
Quando hai bisogno di una risposta e ne hai bisogno in fretta, non sarebbe bello chiedere a tutti nel mondo che potrebbero aiutarti a trovare una risposta?
Sebbene sì, sarebbe fantastico, richiederebbe probabilmente un tempo osceno e sarebbe piuttosto costoso. Invece, è meglio raccogliere i tuoi dati chiedendo a un numero selezionato di persone con le informazioni di cui hai bisogno.
Questo metodo è noto come campionamento dei dati.
Per un aiuto con il campionamento dei dati, usa software di analisi statistica, che può non solo assistere nella determinazione di una dimensione del campione e nell'analisi dei dati, ma anche nel formulare varie conclusioni e ipotesi una volta completato il campionamento.
Cos'è il campionamento dei dati?
Il campionamento dei dati è una tecnica statistica comune per analizzare modelli e tendenze in un sottoinsieme di dati rappresentativo di un set di dati più ampio in esame. Utilizzando campioni rappresentativi, i data scientist e gli analisti possono rapidamente costruire modelli mantenendo l'accuratezza e decidendo la quantità e la frequenza della raccolta dei dati.
Il campionamento dei dati è una forma complessa di analisi statistica che può andare molto male se non eseguita correttamente. Può anche richiedere una ricerca approfondita prima che il campionamento possa iniziare.
Tipi di campionamento
Vari metodi di campionamento possono essere utilizzati per estrarre campioni dai dati, con l'approccio più efficace che dipende dal dataset e dal contesto. Questi metodi di campionamento dei dati sono generalmente classificati come campionamento probabilistico e campionamento non probabilistico.
Campionamento probabilistico
Nel campionamento probabilistico, ogni aspetto della popolazione ha un'uguale possibilità di essere selezionato per essere studiato e analizzato. Questi metodi tipicamente offrono la migliore possibilità di creare un campione il più rappresentativo possibile.
