

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.
Vladimir N. Vapnik ha sviluppato gli algoritmi delle macchine a vettori di supporto (SVM) per affrontare i problemi di classificazione negli anni '90. Questi algoritmi trovano un iperpiano ottimale, che è una linea in un piano 2D o 3D, tra due categorie di dataset per distinguerle.
Le SVM facilitano il processo dell'algoritmo di apprendimento automatico (ML) per generalizzare nuovi dati mentre effettuano previsioni di classificazione accurate.
Molti software di riconoscimento delle immagini e piattaforme di classificazione testuale utilizzano le SVM per classificare immagini o documenti testuali. Ma la portata delle SVM va oltre questi. Dopo aver coperto i fondamenti, esploriamo alcuni dei loro usi più ampi.
Cosa sono le macchine a vettori di supporto?
Le macchine a vettori di supporto (SVM) sono algoritmi di apprendimento automatico supervisionato che elaborano metodi di classificazione di oggetti in uno spazio n-dimensionale. Le coordinate di questi oggetti sono solitamente chiamate caratteristiche.
Le SVM tracciano un iperpiano per separare due categorie di oggetti in modo che tutti i punti di una categoria di oggetti siano su un lato dell'iperpiano. L'obiettivo è trovare il miglior piano, che massimizza la distanza (o margine) tra due punti in ciascuna categoria. I punti che cadono su questo margine sono chiamati vettori di supporto. Questi vettori di supporto sono critici nel definire l'iperpiano ottimale.
Comprendere in dettaglio le macchine a vettori di supporto
Le SVM richiedono l'addestramento su punti etichettati da categorie specifiche per trovare l'iperpiano, rendendolo un algoritmo di apprendimento supervisionato. L'algoritmo risolve un problema di ottimizzazione convessa in background per massimizzare il margine con ogni punto di categoria sul lato giusto. Basandosi su questo addestramento, può assegnare una nuova categoria a un oggetto.

Fonte: Visually Explained
Le macchine a vettori di supporto sono facili da comprendere, implementare, utilizzare e interpretare. Tuttavia, la loro semplicità non sempre le avvantaggia. In alcune situazioni, è impossibile separare due categorie con un semplice iperpiano. Per risolvere questo, l'algoritmo trova un iperpiano nello spazio a dimensioni superiori con una tecnica nota come trucco del kernel e lo proietta di nuovo nello spazio originale.
È il trucco del kernel che ti permette di eseguire questi passaggi in modo efficiente.
Vuoi saperne di più su Software di Riconoscimento Immagini? Esplora i prodotti Riconoscimento delle immagini.
Cos'è un trucco del kernel?
Nel mondo reale, separare la maggior parte dei dataset con un semplice iperpiano è difficile poiché il confine tra due classi è raramente piatto. È qui che entra in gioco il trucco del kernel. Permette alle SVM di gestire confini decisionali non lineari in modo efficiente senza alterare significativamente l'algoritmo stesso.
Tuttavia, scegliere questa trasformazione non lineare è complicato. Per ottenere un confine decisionale sofisticato, è necessario aumentare la dimensione dell'output, il che aumenta i requisiti computazionali.
Il trucco del kernel risolve queste due sfide in un colpo solo. Si basa su un approccio in cui l'algoritmo SVM non ha bisogno di sapere ogni volta che ogni punto viene mappato sotto trasformazione non lineare. Può lavorare con il modo in cui ogni punto dati si confronta con gli altri.
Mentre si applica la trasformazione non lineare, si prende il prodotto interno tra F(x) e F(x) primo, noto come funzione kernel.
