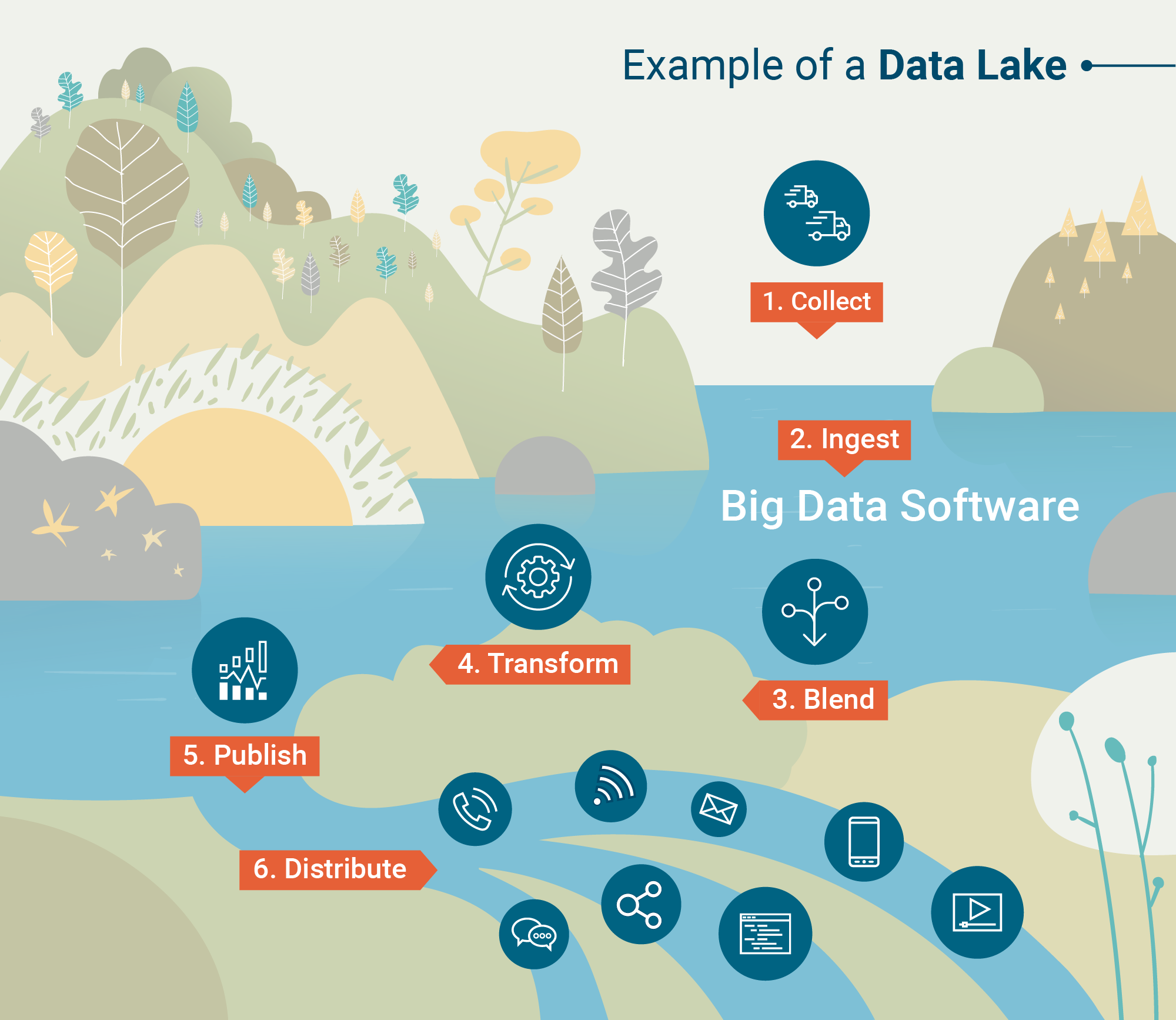
Data Lake Architektur
Wie sind Data Lakes in der Lage, so große und vielfältige Datenmengen zu speichern? Was ist die zugrunde liegende Architektur dieser riesigen Speicherorte?
Data Lakes basieren auf einem Schema-on-Read-Datenmodell. Ein Schema ist im Wesentlichen das Skelett einer Datenbank, das ihr Modell und die Strukturierung der Daten innerhalb dieser beschreibt. Denken Sie an einen Bauplan.
Das Schema-on-Read-Datenmodell bedeutet, dass Sie Ihre Daten so, wie sie sind, in den See laden können, ohne sich um deren Struktur kümmern zu müssen. Dies ermöglicht viel mehr Flexibilität.
Data Warehouses hingegen bestehen aus Schema-on-Write-Datenmodellen. Dies ist ein viel traditionelleres Modell für Datenbanken.
Jeder Datensatz, jede Beziehung und jeder Index im Schema-on-Write-Datenmodell muss im Voraus klar definiert werden. Dies schränkt die Flexibilität ein, insbesondere beim Hinzufügen neuer Datensätze oder Funktionen, die potenziell Lücken innerhalb der Datenbank schaffen könnten.