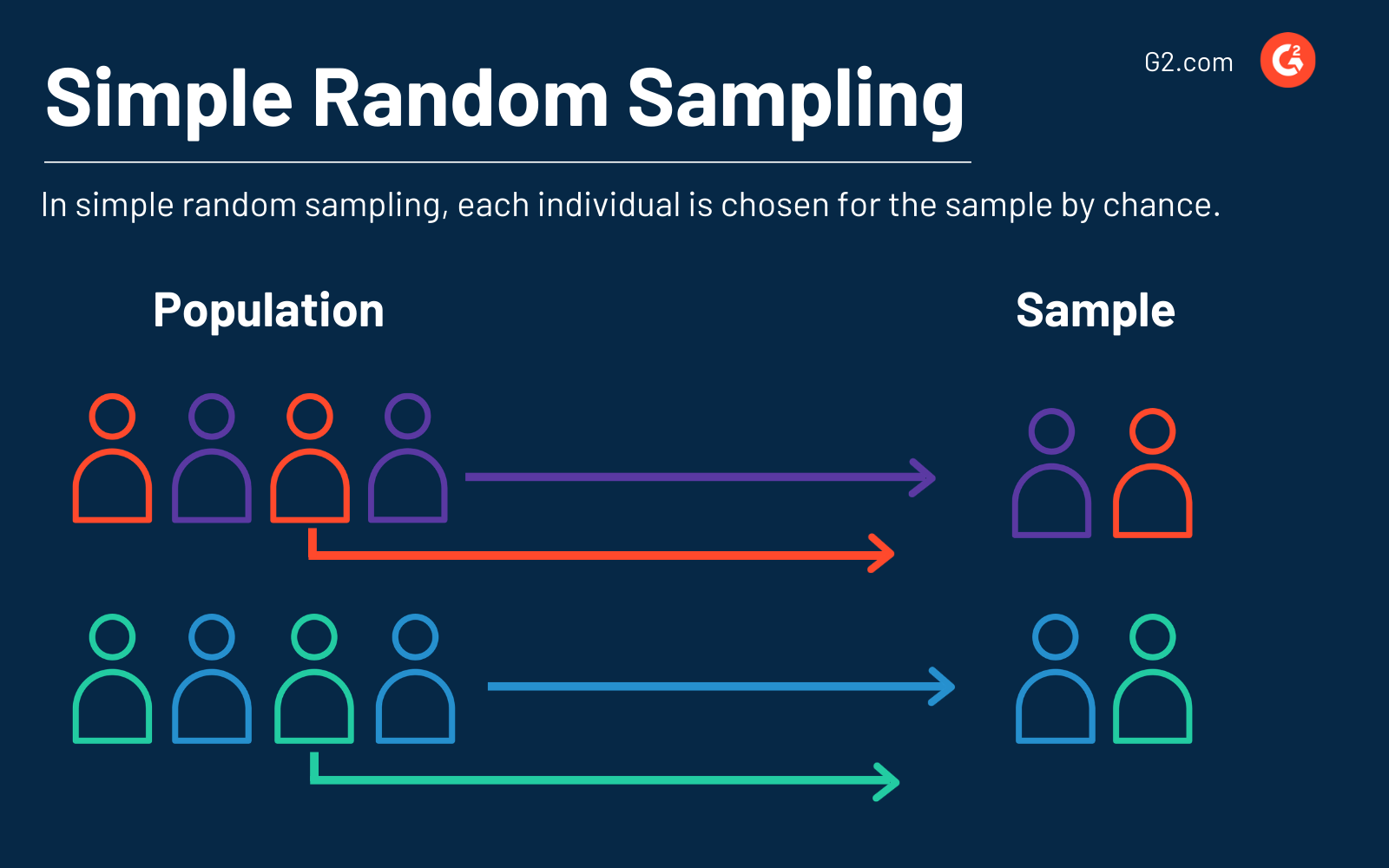
1. Campionamento casuale semplice
Come suggerisce il nome, il metodo semplice di campionamento dei dati è casuale. Ogni individuo è scelto per caso, e ogni membro della popolazione o gruppo ha un'uguale possibilità di essere selezionato.
Coloro che seguono questa strada possono persino utilizzare software per scegliere casualmente poiché viene utilizzato quando non ci sono informazioni preliminari sulla popolazione target.
Ad esempio, supponiamo che la tua azienda abbia un team di marketing di 50 persone e ne abbia bisogno di 10 per un nuovo progetto in procinto di essere lanciato. Ogni membro del team ha un'uguale possibilità di essere selezionato, con una probabilità del 5%.
Un vantaggio dell'utilizzo del campionamento casuale semplice è che è il modo più diretto per eseguire il campionamento probabilistico. D'altra parte, coloro che utilizzano il campionamento casuale semplice possono scoprire che i selezionati non hanno le caratteristiche che vogliono studiare.
2. Campionamento sistematico
Il campionamento sistematico è un po' più complicato. In questo metodo, il primo individuo è selezionato casualmente, mentre gli altri sono selezionati utilizzando un "intervallo di campionamento fisso". Pertanto, un campione è creato impostando un intervallo che deriva dati dalla popolazione più ampia.
Un esempio di campionamento sistematico dei dati sarebbe scegliere il primo individuo casualmente e poi scegliere ogni terza persona per il campione.
Alcuni chiari vantaggi dell'utilizzo del campionamento sistematico sono che è facile da eseguire e comprendere, hai il pieno controllo del processo e c'è un basso rischio di contaminazione dei dati.

