Immagina di tradurre senza sforzo un intero libro da una lingua all'altra o di condensare pagine di testo denso in poche frasi chiare – tutto con pochi clic.
Per i professionisti del machine learning (ML), realizzare tali compiti è come navigare in un labirinto di complessità. I dati sequenziali presentano sfide uniche: input rumorosi, dipendenze nascoste e previsioni che vacillano quando il contesto viene perso.
I modelli Seq2Seq sono progettati per affrontare proprio queste sfide.
Cos'è Seq2Seq?
Sequence-to-sequence (Seq2Seq) è un modello di machine learning progettato per mappare una sequenza di input a una sequenza di output. Questo approccio è ampiamente utilizzato in compiti in cui l'input e l'output differiscono in lunghezza, come la traduzione linguistica, la sintesi del testo o la conversione da voce a testo.
I modelli Seq2Seq sono comunemente integrati in piattaforme di data science e ML e software di elaborazione del linguaggio naturale (NLP), fornendo soluzioni robuste per applicazioni reali come la traduzione automatica. Sono particolarmente efficaci nei compiti di traduzione automatica neurale, consentendo una conversione del testo senza soluzione di continuità tra lingue come l'inglese e il francese mantenendo l'accuratezza grammaticale e la fluidità.
A differenza degli algoritmi tradizionali, i modelli Seq2Seq sono progettati per gestire le sequenze mantenendo il contesto e l'ordine. Questo li rende altamente adatti per compiti in cui il significato dell'input dipende dall'ordine dei punti dati, come frasi o dati di serie temporali.
Esploriamo come funziona Seq2Seq e perché è uno strumento essenziale per le applicazioni di reti neurali. Se sei desideroso di affrontare sfide reali con ML, sei nel posto giusto!
Come funziona il modello Seq2Seq?
I modelli Seq2Seq si basano su una struttura ben definita per elaborare le sequenze e generare output significativi. Attraverso un'architettura progettata con cura, assicurano che sia le sequenze di input che quelle di output siano gestite con precisione e coerenza.
Esploriamo i componenti principali di questa architettura e come contribuiscono all'efficacia del modello.
Architettura del modello Seq2Seq
L'architettura del modello Seq2Seq include tipicamente:
- Strato di input. Questo strato riceve la sequenza di input e la converte in embedding per un'ulteriore elaborazione. Nelle implementazioni pratiche, gli embedding rappresentano spesso sequenze di parole, token o altri punti dati, a seconda del compito, come la sintesi del testo o la traduzione linguistica.
- Encoder. L'encoder consiste tipicamente in una rete neurale ricorrente (RNN), memoria a lungo termine (LSTM) o unità ricorrente gated (GRU), che elabora la sequenza di input e produce un vettore di contesto che riassume la sequenza.
- Decoder. Come l'encoder, anche un decoder è costruito utilizzando architetture RNN, LSTM o GRU. Genera la sequenza di output basandosi sul vettore di contesto.
- Meccanismo di attenzione (se utilizzato). Il meccanismo di attenzione è spesso implementato come parte del decoder, dove seleziona dinamicamente le parti rilevanti della sequenza di input durante il processo di decodifica per migliorare l'accuratezza.
1. Il ruolo dell'encoder
Il compito dell'encoder è comprendere e riassumere la sequenza di input, spesso mappando la sequenza in un embedding a dimensione fissa. Questi embedding aiutano a preservare le caratteristiche critiche, specialmente per compiti come la traduzione automatica dall'inglese al francese. L'encoder aggiorna il suo stato di contesto nascosto a ogni passo temporale per mantenere le dipendenze essenziali.
Equazione di aggiornamento dello stato nascosto dell'encoder:
ht=tanh(W_h*h_(t-1)+W_x*x_t+b_h)Dove:
- ht è lo stato nascosto al tempo t
- h_(t-1) è lo stato nascosto precedente
- x_t è l'input al tempo t
- W_h e W_x sono matrici di peso
- b_h è il termine di bias
- tanh è la funzione di attivazione
Punti chiave sull'encoder:
- Elabora gli input un elemento alla volta (ad esempio, parola per parola o carattere per carattere).
- A ogni passo, aggiorna lo stato interno dell'encoder basato sull'elemento corrente e sugli stati precedenti.
- Produce un vettore di contesto contenente le informazioni di cui il decoder ha bisogno per generare l'output.
2. Il ruolo del decoder
Il decoder inizia con il vettore di contesto dell'encoder e predice la sequenza di output un passo alla volta. Aggiorna il suo stato nascosto basato sullo stato precedente, il vettore di contesto e l'ultima parola predetta.
Equazione di aggiornamento dello stato nascosto del decoder:
st=tanh(W_s*s_(t-1)+ W_y*y_(t-1)+ W_c*c_t+b_s)Dove:
- st: Stato nascosto del decoder al tempo t
- s_(t-1): Stato nascosto precedente del decoder
- y_(t-1): Output precedente o token predetto
- c_t: Vettore di contesto (dall'output dell'encoder)
- W_s, W_y, W_c: Matrici di peso
- b_s: Termine di bias
- tanh: Funzione di attivazione
Punti chiave sul decoder:
- Il decoder genera l'output un passo alla volta, predicendo il prossimo elemento basato sul vettore di contesto e sulle predizioni precedenti.
- Continua fino a quando non emette un token unico (ad esempio, <END>) che segnala il completamento della sequenza.
3. Il meccanismo di attenzione
L'attenzione è un potenziamento potente spesso aggiunto ai modelli Seq2Seq, specialmente quando si gestiscono frasi più lunghe. Invece di fare affidamento esclusivamente su un vettore di contesto, l'attenzione consente al decoder di guardare a diverse parti della sequenza di input mentre genera ogni parola.
Seq2Seq con attenzione calcola i punteggi di attenzione per concentrarsi dinamicamente su diverse parti della sequenza di input durante la decodifica.
Formula del peso di attenzione:
α_ij = exp(e_ij) / Σ_k exp(e_ik)Dove:
- αij: Peso di attenzione per la query i e la chiave j
- e_ij: Punteggio di attenzione grezzo tra la query i e la chiave j
- exp: Funzione esponenziale
- Σ_k exp(e_ik): Somma dei punteggi esponenziali per tutte le chiavi k (termine di normalizzazione)
Questa operazione softmax assicura che i pesi di attenzione sommino a 1 su tutte le chiavi.
Perché l'attenzione è critica per i modelli Seq2Seq
L'aggiunta del meccanismo di attenzione ha reso Seq2Seq più robusto e scalabile. Ecco come:
- Migliore gestione delle sequenze lunghe: I vettori di contesto potrebbero avere difficoltà a mantenere tutte le informazioni rilevanti senza attenzione. Questo può portare a una scarsa qualità dell'output nei testi lunghi.
- Focus adattivo: L'attenzione consente al modello di regolare il focus su specifici elementi di input a ogni passo di decodifica, aiutando a creare traduzioni o sintesi più accurate.
- Fondamento dei transformer: L'attenzione è anche un concetto fondamentale nelle moderne architetture transformer come BERT, GPT e T5, che si basano sui modelli Seq2Seq per gestire compiti NLP ancora più complessi.
4. Addestramento del modello Seq2Seq
L'addestramento dei modelli Seq2Seq richiede un ampio dataset di sequenze accoppiate (ad esempio, coppie di frasi in due lingue). Il modello impara confrontando il suo output con la produzione corretta e regolando fino a minimizzare gli errori. Nel tempo, migliora nella trasformazione delle sequenze.
Vuoi saperne di più su Software di Elaborazione del Linguaggio Naturale (NLP)? Esplora i prodotti Elaborazione del Linguaggio Naturale (NLP).
Come implementare un modello Seq2Seq in PyTorch
PyTorch è un popolare framework di deep learning per implementare modelli Seq2Seq perché offre flessibilità e facilità d'uso.
Ecco una guida passo-passo per costruire un'architettura encoder-decoder in PyTorch che elabora dati sequenziali e produce output significativi.
Passo 1: Importa le librerie
Per definire e addestrare il modello, importa le librerie richieste, come PyTorch, NumPy e altre utilità.

Fonte: ChatGPT
Passo 2: Definisci gli iperparametri
Imposta i parametri chiave per il modello, inclusi la dimensione dell'input (numero di caratteristiche nell'input), la dimensione dell'output (caratteristiche nell'output), le dimensioni nascoste (dimensione degli strati nascosti) e il tasso di apprendimento (controlla la velocità di addestramento del modello).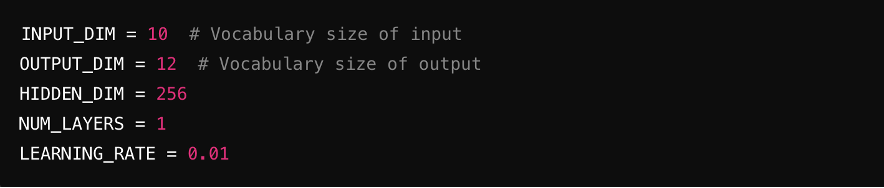
Fonte: ChatGPT
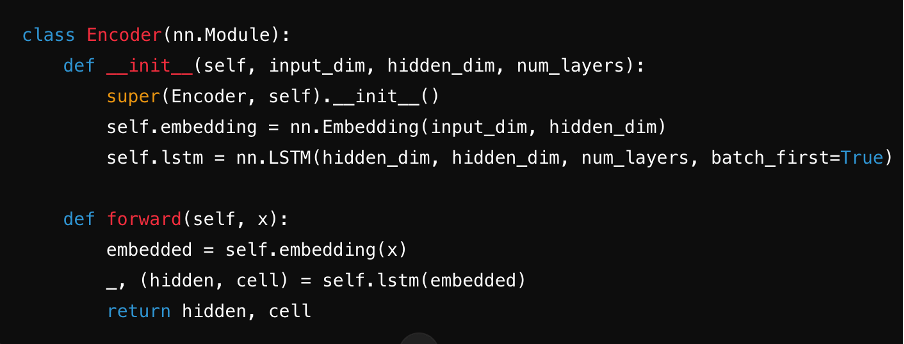
Passo 3: Definisci l'encoder
Crea l'encoder, tipicamente utilizzando un RNN, LSTM o GRU. Elabora la frase di input passo dopo passo, riassumendo le informazioni in un vettore di contesto memorizzato nel suo stato nascosto.
Fonte: ChatGPT
Passo 4: Definisci il decoder
Progetta il decoder, che genera la sequenza di output. Utilizza il vettore di contesto dall'encoder e i suoi stati nascosti per predire ogni output passo dopo passo.
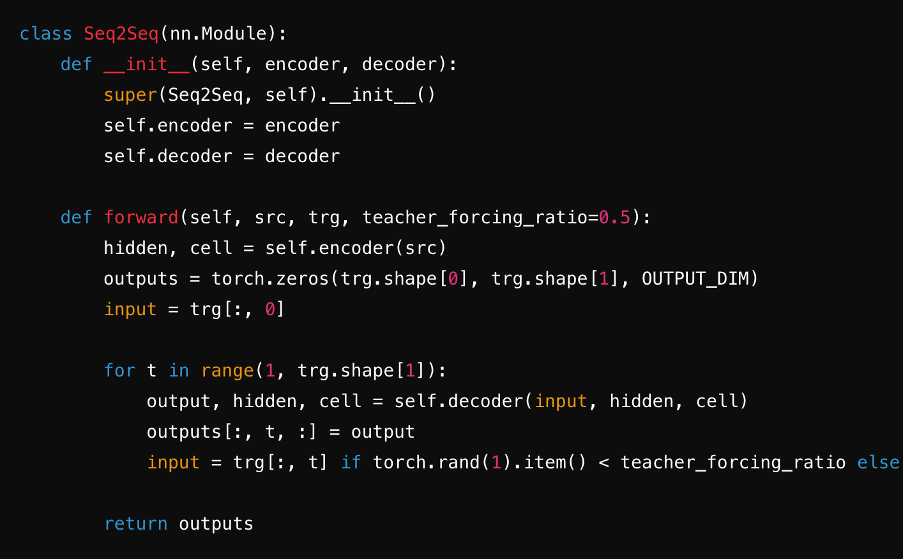
Passo 5: Combina in un modello Seq2Seq
Integra l'encoder e il decoder in un unico modello Seq2Seq. Durante questo passo, spesso utilizzerai strati lineari e funzioni softmax per generare predizioni per ogni passo temporale della sequenza target. Questo assicura un trasferimento senza soluzione di continuità del vettore di contesto, degli embedding e degli stati nascosti tra i componenti, ottimizzando l'efficienza del modello.
Fonte: ChatGPT
Passo 6: Addestra il modello
Implementa un ciclo di addestramento in cui il modello impara confrontando le sue predizioni con la verità a terra. Ottimizza i parametri utilizzando una funzione di perdita e un algoritmo come Adam o SGD. Itera attraverso le epoche, aggiornando i pesi per minimizzare la perdita e migliorare le prestazioni nel tempo.

Fonte: ChatGPT
Applicazioni chiave dei modelli Seq2Seq in NLP
Seq2Seq è un algoritmo di machine learning di punta per l'NLP grazie alla sua flessibilità e accuratezza nella gestione di compiti linguistici complessi. Utilizzando l'apprendimento sequenza-a-sequenza con reti neurali, questi modelli eccellono in applicazioni come:
- Traduzione linguistica. Seq2Seq eccelle nella traduzione di testi tra lingue. La loro capacità di catturare sfumature grammaticali e mantenere la fluidità li rende ideali per alimentare servizi come Google Translate.
- Sintesi del testo. Identificando e condensando le informazioni essenziali, i modelli Seq2Seq creano sintesi concise di articoli, rapporti o altri testi lunghi senza perdere significato.
- AI conversazionale e chatbot. I modelli Seq2Seq generano risposte naturali e consapevoli del contesto, il che li rende essenziali per chatbot, assistenti virtuali e sistemi di servizio clienti automatizzati. La loro capacità di produrre testo coerente e simile a quello umano è anche utile per risposte email automatizzate o generazione di storie.
- Adattabilità per dati di lunghezza variabile. La struttura encoder-decoder consente a Seq2Seq di gestire dati di lunghezza variabile, rendendolo adatto per compiti come risposte a domande o generazione di codice.
Vantaggi dei modelli Seq2Seq
I modelli sequence-to-sequence offrono una flessibilità e una precisione uniche. Esaminiamo i vantaggi chiave che rendono Seq2Seq uno strumento potente.
- Versatilità: I modelli Seq2Seq possono gestire compiti diversi come traduzione linguistica, sintesi, generazione di testo e altro. La loro architettura encoder-decoder li rende adattabili a varie sfide di dati sequenziali.
- Preservazione del contesto: Questi modelli mantengono il contesto delle sequenze di input, il che li rende particolarmente utili per compiti che coinvolgono frasi o paragrafi lunghi in cui il significato dipende dalle parti precedenti della sequenza.
- Accuratezza: Poiché i modelli Seq2Seq sono altamente scalabili e possono essere addestrati su grandi dataset, la loro accuratezza e affidabilità migliorano nel tempo.
- Robustezza ai dati rumorosi: Catturando efficacemente le dipendenze sequenziali, i modelli Seq2Seq mitigano gli errori derivanti da dati rumorosi o incompleti.
Svantaggi dei modelli Seq2Seq
Comprendere le limitazioni dei modelli Seq2Seq è cruciale per determinare quando e come implementarli efficacemente. Esploriamo alcuni dei potenziali svantaggi.
- Elevati requisiti computazionali: Implementare modelli Seq2Seq su dispositivi a bassa risorsa è difficile poiché richiedono molta memoria e capacità di elaborazione, particolarmente quando combinati con meccanismi di attenzione.
- Difficoltà nella gestione di sequenze molto lunghe: Anche con caratteristiche come l'attenzione, i modelli Seq2Seq possono avere difficoltà a elaborare sequenze di input prolungate. Questo può portare a perdita di contesto o scarse prestazioni in compiti che coinvolgono più dipendenze.
- Dipendenza da dati di addestramento estesi: Per addestrare efficacemente i modelli Seq2Seq, sono richiesti dataset grandi e di alta qualità. In assenza di dati affidabili o insufficienti, si possono ottenere output di scarsa qualità e risultati inaffidabili.
- Rischio di bias di esposizione: I modelli Seq2Seq sono guidati dalle risposte corrette (dati forzati dall'insegnante) durante l'addestramento. Tuttavia, il modello deve fare affidamento sulle sue predizioni durante l'uso effettivo. Se commette un errore all'inizio, gli errori possono accumularsi e influenzare l'output finale.
Il futuro dei modelli Seq2Seq nel linguaggio e nell'AI
I modelli Seq2Seq hanno un futuro promettente nel linguaggio e nell'AI, in particolare come elementi fondamentali per i moderni modelli linguistici come GPT e BERT.
Con i progressi nelle tecniche di embedding, l'addestramento adattivo con ottimizzazione del gradiente e la traduzione automatica neurale, Seq2Seq è pronto ad affrontare sfide NLP ancora più complesse.
- Espansione delle applicazioni: Seq2Seq probabilmente si espanderà in più aree, come il servizio clienti automatizzato, la scrittura creativa e chatbot avanzati, rendendo le interazioni più fluide e intuitive.
- Migliore gestione dei contesti complessi: Meccanismi di attenzione migliorati e innovazioni basate su transformer stanno aiutando i modelli Seq2Seq a comprendere sfumature linguistiche più profonde.
- Adattabilità alle lingue a bassa risorsa: Con più ricerca, i modelli Seq2Seq potrebbero essere in grado di supportare una gamma più ampia di lingue, comprese quelle con meno dati di addestramento.
- Integrazione con AI avanzata: Seq2Seq è fondamentale per i modelli più recenti come GPT e BERT, che continueranno a spingere i confini nell'elaborazione del linguaggio naturale.
Sbloccare nuovi orizzonti con i modelli Seq2Seq
I modelli Seq2Seq hanno rivoluzionato il modo in cui elaboriamo e comprendiamo il linguaggio nell'AI, offrendo versatilità e precisione senza pari. Dalla traduzione delle lingue senza soluzione di continuità alla generazione di testo simile a quello umano, sono la spina dorsale delle moderne applicazioni NLP.
Con i progressi come i meccanismi di attenzione e i transformer che evolvono, i modelli Seq2Seq diventeranno solo più potenti ed efficienti, affrontando sfide sempre più complesse nel linguaggio e nelle reti neurali. Che tu sia un appassionato di ML o un professionista esperto, esplorare Seq2Seq apre la porta alla creazione di soluzioni più innovative e consapevoli del contesto.
Il futuro dell'AI è sequenziale – sei pronto a entrarci?
Scopri le migliori soluzioni LLM per costruire e scalare i tuoi modelli di machine learning.

Chayanika Sen
Chayanika is a B2B Tech and SaaS content writer. She specializes in writing data-driven and actionable content in the form of articles, guides, and case studies. She's also a trained classical dancer and a passionate traveler.