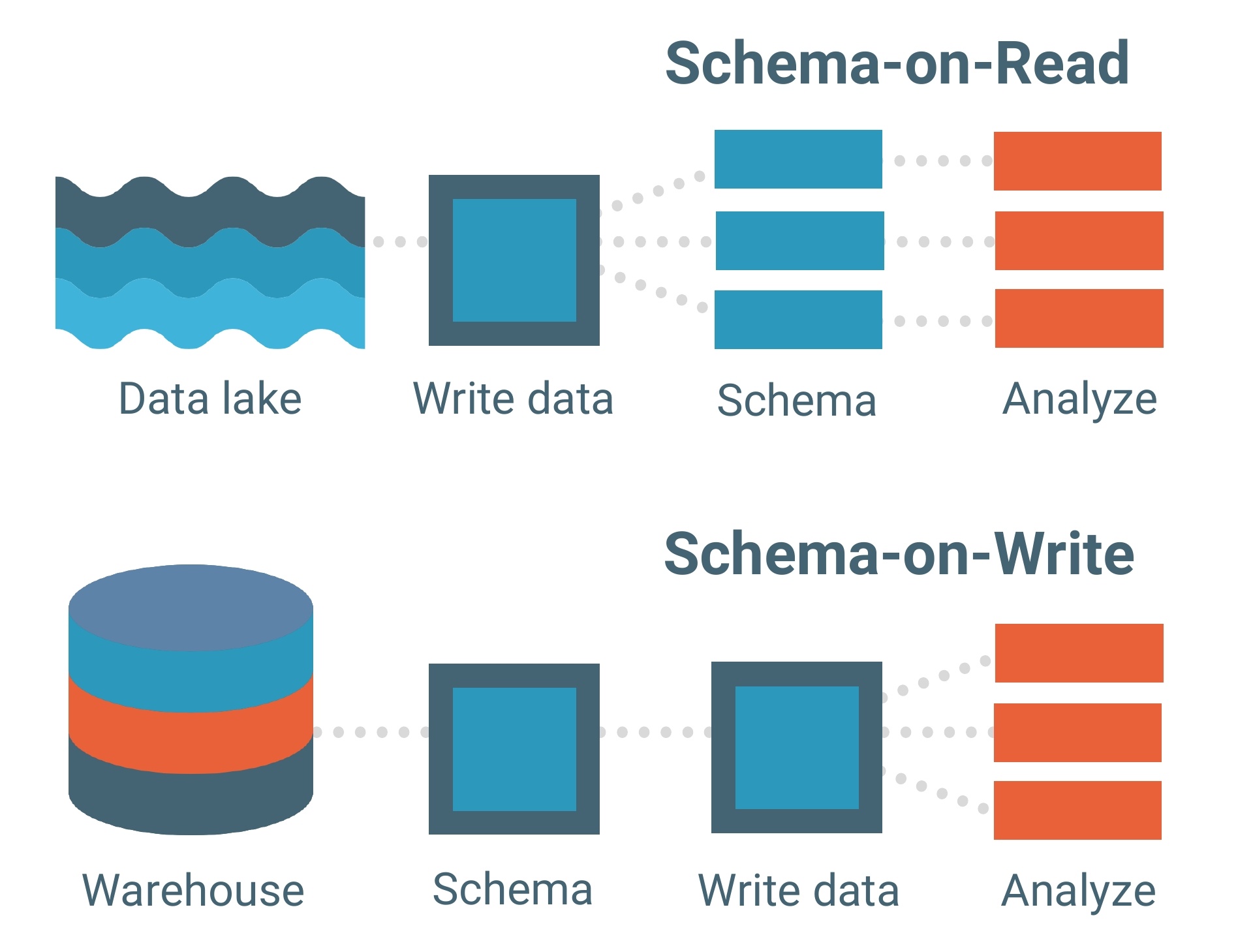
Das Schema-on-Read-Datenmodell fungiert als Rückgrat eines Data Lakes, aber das Verarbeitungsframework (oder die Engine) ist, wie Daten tatsächlich in einen geladen werden.
Nachfolgend sind die beiden Verarbeitungsframeworks aufgeführt, die Daten in Data Lakes „aufnehmen“:
- Batch-Verarbeitung – Millionen von Datenblöcken, die über lange Zeiträume (Stunden bis Tage) verarbeitet werden. Die am wenigsten zeitkritische Methode zur Verarbeitung von Big Data.
- Stream-Verarbeitung – Kleine Datenmengen, die in Echtzeit verarbeitet werden. Die Stream-Verarbeitung wird für Unternehmen, die Echtzeitanalysen nutzen, immer wertvoller.

Hadoop, Apache Spark und Apache Storm gehören zu den häufiger verwendeten Big Data-Verarbeitungstools, die entweder Batch- oder Stream-Verarbeitung durchführen können.
Einige Tools sind besonders nützlich für die Verarbeitung unstrukturierter Daten wie Sensoraktivitäten, Bilder, Social-Media-Posts und Internet-Clickstream-Aktivitäten. Andere Tools priorisieren Verarbeitungsgeschwindigkeit und Nützlichkeit mit maschinellen Lernprogrammen.