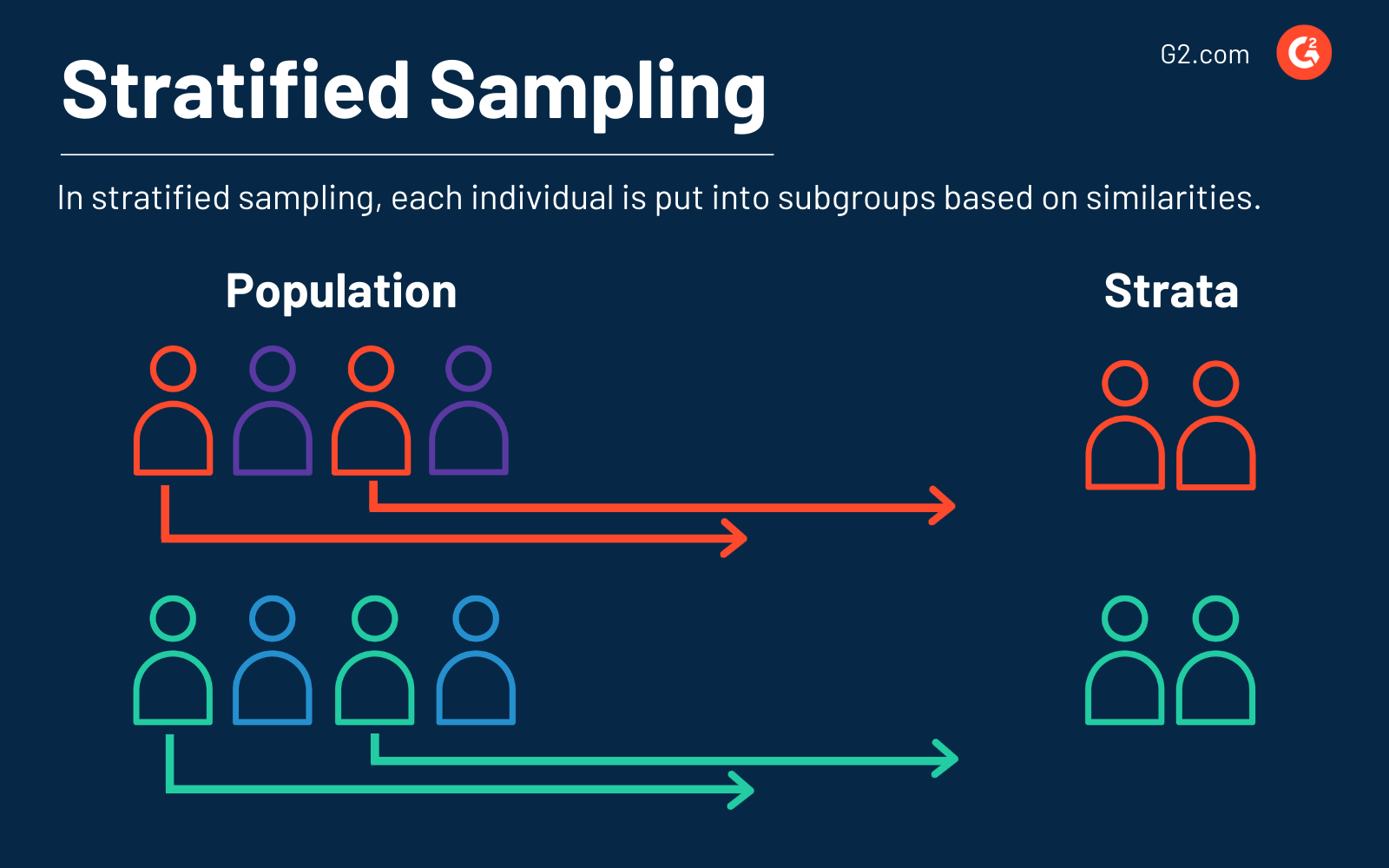
3. Campionamento stratificato
Il campionamento stratificato è un metodo in cui gli elementi della popolazione sono divisi in piccoli sottogruppi, chiamati strati, basati sulle loro somiglianze o un fattore comune. I campioni sono poi raccolti casualmente da ciascun sottogruppo.
Questo metodo richiede informazioni preliminari sulla popolazione per determinare il fattore comune prima di creare gli strati. Queste somiglianze possono essere qualsiasi cosa, dal colore dei capelli all'anno in cui si sono laureati, al tipo di cane che possiedono e alle allergie alimentari.
Un vantaggio del campionamento stratificato è che questo metodo può fornire una maggiore precisione rispetto ad altri metodi. Per questo motivo, puoi scegliere di testare un campione più piccolo.
