

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.
Vladimir N. Vapnik entwickelte in den 1990er Jahren Support Vector Machine (SVM)-Algorithmen, um Klassifikationsprobleme zu lösen. Diese Algorithmen finden eine optimale Hyperebene, die eine Linie in einer 2D- oder 3D-Ebene zwischen zwei Datensatzkategorien ist, um zwischen ihnen zu unterscheiden.
SVM erleichtert den Prozess des maschinellen Lernens (ML), neue Daten zu verallgemeinern und gleichzeitig genaue Klassifikationsvorhersagen zu treffen.
Viele Bilderkennungssoftware und Textklassifikationsplattformen verwenden SVM, um Bilder oder Textdokumente zu klassifizieren. Aber die Reichweite von SVMs geht darüber hinaus. Nachdem wir die Grundlagen behandelt haben, lassen Sie uns einige ihrer breiteren Anwendungen erkunden.
Was sind Support Vector Machines?
Support Vector Machines (SVMs) sind überwachte maschinelle Lernalgorithmen, die Klassifikationsmethoden für Objekte in einem n-dimensionalen Raum entwickeln. Die Koordinaten dieser Objekte werden üblicherweise als Merkmale bezeichnet.
SVMs zeichnen eine Hyperebene, um zwei Objektkategorien zu trennen, sodass alle Punkte einer Objektkategorie auf einer Seite der Hyperebene liegen. Das Ziel ist es, die beste Ebene zu finden, die den Abstand (oder die Marge) zwischen zwei Punkten in jeder Kategorie maximiert. Die Punkte, die auf dieser Marge liegen, werden als Stützvektoren bezeichnet. Diese Stützvektoren sind entscheidend für die Definition der optimalen Hyperebene.
Support Vector Machines im Detail verstehen
SVM erfordert ein Training mit markierten Punkten aus bestimmten Kategorien, um die Hyperebene zu finden, was es zu einem überwachten Lernalgorithmus macht. Der Algorithmus löst im Hintergrund ein konvexes Optimierungsproblem, um die Marge mit jedem Kategorisierungspunkt auf der richtigen Seite zu maximieren. Basierend auf diesem Training kann er einem Objekt eine neue Kategorie zuweisen.

Quelle: Visually Explained
Support Vector Machines sind einfach zu verstehen, zu implementieren, zu verwenden und zu interpretieren. Ihre Einfachheit ist jedoch nicht immer von Vorteil. In einigen Situationen ist es unmöglich, zwei Kategorien mit einer einfachen Hyperebene zu trennen. Um dies zu lösen, findet der Algorithmus eine Hyperebene im höherdimensionalen Raum mit einer Technik, die als Kernel-Trick bekannt ist, und projiziert sie zurück in den ursprünglichen Raum.
Es ist der Kernel-Trick, der es Ihnen ermöglicht, diese Schritte effizient durchzuführen.
Möchten Sie mehr über Bildverarbeitungssoftware erfahren? Erkunden Sie Bilderkennung Produkte.
Was ist ein Kernel-Trick?
In der realen Welt ist es schwierig, die meisten Datensätze mit einer einfachen Hyperebene zu trennen, da die Grenze zwischen zwei Klassen selten flach ist. Hier kommt der Kernel-Trick ins Spiel. Er ermöglicht es SVM, nichtlineare Entscheidungsgrenzen effizient zu handhaben, ohne den Algorithmus selbst wesentlich zu verändern.
Die Wahl dieser nichtlinearen Transformation ist jedoch knifflig. Um eine anspruchsvolle Entscheidungsgrenze zu erhalten, müssen Sie die Dimension des Outputs erhöhen, was die Rechenanforderungen erhöht.
Der Kernel-Trick löst diese beiden Herausforderungen auf einen Schlag. Er basiert auf einem Ansatz, bei dem der SVM-Algorithmus nicht wissen muss, wann jeder Punkt unter nichtlinearer Transformation abgebildet wird. Er kann damit arbeiten, wie jeder Datenpunkt mit anderen verglichen wird.