Sobald die Daten verarbeitet und in den Data Lake aufgenommen wurden, ist es an der Zeit, sie zu nutzen.
Wofür werden Data Lakes verwendet?
Data Warehouses verlassen sich auf Struktur und saubere Daten, während Data Lakes es ermöglichen, dass Daten in ihrer natürlichsten Form vorliegen. Dies liegt daran, dass fortschrittliche Analysetools und Mining-Software Rohdaten aufnehmen und in nützliche Erkenntnisse umwandeln.
Big Data Analytics
Big Data Analytics wird in einen Data Lake eintauchen, um Muster, Markttrends und Kundenpräferenzen zu entdecken, die Unternehmen helfen, schneller fundierte Vorhersagen zu treffen. Dies geschieht durch vier verschiedene Analysen.
- Deskriptive Analyse – Eine retrospektive Analyse, die untersucht, „wo“ ein Problem für ein Unternehmen aufgetreten sein könnte. Die meisten Big Data-Analysen heute sind tatsächlich deskriptiv, da sie schnell generiert werden können.
- Diagnostische Analyse – Eine weitere retrospektive Analyse, die untersucht, „warum“ ein bestimmtes Problem für ein Unternehmen aufgetreten sein könnte. Dies ist etwas tiefergehend als deskriptive Analysen.
- Prädiktive Analyse – Wenn KI- und maschinelle Lernsoftware angewendet werden, kann diese Analyse einer Organisation prädiktive Modelle dessen liefern, was als nächstes passieren könnte. Aufgrund der Komplexität der Erstellung prädiktiver Analysen ist sie noch nicht weit verbreitet.
- Präskriptive Analyse – Die Zukunft der Big Data-Analysen sind präskriptive Analysen, die nicht nur bei Entscheidungsprozessen helfen, sondern einer Organisation möglicherweise sogar eine Reihe von Antworten liefern können. Es gibt einen sehr hohen Einsatz von maschinellem Lernen bei diesen Analysen.
Data Mining
Data Mining wird als „Wissensentdeckung in Datenbanken“ definiert und ist, wie Datenwissenschaftler bisher unbekannte Muster und Wahrheiten durch verschiedene Modelle aufdecken.
Zum Beispiel ist eine Clusteranalyse eine Art von Data Mining-Technik, die auf einen Satz innerhalb eines Data Lakes angewendet werden kann. Dies wird große Datenmengen basierend auf ihren Ähnlichkeiten gruppieren.
Durch Datenvisualisierungstools hilft Data Mining, die chaotische Natur unstrukturierter, roher Datenformen zu klären.
Herausforderungen von Data Lakes
Data Lakes mögen flexibel, skalierbar und schnell zu laden sein, aber das hat seinen Preis.
Das Aufnehmen unstrukturierter Daten erfordert einen Mangel an Datenverwaltung und Prozessen, die sicherstellen, dass die richtigen Daten betrachtet werden. Für die meisten Unternehmen – insbesondere diejenigen, die noch kein Big Data eingeführt haben – ist das Vorhandensein unorganisierter, ungeklärter Daten keine Option.
Der Missbrauch von Metadaten oder Prozessen, um den Data Lake in Schach zu halten, kann tatsächlich zu etwas führen, das als Data Swamp bezeichnet wird. Würden Sie in einem Sumpf schwimmen gehen?
Es gibt auch das Problem der Datensicherheit.
Data Lakes sind ein relativ neues Konzept in der IT, was bedeutet, dass einige der Tools noch an den Sicherheitsproblemen arbeiten. Eines dieser Probleme besteht darin, sicherzustellen, dass nur die richtigen Personen Zugriff auf sensible Daten haben, die in den See geladen werden.
Aber wie bei jeder neuen Technologie werden sich diese Probleme mit der Zeit lösen.
| TIPP: Bereit, tiefer in die Datenwelt einzutauchen? Lernen Sie die Grundlagen des Master Data Management (MDM) und warum es für Unternehmen wichtig ist. |
Die Rolle von Data Lakes bei Big Data
Trotz einiger Herausforderungen von Data Lakes bleibt die Tatsache bestehen, dass mehr als 80 Prozent aller Daten unstrukturiert sind. Da sich mehr Unternehmen Big Data für zukünftige Chancen zuwenden, wird die Anwendung von Data Lakes zunehmen.
Unstrukturierte Daten wie Social-Media-Posts, Telefonaufzeichnungen und Clickstream-Aktivitäten enthalten wertvolle Informationen, die in Data Warehouses nicht zurückgehalten werden können.
Während Data Warehouses in Struktur und Sicherheit stark sind, muss Big Data einfach ungebunden sein, damit es frei in Data Lakes fließen kann.
Sehen Sie sich unseren vollständigen Leitfaden zu strukturierten vs. unstrukturierten Daten für eine ausführlichere Erklärung an oder lesen Sie über die Bedeutung des Big Data Engineering.