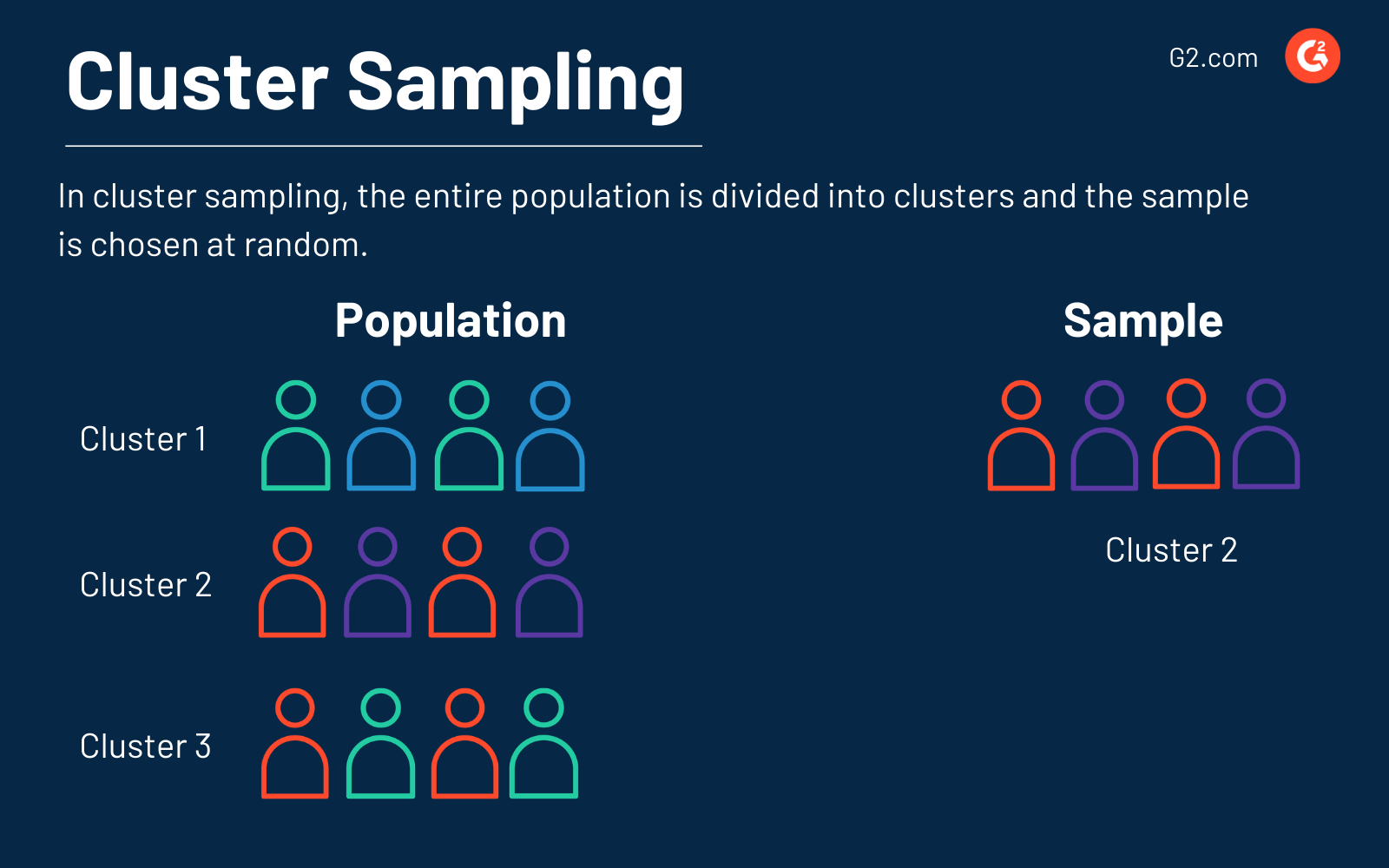
4. Campionamento a grappolo
Il metodo di clustering divide l'intera popolazione o un grande set di dati in cluster o sezioni basate su un fattore definito. Poi, i cluster sono selezionati casualmente per essere inclusi nel campione e analizzati.
Supponiamo che ogni cluster sia basato sul quartiere di Chicago in cui vivono gli individui. Questi individui sono raggruppati per Wrigleyville, Lincoln Park, River North, Wicker Park, Lakeview e Fulton Market. Poi, il campione di individui è scelto casualmente per essere rappresentato da quelli che vivono a Wicker Park.
Questo metodo di campionamento è anche rapido e meno costoso e consente di studiare un grande campione di dati. Il campionamento a grappolo, progettato specificamente per grandi popolazioni, può anche consentire molti punti dati da un'intera demografia o comunità.