Während der Anwendung der nichtlinearen Transformation nehmen Sie das innere Produkt zwischen F(x) und F(x) prime, bekannt als Kernel-Funktion.
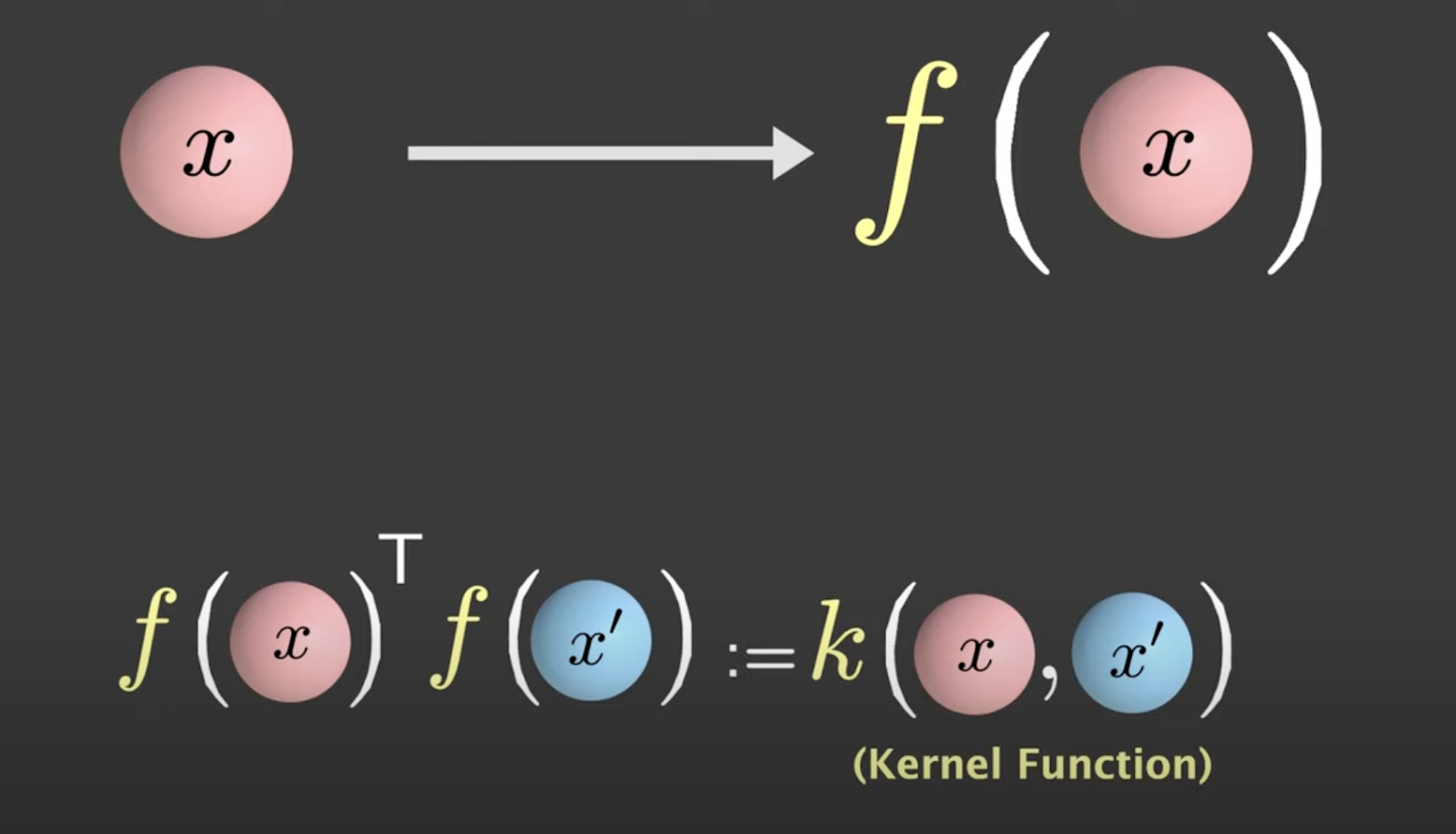
Quelle: Visually Explained
Dieser lineare Kernel gibt jedoch eine Entscheidungsgrenze, die möglicherweise nicht gut genug ist, um die Daten zu trennen. In solchen Fällen verwenden Sie eine polynomiale Transformation, die einem polynomialen Kernel entspricht. Dieser Ansatz berücksichtigt die ursprünglichen Merkmale des Datensatzes und berücksichtigt auch deren Interaktionen, um eine anspruchsvollere, gekrümmte Entscheidungsgrenze zu erhalten.

Quelle: Visually Explained
Der Kernel-Trick ist vorteilhaft und fühlt sich wie ein Cheat-Code in einem Videospiel an. Es ist einfach, mit Kernen zu experimentieren und kreativ zu werden.
Arten von Support Vector Machine Klassifikatoren
Es gibt zwei Arten von SVM-Klassifikatoren: linear und Kernel.
1. Lineare SVMs
Lineare SVMs werden verwendet, wenn Daten keine Transformationen benötigen und linear trennbar sind. Eine einzelne gerade Linie kann die Datensätze leicht in Kategorien oder Klassen unterteilen.
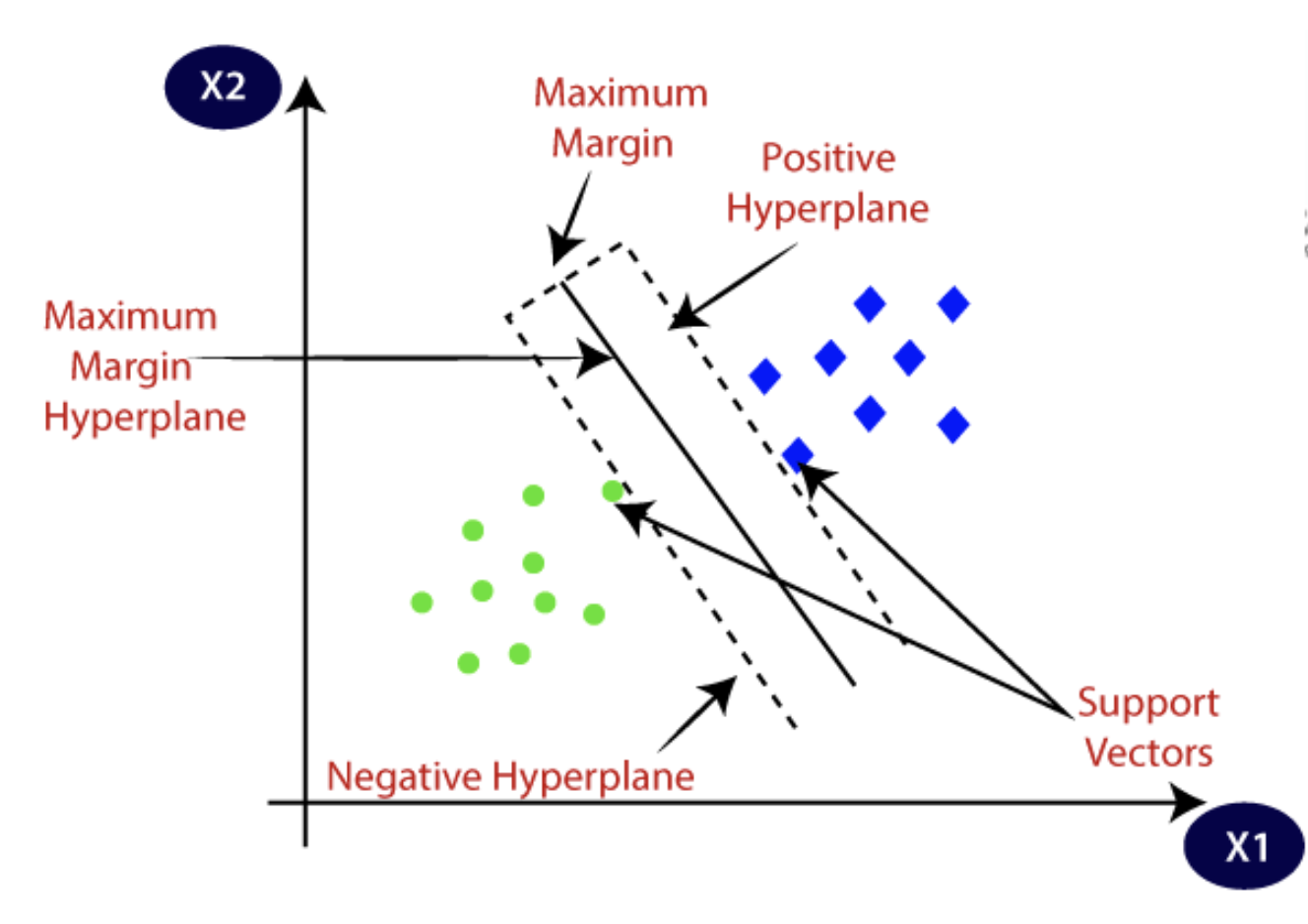
Quelle: Javatpoint
Da diese Daten linear unterscheidbar sind, wird der angewandte Algorithmus als linearer SVM bezeichnet, und der von ihm erzeugte Klassifikator ist der SVM-Klassifikator. Dieser Algorithmus ist sowohl für Klassifikations- als auch für Regressionsanalyse Probleme effektiv.
2. Nichtlineare oder Kernel-SVMs
Wenn Daten nicht durch eine gerade Linie linear trennbar sind, wird ein nichtlinearer oder Kernel-SVM-Klassifikator verwendet. Für nichtlineare Daten erfolgt die Klassifikation durch Hinzufügen von Merkmalen in höhere Dimensionen, anstatt sich auf den 2D-Raum zu verlassen.
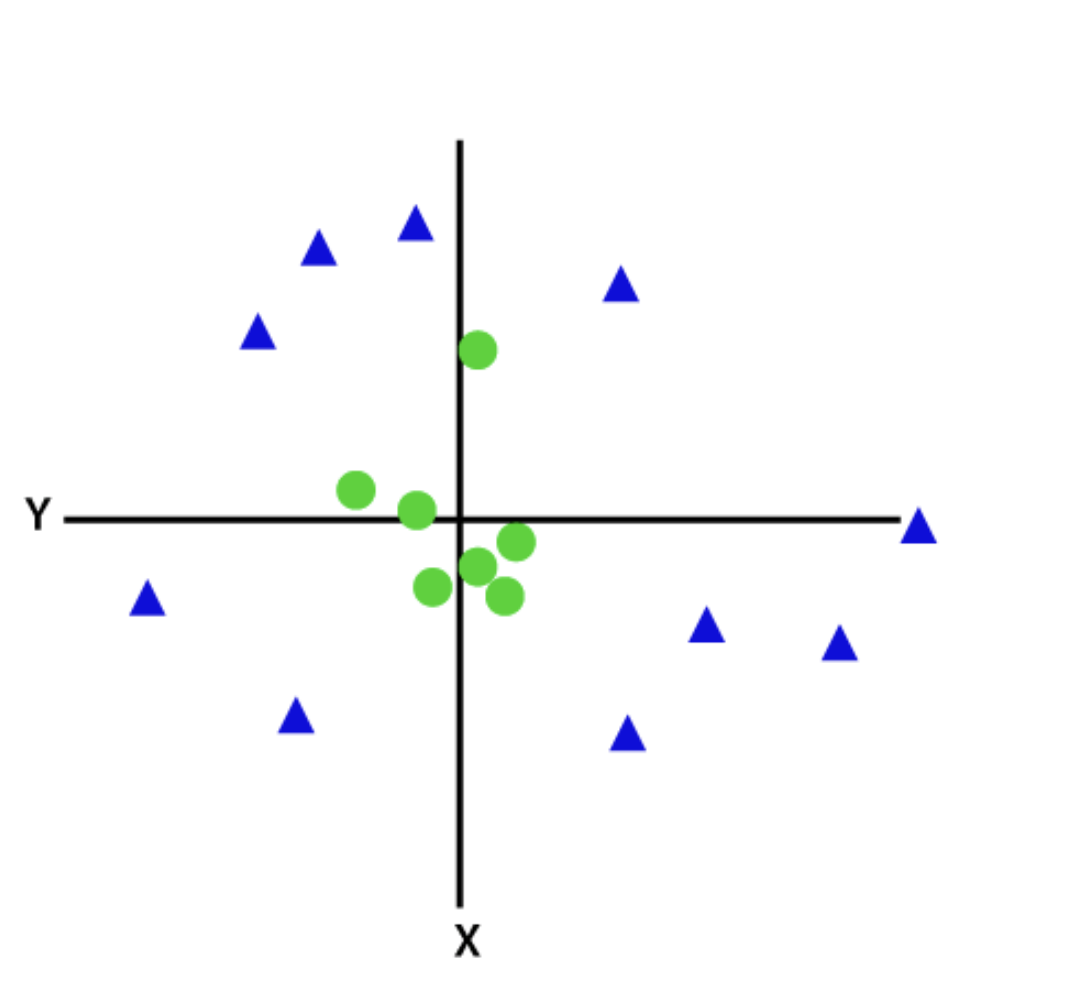
Quelle: Javatpoint
Nach der Transformation wird es einfach, eine Hyperebene hinzuzufügen, die Klassen oder Kategorien leicht trennt. Diese SVMs werden normalerweise für Optimierungsprobleme mit mehreren Variablen verwendet.
Der Schlüssel zu nichtlinearen SVMs ist der Kernel-Trick. Durch die Anwendung verschiedener Kernel-Funktionen wie linear, polynomiell, radialer Basisfunktion (RDF) oder Sigmoid-Kernel können SVMs eine Vielzahl von Datenstrukturen handhaben. Die Wahl des Kernels hängt von den Eigenschaften der Daten und dem zu lösenden Problem ab.
Wie funktioniert eine Support Vector Machine?
Der Support Vector Machine Algorithmus zielt darauf ab, eine Hyperebene zu identifizieren, um Datenpunkte aus verschiedenen Klassen zu trennen. Sie wurden ursprünglich für binäre Klassifikationsprobleme entwickelt, haben sich jedoch weiterentwickelt, um Mehrklassenprobleme zu lösen.
Basierend auf den Datenmerkmalen verwenden SVMs Kernel-Funktionen, um Datenmerkmale in höhere Dimensionen zu transformieren, was es einfacher macht, eine Hyperebene hinzuzufügen, die verschiedene Klassen von Datensätzen trennt. Dies geschieht durch die Kernel-Trick-Technik, bei der die Datenumwandlung effizient und kostengünstig erreicht wird.
Um zu verstehen, wie SVM funktioniert, müssen wir uns ansehen, wie ein SVM-Klassifikator aufgebaut ist. Es beginnt mit der Aufteilung der Daten. Teilen Sie Ihre Daten in einen Trainingssatz und einen Testsatz. Dies hilft Ihnen, Ausreißer oder fehlende Daten zu identifizieren. Obwohl technisch nicht notwendig, ist es eine gute Praxis.
Als nächstes können Sie ein SVM-Modul für jede Bibliothek importieren. Scikit-learn ist eine beliebte Python-Bibliothek für Support Vector Machines. Es bietet eine effektive SVM-Implementierung für Klassifikations- und Regressionsaufgaben. Beginnen Sie damit, Ihre Proben auf dem Klassifikator zu trainieren und Antworten vorherzusagen. Vergleichen Sie den Testsatz und die vorhergesagten Daten, um die Genauigkeit zur Leistungsevaluierung zu vergleichen.
Es gibt andere Bewertungsmetriken, die Sie verwenden können, wie:
- F1-Score berechnet, wie oft ein Modell eine korrekte Vorhersage über den gesamten Datensatz gemacht hat. Es kombiniert die Präzisions- und Rückrufwerte eines Modells.