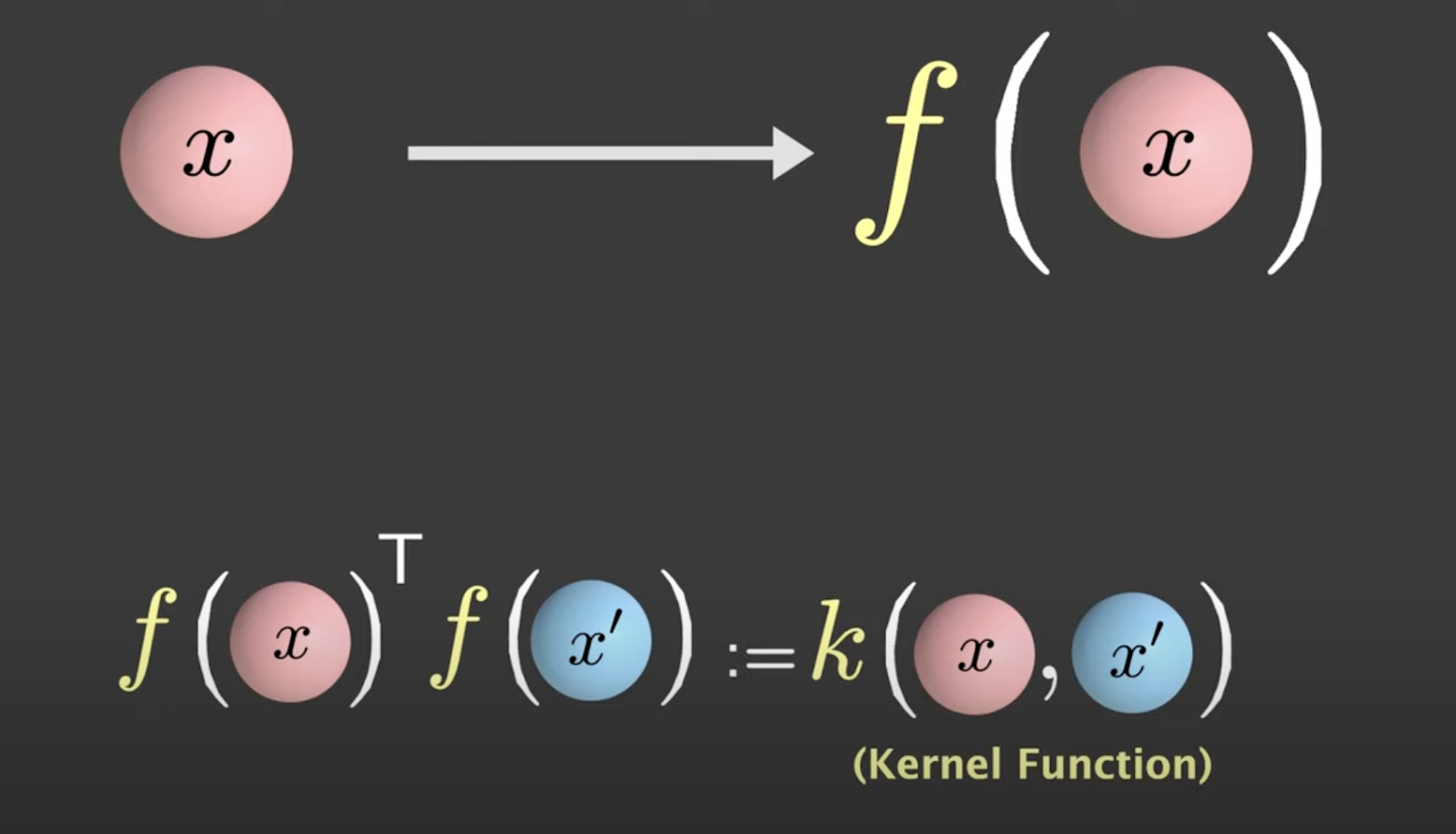
Fonte: Visually Explained
Tuttavia, questo kernel lineare fornisce un confine decisionale che potrebbe non essere abbastanza buono per separare i dati. In tali casi, si opta per una trasformazione polinomiale corrispondente a un kernel polinomiale. Questo approccio tiene conto delle caratteristiche originali del set di dati e considera le loro interazioni per ottenere un confine decisionale più sofisticato e curvo.

Fonte: Visually Explained
Il trucco del kernel è utile e sembra un codice cheat di un videogioco. È facile da modificare e da essere creativi con i kernel.
Tipi di classificatori di macchine a vettori di supporto
Ci sono due tipi di SVM classificate: lineari e kernel.
1. SVM lineari
Le SVM lineari sono quando i dati non necessitano di subire trasformazioni e sono linearmente separabili. Una singola linea retta può facilmente separare i dataset in categorie o classi.
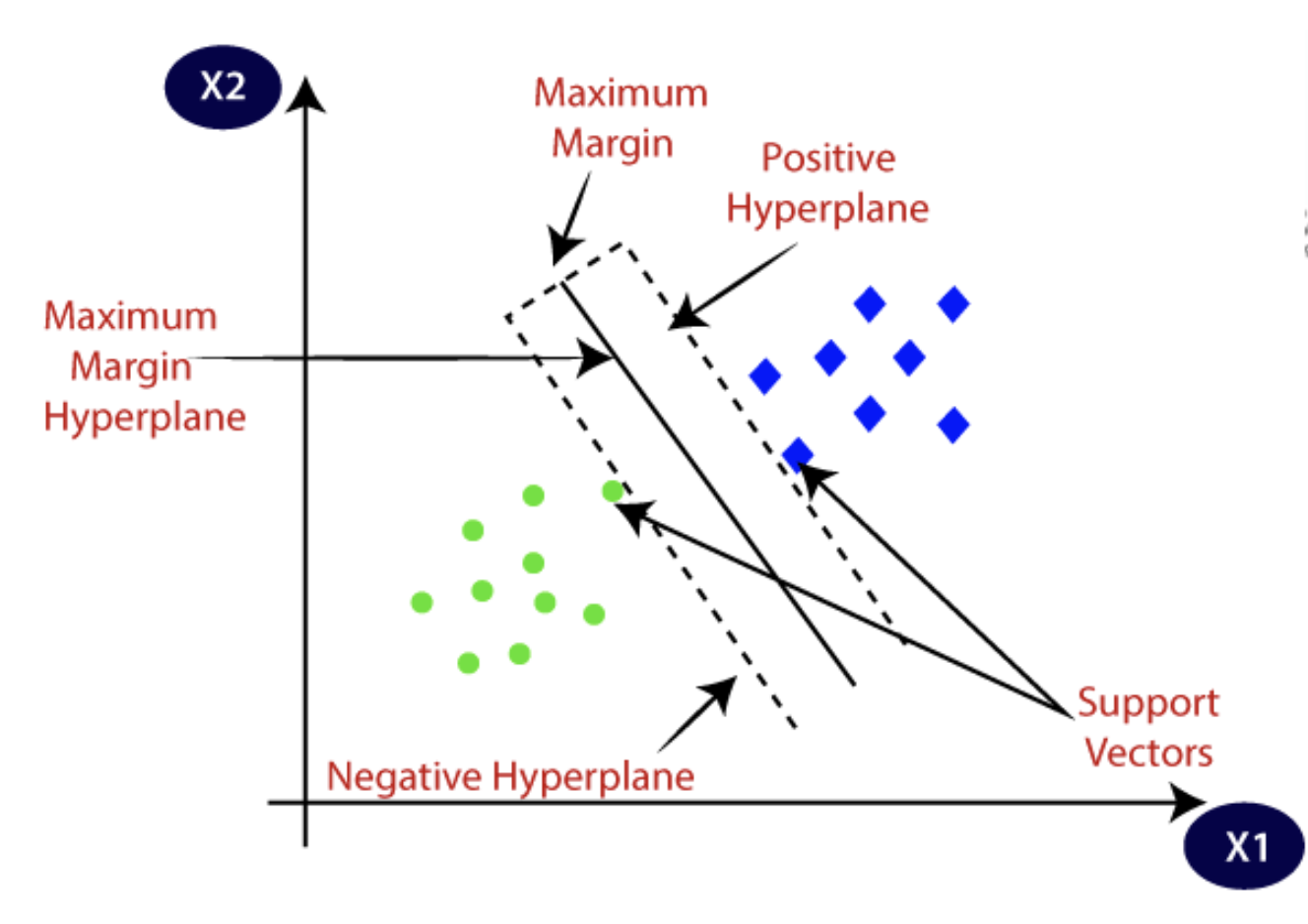
Fonte: Javatpoint
Poiché questi dati sono distinti linearmente, l'algoritmo applicato è noto come SVM lineare, e il classificatore che produce è il classificatore SVM. Questo algoritmo è efficace sia per problemi di classificazione che di analisi di regressione.
2. SVM non lineari o kernel
Quando i dati non sono separabili linearmente da una linea retta, si utilizza un classificatore SVM non lineare o kernel. Per dati non lineari, la classificazione viene eseguita aggiungendo caratteristiche in dimensioni superiori piuttosto che affidarsi allo spazio 2D.
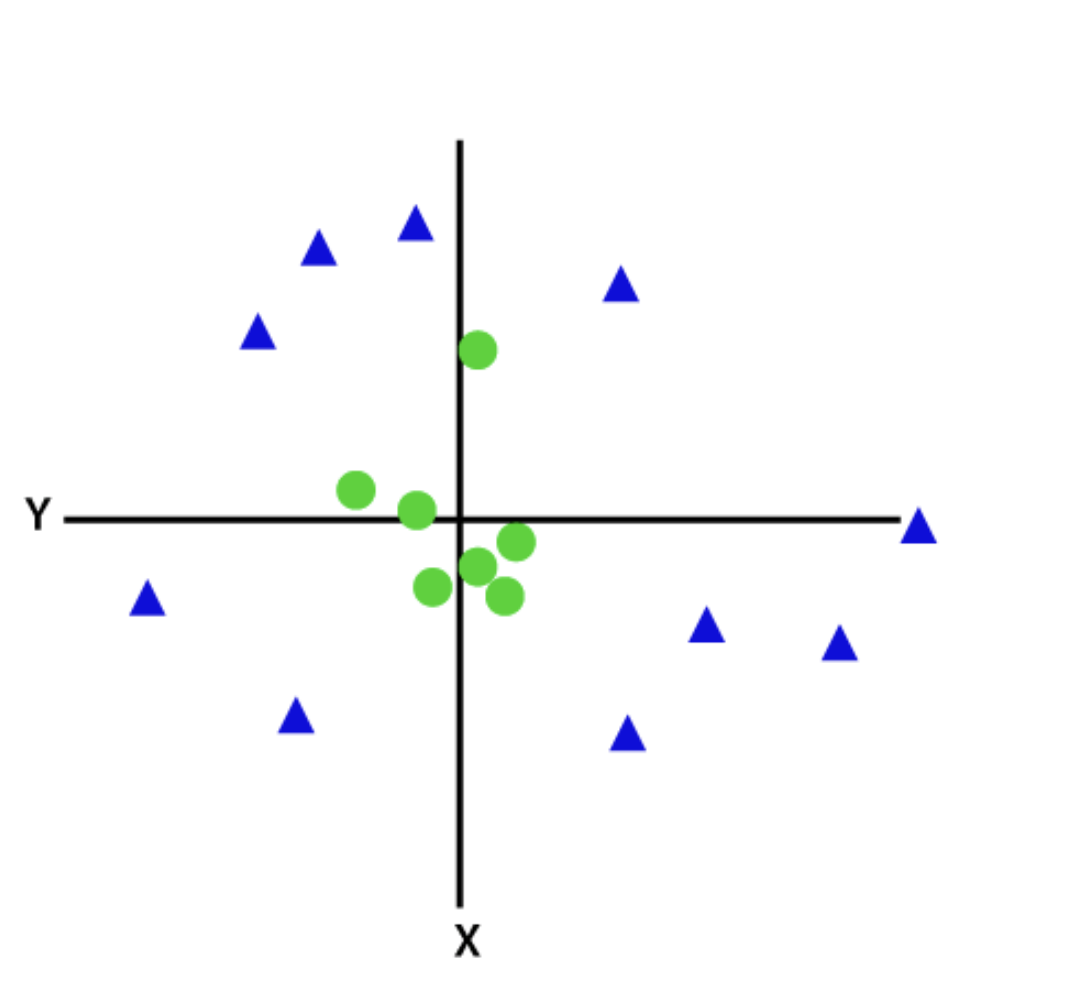
Fonte: Javatpoint
Dopo la trasformazione, aggiungere un iperpiano che separa facilmente classi o categorie diventa facile. Queste SVM sono solitamente utilizzate per problemi di ottimizzazione con diverse variabili.
La chiave delle SVM non lineari è il trucco del kernel. Applicando diverse funzioni kernel come lineare, polinomiale, funzione di base radiale (RDF) o kernel sigmoide, le SVM possono gestire una vasta gamma di strutture di dati. La scelta del kernel dipende dalle caratteristiche dei dati e dal problema da risolvere.
Come funziona una macchina a vettori di supporto?
L'algoritmo della macchina a vettori di supporto mira a identificare un iperpiano per separare i punti dati di classi diverse. Sono stati potenzialmente progettati per problemi di classificazione binaria ma si sono evoluti per risolvere problemi multiclass.
Basandosi sulle caratteristiche dei dati, le SVM impiegano funzioni kernel per trasformare le caratteristiche dei dati in dimensioni superiori, rendendo più facile aggiungere un iperpiano che separa diverse classi di dataset. Questo avviene attraverso la tecnica del trucco del kernel, dove la trasformazione dei dati viene realizzata in modo efficiente e conveniente.
Per comprendere come funzionano le SVM, dobbiamo esaminare come viene costruito un classificatore SVM. Si inizia con la divisione dei dati. Dividi i tuoi dati in un set di addestramento e un set di test. Questo ti aiuterà a identificare outlier o dati mancanti. Anche se non è tecnicamente necessario, è una buona pratica.
Successivamente, puoi importare un modulo SVM per qualsiasi libreria. Scikit-learn è una popolare libreria Python per le macchine a vettori di supporto. Offre un'implementazione SVM efficace per compiti di classificazione e regressione. Inizia addestrando i tuoi campioni sul classificatore e prevedendo le risposte. Confronta il set di test e i dati previsti per confrontare l'accuratezza per la valutazione delle prestazioni.
Ci sono altre metriche di valutazione che puoi utilizzare, come:
- F1-score calcola quante volte un modello ha fatto una previsione corretta su tutto il dataset. Combina i punteggi di precisione e richiamo di un modello.
- Punteggio di precisione misura quanto spesso un modello di apprendimento automatico prevede correttamente la classe positiva.
- Richiamo valuta quanto spesso un modello ML identifica veri positivi da tutti i campioni positivi effettivi nel dataset.
Quindi, puoi regolare gli iperparametri per migliorare le prestazioni di un modello SVM. Ottieni gli iperparametri iterando su diversi kernel, valori gamma e regolarizzazione, che ti aiutano a individuare la combinazione più ottimale.
Applicazioni delle macchine a vettori di supporto
Le SVM trovano applicazioni in diversi campi. Diamo un'occhiata ad alcuni esempi di SVM applicate a problemi del mondo reale.
- Stima della resistenza della superficie del suolo: Calcolare la liquefazione del suolo è fondamentale nella progettazione di strutture di ingegneria civile, specialmente in zone soggette a terremoti. Le SVM aiutano a prevedere se la liquefazione si verifica o meno nel suolo creando modelli che includono variabili multiple per valutare la resistenza del suolo.
- Problema di geo-sondaggio: Le SVM aiutano a tracciare la struttura stratificata del pianeta. Le proprietà di regolarizzazione della formulazione a vettori di supporto vengono applicate al problema inverso del geo-sondaggio. Qui, i risultati stimano le variabili o i parametri che li hanno prodotti. Il processo coinvolge funzioni lineari e modelli algoritmici a vettori di supporto che separano i dati elettromagnetici.
- Rilevamento remoto di omologia proteica: I modelli SVM utilizzano funzioni kernel per rilevare somiglianze nelle sequenze proteiche basate sulle sequenze di amminoacidi. Questo aiuta a categorizzare le proteine in parametri strutturali e funzionali, che è importante nella biologia computazionale.
- Rilevamento facciale e classificazione delle espressioni: Le SVM classificano le strutture facciali da quelle non facciali. Questi modelli analizzano i pixel e classificano le caratteristiche in caratteristiche facciali o non facciali. Alla fine, il processo crea un confine decisionale quadrato attorno alla struttura facciale basato sull'intensità dei pixel.
- Categorizzazione testuale e riconoscimento della scrittura a mano: Qui, ogni documento porta un punteggio confrontato con un valore soglia, rendendo facile classificarlo nella categoria pertinente. Per riconoscere la scrittura a mano, i modelli SVM vengono prima addestrati con dati di addestramento sulla scrittura a mano, e poi segregano la scrittura umana e quella computerizzata basandosi sul punteggio.
- Rilevamento della steganografia: Le SVM aiutano a garantire che le immagini digitali non siano contaminate o manomesse da nessuno. Separa ogni pixel e li memorizza in diversi dataset che le SVM analizzano successivamente.
Risoluzione dei problemi di classificazione con precisione
Le macchine a vettori di supporto aiutano a risolvere i problemi di classificazione mentre effettuano previsioni accurate. Questi algoritmi possono gestire facilmente dati lineari e non lineari, rendendoli adatti a varie applicazioni, dalla classificazione testuale al riconoscimento delle immagini.
Inoltre, le SVM riducono l'overfitting, che si verifica quando il modello apprende troppo dai dati di addestramento, influenzando le sue prestazioni su nuovi dati. Si concentrano su punti dati importanti, chiamati vettori di supporto, aiutandoli a fornire risultati affidabili e accurati.
Scopri di più sui modelli di apprendimento automatico e su come addestrarli.
Modificato da Monishka Agrawal