5. Campionamento a più stadi
Il campionamento a più stadi è una forma più complicata di campionamento a grappolo. Essenzialmente, questo metodo divide la popolazione più ampia in molti cluster. I cluster di secondo stadio sono poi ulteriormente suddivisi in base a un fattore secondario. Poi, quei cluster sono campionati e analizzati.
La "messa in scena" nel campionamento a più stadi continua mentre vengono identificati, raggruppati e analizzati più sottogruppi.
Campionamento non probabilistico
I metodi di campionamento dei dati nella categoria non probabilistica hanno elementi che non hanno un'uguale possibilità di essere selezionati per essere inclusi nel campione, il che significa che non si basano sulla randomizzazione. Queste tecniche si basano sulla capacità del data scientist, dell'analista dei dati o di chiunque stia selezionando di scegliere gli elementi per un campione.
Per questo motivo, questi metodi rischiano di produrre un campione non rappresentativo, che è un gruppo che non rappresenta veramente il campione. Questo potrebbe risultare in una conclusione generalizzata.
1. Campionamento di convenienza
Nel campionamento di convenienza, a volte chiamato campionamento accidentale o di disponibilità, i dati sono raccolti da un gruppo facilmente accessibile e disponibile. Gli individui sono selezionati in base alla loro disponibilità e volontà di partecipare al campione.
Questo metodo di campionamento dei dati è tipicamente utilizzato quando la disponibilità di un campione è rara e costosa. È anche soggetto a bias poiché il campione potrebbe non sempre rappresentare le caratteristiche specifiche necessarie per essere studiate.
Torniamo all'esempio che abbiamo usato per il campionamento casuale semplice. Hai ancora bisogno di 10 membri del team di marketing per assistere a un progetto specifico. Invece di selezionare casualmente i membri del team, selezioni i 10 che sono più disposti ad aiutare.
Questo metodo ha il vantaggio di essere facile da eseguire a un costo relativamente basso in modo tempestivo. Consente anche di raccogliere dati e informazioni utili da un elenco meno formale, come i metodi utilizzati nel campionamento probabilistico. Il campionamento di convenienza è il metodo preferito per studi pilota e generazione di ipotesi.
2. Campionamento a quote
Quando il metodo delle quote è utilizzato nel campionamento dei dati, gli elementi sono scelti in base a caratteristiche predeterminate. Il ricercatore di campionamento dei dati garantisce un'uguale rappresentazione all'interno del campione per tutti i sottogruppi all'interno del set di dati o della popolazione.
Il campionamento a quote dipende dallo standard preimpostato. Ad esempio, la popolazione in analisi è composta per il 75% da donne e per il 25% da uomini. Poiché il campione dovrebbe riflettere la stessa percentuale di donne e uomini, solo il 25% delle donne sarà scelto per essere nel campione per corrispondere al 25% degli uomini.
Il campionamento a quote è ideale per coloro che considerano le proporzioni della popolazione rimanendo convenienti in termini di costi. Una volta determinati i caratteri, il campionamento a quote è anche facile da amministrare.
3. Campionamento per giudizio
Il campionamento per giudizio, noto anche come campionamento selettivo, si basa sulla valutazione degli esperti nel campo quando si sceglie chi chiedere di essere incluso nel campione.
In questo caso, supponiamo che tu stia selezionando da un gruppo di donne di età compresa tra 30 e 35 anni, e gli esperti decidono che solo le donne con una laurea saranno le più adatte per essere incluse nel campione. Questo sarebbe il campionamento per giudizio.
Il campionamento per giudizio richiede meno tempo rispetto ad altri metodi, e poiché c'è un set di dati più piccolo, i ricercatori dovrebbero condurre interviste e altre tecniche di raccolta diretta per garantire il giusto tipo di gruppo di discussione. Poiché il campionamento per giudizio significa che i ricercatori possono andare direttamente alla popolazione target, c'è una maggiore rilevanza dell'intero campione.
4. Campionamento a palla di neve
Il campionamento a palla di neve, a volte chiamato campionamento per referral o campionamento a catena di referral, è utilizzato quando la popolazione è rara e sconosciuta.
Questo è tipicamente fatto selezionando uno o un piccolo gruppo di individui in base a criteri specifici. La persona o le persone selezionate sono poi utilizzate per trovare più individui da analizzare.
Considera una situazione o un argomento altamente sensibile, come contrarre una malattia contagiosa. Questi individui potrebbero non discutere apertamente della loro situazione o partecipare a sondaggi per condividere informazioni riguardanti la malattia.
Poiché non tutte le persone con questa malattia risponderanno alle domande poste, il ricercatore può scegliere di contattare persone che conosce, o coloro che hanno la malattia possono contattare altri che conoscono che la hanno per raccogliere le informazioni necessarie.
Questo metodo è chiamato a palla di neve perché, poiché le persone esistenti sono invitate a nominare persone per essere nel campione, lo stesso aumenta di dimensioni come una palla di neve rotolante.
Il campionamento a palla di neve consente a un ricercatore di raggiungere una popolazione specifica che sarebbe difficile da campionare utilizzando altri metodi mantenendo bassi i costi. A causa della dimensione del campione più piccola, richiede anche poca pianificazione e una forza lavoro più piccola.
Riesame dei dati
Una volta che hai un campione di dati, questo può essere utilizzato per stimare la popolazione. Tuttavia, poiché questo ti dà solo una stima singola, non c'è variabilità o certezza nella stima. Per questo motivo, alcuni ricercatori stimano la popolazione più volte da un campione di dati, che è chiamato riesame dei dati.
Ogni nuova stima è chiamata sottocampione poiché proviene dal campione di dati originale. Ogni campione che stima la popolazione dal riesame è il proprio strumento statistico per quantificare la sua accuratezza.
Vuoi saperne di più su Strumenti di Visualizzazione dei Dati? Esplora i prodotti Visualizzazione dei dati.
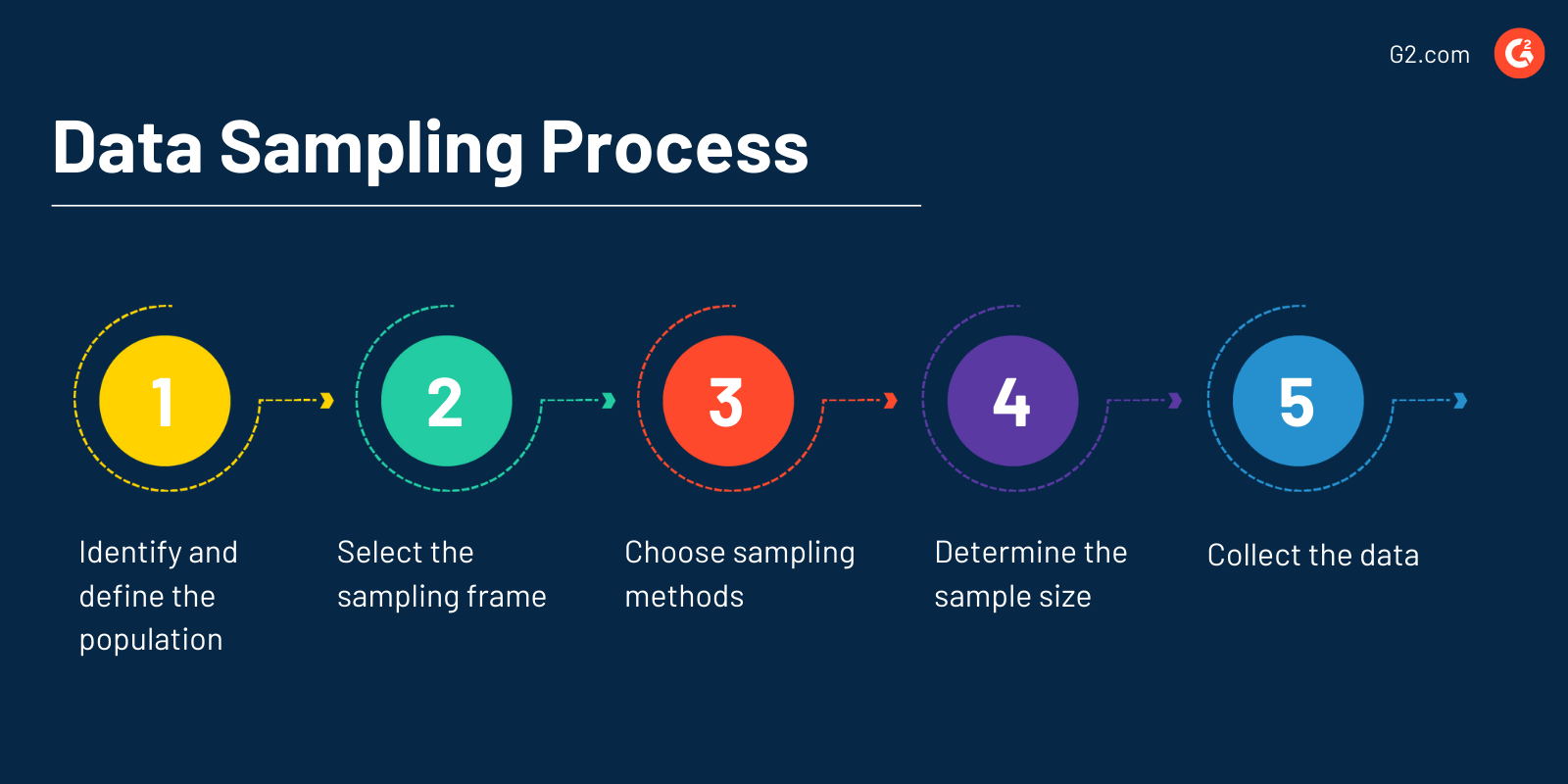
Processo di campionamento dei dati
Il processo complessivo di campionamento dei dati è un metodo di analisi statistica che aiuta a trarre conclusioni sulle popolazioni dai campioni.
Il primo passo nel campionamento dei dati è identificare e definire la popolazione che vuoi analizzare. Questo può essere fatto conducendo sondaggi, sondaggi d'opinione, osservazioni, gruppi di discussione, questionari o interviste.
Questo passo può anche essere chiamato raccolta dati. I parametri devono essere impostati, sia che si decida di sondare solo donne tra i 18 e i 35 anni o uomini che si sono laureati nel 2010 nello stato del Vermont.
Successivamente, seleziona il quadro di campionamento, che è l'elenco di elementi o persone che formano una popolazione da cui viene preso il campione. Ad esempio, un quadro di campionamento potrebbe essere i nomi delle persone che vivono in una città specifica per un sondaggio sulla dimensione della famiglia in quella città.
Quindi, sarà scelto un metodo di campionamento. A seconda delle caratteristiche del dataset e degli obiettivi di ricerca, puoi scegliere uno qualsiasi dei metodi di campionamento dei dati menzionati nella sezione precedente.
Il quarto passo è determinare la dimensione del campione da analizzare. Nel campionamento dei dati, la dimensione del campione è il numero esatto di campioni che saranno misurati per fare un'osservazione.
Supponiamo che la tua popolazione sarà composta da uomini che si sono laureati nel 2010 nello stato del Vermont, e quel numero è 40.000, allora la dimensione del campione sarà 40.000. Più grande è la dimensione del campione, più accurata sarà la conclusione.
Infine, è il momento di raccogliere dati dal campione. In base ai dati, prenderai una decisione, una conclusione o un piano d'azione.
Errori comuni nel campionamento dei dati
Quando si campionano i dati, coloro che sono coinvolti devono trarre conclusioni statistiche sulla popolazione da una serie di osservazioni.
Poiché queste osservazioni spesso provengono da stime o generalizzazioni, è probabile che si verifichino errori. I tre principali tipi di errori che si verificano durante il campionamento dei dati sono:
- Bias di selezione: Il bias che viene introdotto dalla selezione di individui per far parte del campione che non è casuale. Pertanto, il campione non può rappresentare la popolazione che si desidera analizzare.
-
Errore di campionamento: L'errore statistico che si verifica quando il ricercatore non seleziona un campione che rappresenta l'intera popolazione di dati. Quando ciò accade, i risultati trovati nel campione non rappresentano i risultati che sarebbero stati ottenuti dall'intera popolazione.
L'unico modo per eliminare al 100% la possibilità di un errore di campionamento è testare il 100% della popolazione. Ovviamente, questo è di solito impossibile. Tuttavia, più grande è la dimensione del campione nei tuoi dati, meno estremo sarà il margine di errore.
- