
I dati grezzi non hanno senso. Renderli pronti per il business richiede molto tempo, risorse e, naturalmente, caffè.
Gli scienziati dei dati gestiscono i dati in tre modi: gestione, analisi e visualizzazione. I modelli di machine learning (ML) sono una combinazione di tutti questi. Controlla i tuoi dati, ne testa l'usabilità e li converte nelle tue aspettative.
La necessità di modelli di machine learning sta esplodendo nelle industrie commerciali e non commerciali. L'ottimizzazione dei dati con software di intelligenza artificiale e operationalizzazione del machine learning è diventata il fulcro di tutte le operazioni di produzione. Dove la maggior parte delle aziende cerca di licenziare i clienti, i modelli di machine learning stanno portando a una grande rivoluzione basata sui dati.
Cosa sono i modelli di machine learning?
Un modello di machine learning è una rappresentazione grafica di dati del mondo reale. È programmato in un ambiente dati integrato e lavora su casi aziendali reali. Si allena su dati vecchi e lavora su dati freschi. Ci vuole tempo per programmare, testare e convalidare i modelli di machine learning prima di sfruttarli per prendere decisioni aziendali.
Le esperienze di machine learning e intelligenza artificiale (AI) risalgono al XX secolo. L'idea della "generazione di supercomputer" o "quinta generazione di computer" ha creato un'impennata tecnologica in un mondo di computer a vuoto.
Storia dei modelli di machine learning
La concezione iniziale del machine learning iniziò nel 1943 quando il logico Walter Pitts e il neuroscienziato Warren McCulloch costruirono un modello matematico di una rete neurale. Miravano a replicare il funzionamento del cervello umano. Un decennio dopo, il computer scientist Arthur Samuel coniò il termine "machine learning" e lo descrisse come "la capacità di un computer di apprendere senza essere esplicitamente programmato."
Il concetto nacque per la prima volta nel 1945, quando Joseph Weizenbaum scoprì l'elaborazione del linguaggio naturale (NLP) come un ramo dell'intelligenza artificiale. Lentamente, i concetti di machine learning più recenti sostituirono quelli più vecchi. Lentamente, con l'evoluzione dei big data, il machine learning incubò una forma più elevata di intelligenza informatica. Questa intelligenza era più accurata, focalizzata e leggera rispetto alle invenzioni precedenti.
Sebbene i modelli di machine learning non fossero al 100% accurati in termini di output, forniscono una previsione costante. L'accuratezza della previsione dipendeva anche dal tipo di dati di addestramento su cui lavorava. Questi modelli imparavano le somiglianze tra dati esterni e interni per trarre proiezioni.
Machine learning nel corso degli anni
- 1945: Il primo concetto di elaborazione del linguaggio naturale (NLP) fu creato da Joseph Weizenbaum
- 1949: The Organization of Behaviour, che parlava di reti neurali per la prima volta, pubblicato da Donald Hebb
- 1950: Invenzione del test di Turing, che fu condotto per verificare l'intelligenza e la fluidità dei computer.
- 1951: La calcolatrice di rinforzo analogica neurale stocastica (SNARC) macchina, il primo dispositivo concettuale basato su una rete neurale artificiale, fu creata.
- 1966: Progettazione di Shakey, il primo robot basato su AI
- 1967: Algoritmo K-nearest ideato
- 1979: Invenzione del Stanford Cart, un carrello telecomandato e auto-assistito
- 1986: Invenzione della macchina di Boltzmann ristretta (RBM)
- 1995: Lancio dell'algoritmo "random forest"
- 2006: Primo discorso sugli "algoritmi di deep learning" di Geoffrey Hinton
- 2009: Fei Fei Li sviluppò ImageNet, un database basato su immagini
- 2012: Introduzione di Google Brain, da parte di Google Inc.
- 2014: Riconoscimento facciale di Facebook, DeepFace, lanciato
- 2016: Vittoria di Alphago, alimentato da AI di Google, contro giocatori di strategia
- 2018: Invenzione di perceptroni multi-strato, reti generative avversarie e reti di apprendimento profondo q.
- 2020: Standardizzazione della realtà aumentata e realtà virtuale
- 2022: Internet delle cose, Edge 5G e ML automatizzato
Vuoi saperne di più su Software di Reti Neurali Artificiali? Esplora i prodotti Rete Neurale Artificiale.
Quando utilizzare i modelli di machine learning
I modelli di machine learning sono utilizzati per trarre intuizioni da dati già esistenti. Viene utilizzato per automatizzare le operazioni aziendali per stimolare la crescita. Tuttavia, alcuni problemi potrebbero non richiedere un approccio basato sui dati. Tali problemi non richiedono il machine learning e possono essere affrontati con calcoli matematici standard. Alcuni scenari idonei in cui il machine learning è indispensabile sono:
- Incapacità di regole: In luoghi in cui è necessario rilevare lo spam email, possono essere utilizzate applicazioni di machine learning come HoxHunt. Gli algoritmi di Hoxhunt prevedono potenziali opportunità di spam e ti impediscono di andare all'URL dannoso tramite un'email di spam. L'email di spam appare al 99% genuina e non può essere rilevata tramite semplici regole. Un robusto algoritmo di machine learning determina tutti i fattori di phishing e ferma l'utente.
- Incapacità di scala: Potresti riconoscere alcune email di phishing ma non tutte. Il phishing è una tecnica di hacking invisibile all'occhio non allenato. Fa apparire un'email genuina mentre memorizza i tuoi dettagli privati in un database nascosto. Un algoritmo ML gestisce e risolve questo problema su larga scala.
- Cybersecurity: Con i modelli di machine learning, le soluzioni software di cybersecurity possono analizzare modelli, individuare anomalie in grandi quantità di dati di log e trovare correlazioni. Questo previene attacchi alla sicurezza delle aziende.
Lo sapevi? Puoi valutare un modello di machine learning con cross-validation. Coinvolge l'addestramento del modello su dati di input e il test su dati di test complementari. Previene l'overfitting del modello e aiuta a trarre modelli simili per previsioni future.
Diversi tipi di modelli di machine learning
Esistono tre principali tipi di modelli di machine learning. Mentre tutte le tecniche di modellazione del machine learning lavorano per uno scopo comune, il loro modo di affrontare un problema di dati differisce.

Man mano che questi modelli vengono esposti a più campioni di dati e input, migliorano nell'apprendimento e nel calcolo dei valori previsti. I modelli sviluppano intelligenza con il tempo, l'apprendimento costante e la sperimentazione.
1. Apprendimento supervisionato
Nell' apprendimento supervisionato, il modello di machine learning viene insegnato con input predefiniti.
Il modello è dotato di segnali di input e output. Deve solo capire come arrivare a un valore di output. Il modello di machine learning attraversa il processo di addestramento, mappa le caratteristiche e le classifica per i dati in arrivo.
Successivamente, cerca di catturare il segnale di output più vicino mentre il valore di input viene memorizzato. Utilizza espressioni booleane per calcolare i valori dei dati. Gli scienziati dei dati o gli ingegneri ML addestrano questo modello con un dataset noto che comprende input e output. L'algoritmo deve elaborare una strategia di interpretazione da solo. Se si verifica una discrepanza, l'utente umano la corregge.
Il processo si ripete finché il modello non riceve un alto grado di accuratezza. Esempi di apprendimento supervisionato includono riconoscimento ottico dei caratteri, riconoscimento dei modelli e riconoscimento vocale.
2. Apprendimento non supervisionato
I modelli di machine learning non supervisionati identificano modelli nascosti nei dati per formare relazioni e trarre conclusioni. Elaborano dataset di input confrontandoli con informazioni memorizzate. Il tasso di accuratezza di un algoritmo non supervisionato cresce solo quando lavora con quanti più dati freschi possibile.
Esempio: Se l'apprendimento non supervisionato viene eseguito su un'immagine di cani e gatti, non può dire se l'immagine è di un cane o di un gatto perché i loro attributi fisici sono troppo simili. Non sarà in grado di distinguere le loro caratteristiche separate e restituirà un output confuso. L'accuratezza della classificazione del modello aumenta quando funziona su più immagini.
3. Apprendimento per rinforzo
Nell' apprendimento per rinforzo, l'algoritmo si comporta come un agente intelligente che apprende da ogni operazione non riuscita. Il modello si adatta dagli output errati e si sforza di raggiungere l'obiettivo finale. Un ciclo di feedback premia il modello con l'intelligenza acquisita quando l'output è corretto. Ma quando è errato, il modello impara dai suoi errori.
Ognuno di questi tre tipi di modelli di machine learning comprende diverse tecniche di creazione del modello. Diamo un'occhiata ai più popolari per ora.
Tipi di apprendimento supervisionato
Classificazione, regressione e previsione sono tecniche di analisi dei dati sotto l'apprendimento supervisionato.
Classificazione
Nelle attività di classificazione, la modellazione ml aiuta ad assegnare una categoria ai dati. Devono trarre conclusioni dai valori osservati per classificare l'output. Ad esempio, quando si classifica i dati dei pazienti come "nuovi" o "vecchi", un modello ML dovrebbe esaminare le date di registrazione esistenti per raggruppare i dati.
I due tipi di algoritmi di classificazione sono classificazione binaria e classificazione multi-classe. I classificatori binari restituiscono l'output come sì/no o vero/ falso. Sono responsabili solo di verificare se una particolare classe di dati è presente o meno. D'altra parte, se il problema ha più di due possibili risultati, si parla di problema di classificazione multi-classe.
Regressione
La regressione è un metodo di machine learning focalizzato su una variabile dipendente per una serie di variabili di output. L' analisi di un algoritmo di regressione rende le previsioni accurate e utili. Attraversa una serie di passaggi come la direzionalità dei dati, l'analisi della varianza (ANOVA), il test delle ipotesi e la creazione finale del modello.
I modelli di machine learning risolvono sette tipi di problemi di regressione:
-
Regressione lineare è una tecnica di analisi dei dati che analizza la relazione tra variabili di input e output. Ci possono essere più modelli di regressione lineare per un problema. Aiuta a correlare meglio i dati e a creare una relazione variabile a variabile, come l'impatto della pressione atmosferica sul cambiamento topografico.
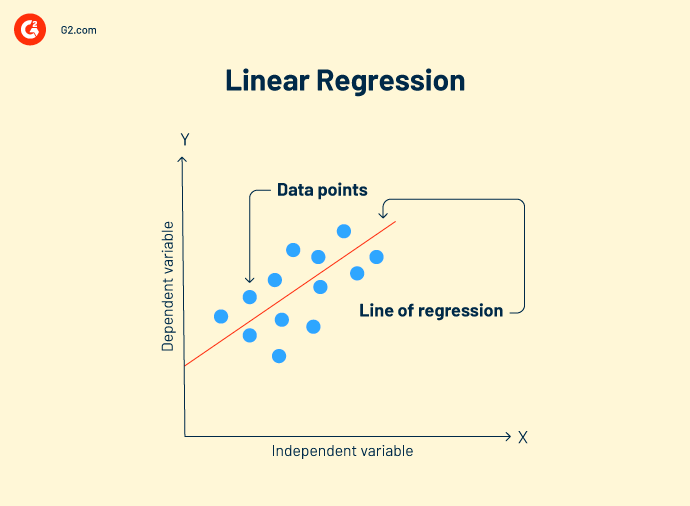
Formula della regressione lineare:
Y = mx+c+e
Y = valore previsto
m = variabile dipendente
c = costante
e = residuo di errore
L'obiettivo della regressione lineare è trovare un modello di buon adattamento che mostri previsioni accurate sui dati di test.
-
Regressione logistica lavora su dati categorici. Il suo concetto di funzionamento è simile alla regressione lineare. Stabilisce una relazione tra variabili dipendenti e indipendenti per calcolare le variabili previste. Tuttavia, la variabile di output può avere solo due valori, sì o no.
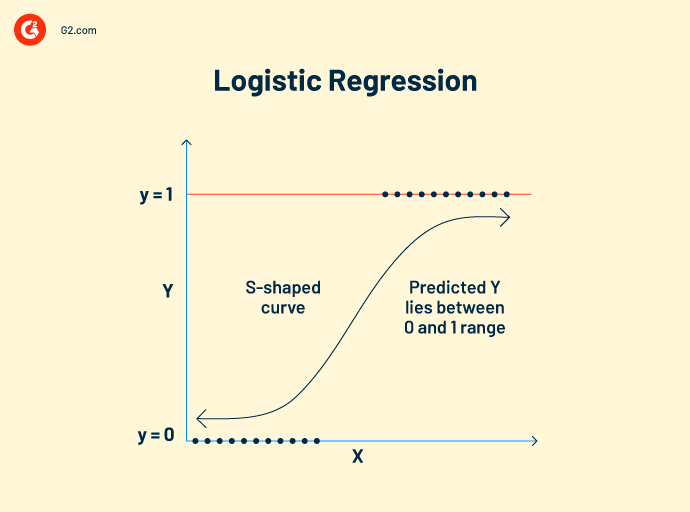
Il modello di regressione logistica prevede valori booleani come 0 e 1 o vero e falso. Ciò lo rende popolare come algoritmo di visione artificiale per rilevare la presenza di ostacoli esterni.
Formula della regressione logistica:
Questa formula è denotata dalla funzione logit, che misura la relazione tra la variabile target e le variabili indipendenti.
Logit (p) = In(p/(1-p)) = b0+b1X2+b2X2……+bkXk
p = probabilità di una caratteristica
-
Alberi decisionali o flussi di lavoro decisionali raggruppano insieme tutti i possibili risultati di un evento in una struttura ad albero. L'albero ha nodi definiti, rami e trigger di eventi. Ogni nodo interno è una rappresentazione dei dati di test. I dati di test vengono eseguiti sui nodi interni per prevedere i risultati.
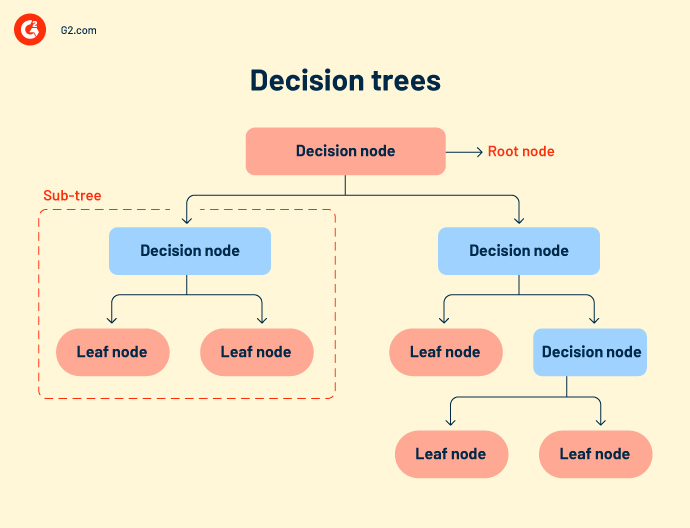
Anche se gli alberi decisionali sono semplici e intuitivi, mancano di accuratezza. Poiché comprende molti nodi, a volte il sistema si confonde durante il calcolo dell'output.
Gli alberi decisionali sono principalmente utilizzati nella ricerca e sviluppo di prodotti, analisi operativa e pianificazione finanziaria strategica. - Random forest si riferisce a un gran numero di alberi decisionali che sono raggruppati insieme. Ogni nodo dell'albero prevede la presenza di una categoria attraverso un aggregatore di voti. Se la maggior parte dei nodi vota per lo stesso output, quell'output viene scelto. Random forest è più complesso di altri algoritmi di regressione. Può essere utilizzato sia per la classificazione che per le correlazioni.
- K-nearest neighbors (KNN) è uno degli algoritmi di apprendimento più semplici. Classifica i tuoi dati in base ai punti dati più vicini di una categoria. L'algoritmo KNN presume che i nuovi dati provengano dallo stesso background dei vecchi dati e processa rapidamente l'output.
- Classificatori Naive Bayes si basano sul teorema di Bayes. È un classificatore probabilistico che accerta la probabilità di una classe ai dati. È uno dei modelli ML più nuovi, veloci e accurati. I team di dati lo utilizzano per condurre analisi dei consumatori, analisi sentimentale e classificazione degli articoli.
- Support Vector Machine (SVM) è un modello di classificazione e regressione utilizzato principalmente per riconoscimento delle immagini o riconoscimento degli oggetti. Le mappe delle caratteristiche estratte dal modello principale e la posizione dei dati vengono fornite a un classificatore SVM, che combina questi dati per prevedere la categoria richiesta.
3. Previsione
La previsione è una metodologia basata sulle tendenze che prevede il futuro con dati attuali o passati. È principalmente utilizzata per estrapolare le tendenze aziendali attuali e il potenziale di mercato per le aziende che prendono decisioni di investimento. Il metodo di previsione più prominente è la previsione delle serie temporali.
La previsione delle serie temporali è un metodo di analisi dei dati per fare previsioni scientifiche. Coinvolge la costruzione di modelli attraverso l'analisi dei dati storici su un periodo di tempo specifico. Esempi includono la previsione del tempo, la previsione di disastri naturali e la previsione di epidemie. L'accuratezza della previsione delle serie temporali è certa poiché lavora su dati probatori.
Gli esempi includono XGboost, levigatura esponenziale, autoregressivo e DeepAR.
Tipi di apprendimento non supervisionato
Gli scienziati dei dati o gli ingegneri ML utilizzano l'apprendimento non supervisionato per costruire modelli di machine learning auto-assistiti. Questi modelli apprendono e migliorano da soli, senza legami di dati esterni.
Clustering
Il clustering è il processo di divisione dei dati di input in cesti di categorie simili per ulteriori classificazioni. Due metodi efficaci di clustering sono i più adatti per i tuoi dati.
-
Clustering esclusivo: Questo metodo mette punti dati simili in gruppi definiti. I cluster di dati sono mutuamente esclusivi. Ad esempio, tutti gli stati del Nord America saranno collocati in un cluster e il Sud America in un altro. I cluster non si sovrapporranno in nessuna fase del processo di analisi.
- Clustering gerarchico: Conosciuto anche come clustering dal basso verso l'alto, questo è un modo più raffinato e organizzato per raggruppare i tuoi dati. L'algoritmo tratta ogni dataset come un singolo cluster e li unisce in un unico superset. Durante il clustering dei dati, puoi scegliere tra clustering agglomerativo o clustering divisivo.
Campionamento casuale
Il campionamento casuale è un metodo di interpretazione statistica che crea campioni casuali di dati. Raggruppa i dati in diversi cluster in base alla loro natura, tipo e comportamento. Viene utilizzato per calcolare il censimento, l'offerta e la domanda di prodotti e la raccolta delle entrate in aree particolari. Il campionamento casuale è simile al clustering ma non è affidabile in termini di accuratezza.
Apprendimento delle regole associative
L'apprendimento delle regole associative impone certe regole per la classificazione dei dati. Crea relazioni e modelli interessanti tra i dati e mappa le co-dipendenze in un modo che genera il massimo profitto. Esempi sono data mining o analisi del carrello della spesa.
Riduzione della dimensionalità
Questa tecnica elimina dati sporchi, outlier e valori irregolari, rendendo il dataset di input più pulito e nitido. Esempi includono l'analisi delle componenti principali o il clustering K-means.
Apprendimento profondo
L'apprendimento profondo richiede grandi dataset e alta potenza di calcolo grafico (GPU) per prevedere la classe delle variabili di input. Coinvolge reti neurali che sono composte da funzioni di attivazione e nodi di trigger. La rete accetta input attraverso il livello di input, attiva i nodi decisionali attraverso la funzione di attivazione e elabora l'output. I modelli più significativi sono:
- Autoencoder
- Macchina di Boltzmann
- o Reti neurali convoluzionali
- o Perceptrone multi-strato
- o Reti neurali ricorrenti
Tipi di apprendimento per rinforzo
Errare è umano. Errare è anche delle macchine.
L'apprendimento per rinforzo nomina un agente intelligente per lavorare sui dati. Queste azioni intelligenti agiscono in un ambiente di machine learning per prevedere risultati corretti. Se l'apprendimento per rinforzo prevede un output corretto, ottiene un premio cumulativo. È uno dei tre paradigmi ML di base dell'apprendimento per rinforzo.
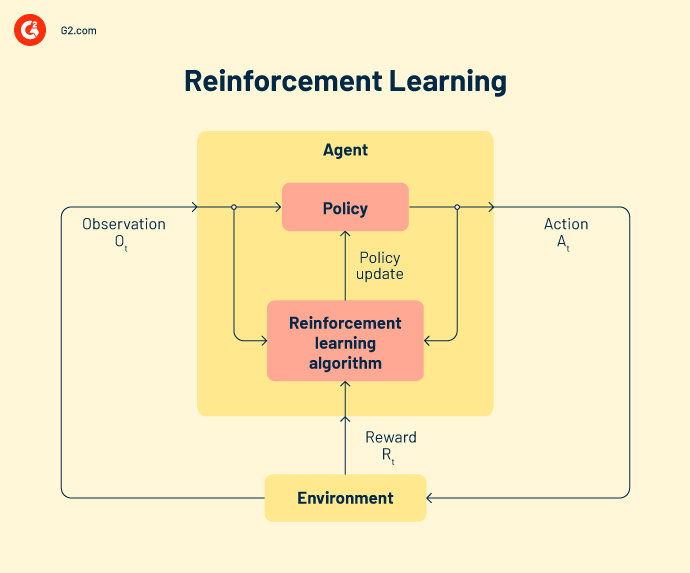
Alcuni modelli di rinforzo popolari includono.
Q-learning è un algoritmo di rinforzo popolare che aiuta gli agenti AI a prendere decisioni sagge. Con questo algoritmo, puoi calcolare il valore q, intraprendere l'azione richiesta e massimizzare i punti premio.
State-action-reward-state-action (SARSA) è un algoritmo on-policy che calcola il valore q per ogni coppia stato-azione. Per ogni stato specifico dell'input, c'è un output designato e un premio designato nel caso in cui l'output sia accurato. Ogni lettera in SARSA rappresenta una riga.
Una rete Q. profonda, o rete neurale Q. profonda, è una rete neurale artificiale che ha molti strati computazionali. Elabora l'output in base all'input, ai pesi e al bias aggiunto.
Diversi modelli di machine learning hanno diverse utilità e raggiungono diversi set di obiettivi. Devi scegliere quale modello funzionerà meglio per te a lungo termine.
Algoritmo vs. modello di machine learning vs. modello di deep learning
Indipendentemente dall'approccio, il risultato finale è sempre un modello che agisce sui dati. Apprendimento profondo. Machine learning o algoritmo è il secondo nome della gestione dei dati, come potrebbe attestare il tuo scienziato dei dati.
-png.png)
Gli algoritmi sono un insieme di espressioni di programmazione che sono autoesplicative. Eseguono un filo di comandi sui dati di input. Un algoritmo di machine learning è codificato in strumenti open-source come Python, Java o TensorFlow. Devi chiamare un pacchetto specifico dalla libreria dei pacchetti e installare le sue directory. Dopo di che, puoi caricare i tuoi dataset, impostare l'asse e creare modelli. Alcuni pacchetti sono Scikit learn, NumPy o Matplotlib.
Il modello di machine learning è la creazione finale di un algoritmo di dati. I modelli sono categorizzati come distorti, normali o di buon adattamento. Le proprietà dei dati e l'accuratezza dell'algoritmo sono i principali contributori a un modello di machine learning. Il modello viene distribuito sui dati di test e esteso nelle applicazioni del flusso di lavoro di un'organizzazione.
Il modello di deep learning è un passo avanti rispetto ai modelli di machine learning. Questi modelli sono addestrati per estrarre e memorizzare caratteristiche individuali dai dati e poi usarle per fare previsioni accurate. Tuttavia, questi sistemi di calcolo necessitano di grandi dataset, set di immagini e alta potenza di calcolo grafico (GPU). Esempi sono la rete neurale convoluzionale (CNN), la rete neurale convoluzionale ricorrente (R-CNN) e "you only look once" (YOLO).
Comprendere le tecnicalità dei dati può essere molto complicato. E molta complicazione risiede in come scegli i tuoi modelli ML.
Suggerimento: Puoi utilizzare il machine learning come servizio (MLaaS) per esternalizzare i processi di machine learning per i flussi di lavoro della tua azienda. Questo servizio è una raccolta di diversi software basati su cloud che distribuiscono strumenti di machine learning per fornire soluzioni di analisi predittiva ai tuoi team ML per vari casi d'uso aziendali.
Come scegliere il miglior modello di machine learning per la tua azienda
Per trovare il miglior modello, dai un'occhiata approfondita alla tua infrastruttura IT esistente. La tua attuale rete on-premise aprirà la strada alla compatibilità futura di hardware e software. Considera il tuo budget, la larghezza di banda, la rete locale (LAN), la larghezza di banda degli scienziati dei dati e altre politiche di manutenzione delle strutture per far funzionare i tuoi modelli di machine learning in tandem.
Un modo sicuro è iniziare in piccolo. Costruisci un framework di proof-of-concept e valuta la tua maturità AI. Utilizza attributi di dati esistenti, volume, caratteristiche e complessità per costruire un modello di machine learning intermedio. Validalo e testalo per piccoli progetti e casi d'uso aziendali. Quando il tuo modello si integra con i dati, distribuiscilo su scala più ampia.
Man mano che progredisci, conta su più larghezza di banda del team, budget e sforzi degli scienziati dei dati. Molto sforzo va nella gestione, nell'addestramento e nella diagnosi dei modelli ML, che possono intaccare le risorse della tua azienda.
Lo sapevi? Il mercato globale dell'intelligenza artificiale è stato valutato a 93,5 miliardi di dollari nel 2021 ed è previsto che si espanda a un tasso di crescita annuale composto del 38,1% dal 2022 al 2030.
Fonte: Grand View Research
Mentre il modello di machine learning rappresenta i tuoi dati matematicamente, non entra in azione da solo.
I tuoi dati sono la tua pista di decollo
Il machine learning è il presente, ma illumina anche la strada verso un futuro digitale. Raccogli una grande quantità di ricerca, studia i processi esistenti e decidi quale opzione ti metterà in prima linea nel mercato del software.
Scopri come puoi scegliere il modello corretto di data science e machine learning per la tua azienda.

Shreya Mattoo
Shreya Mattoo is a former Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