- Präzision misst, wie oft ein maschinelles Lernmodell die positive Klasse korrekt vorhersagt.
- Rückruf bewertet, wie oft ein ML-Modell echte Positive aus allen tatsächlichen positiven Proben im Datensatz identifiziert.
Dann können Sie die Hyperparameter anpassen, um die Leistung eines SVM-Modells zu verbessern. Sie erhalten die Hyperparameter, indem Sie verschiedene Kernel, Gamma-Werte und Regularisierungen iterieren, was Ihnen hilft, die optimalste Kombination zu finden.
Anwendungen von Support Vector Machines
SVMs finden in mehreren Bereichen Anwendung. Lassen Sie uns einige Beispiele für SVMs betrachten, die auf reale Probleme angewendet werden.
- Schätzung der Bodenoberflächenfestigkeit: Die Berechnung der Bodenverflüssigung ist entscheidend für die Planung von Bauwerken im Bauwesen, insbesondere in erdbebengefährdeten Zonen. SVMs helfen vorherzusagen, ob Verflüssigung im Boden auftritt, indem Modelle erstellt werden, die mehrere Variablen zur Bewertung der Bodenfestigkeit enthalten.
- Geo-Sounding-Problem: SVMs helfen, die geschichtete Struktur des Planeten zu verfolgen. Die Regularisierungseigenschaften der Support-Vector-Formulierung werden auf das geosounding inverse Problem angewendet. Hierbei schätzen die Ergebnisse die Variablen oder Parameter, die sie erzeugt haben. Der Prozess umfasst lineare Funktionen und support vector algorithmische Modelle, die elektromagnetische Daten trennen.
- Erkennung von Protein-Remote-Homologie: SVM-Modelle verwenden Kernel-Funktionen, um Ähnlichkeiten in Proteinsequenzen basierend auf den Aminosäuresequenzen zu erkennen. Dies hilft, Proteine in strukturelle und funktionale Parameter zu kategorisieren, was in der computergestützten Biologie wichtig ist.
- Gesichtserkennung und Ausdrucksklassifikation: SVMs klassifizieren Gesichtsstrukturen von nicht-gesichtlichen. Diese Modelle analysieren die Pixel und klassifizieren die Merkmale in gesichtliche oder nicht-gesichtliche Merkmale. Am Ende erstellt der Prozess eine quadratische Entscheidungsgrenze um die Gesichtsstruktur basierend auf der Intensität der Pixel.
- Textkategorisierung und Handschriftenerkennung: Hier trägt jedes Dokument eine Punktzahl im Vergleich zu einem Schwellenwert, was es einfach macht, es in die relevante Kategorie zu klassifizieren. Um Handschrift zu erkennen, werden die SVM-Modelle zuerst mit Trainingsdaten zur Handschrift trainiert und dann trennen sie menschliches und computergeschriebenes basierend auf der Punktzahl.
- Erkennung von Steganographie: SVMs helfen sicherzustellen, dass digitale Bilder nicht kontaminiert oder von jemandem manipuliert werden. Es trennt jedes Pixel und speichert sie in verschiedenen Datensätzen, die SVMs später analysieren.
Klassifikationsprobleme mit Genauigkeit lösen
Support Vector Machines helfen, Klassifikationsprobleme zu lösen und gleichzeitig genaue Vorhersagen zu treffen. Diese Algorithmen können leicht mit linearen und nichtlinearen Daten umgehen, was sie für verschiedene Anwendungen geeignet macht, von der Textklassifikation bis zur Bilderkennung.
Darüber hinaus reduzieren SVMs das Overfitting, das auftritt, wenn das Modell zu viel aus den Trainingsdaten lernt und seine Leistung bei neuen Daten beeinträchtigt. Sie konzentrieren sich auf wichtige Datenpunkte, die als Stützvektoren bezeichnet werden, und helfen ihnen, zuverlässige und genaue Ergebnisse zu liefern.
Erfahren Sie mehr über maschinelle Lernmodelle und wie man sie trainiert.
Bearbeitet von Monishka Agrawal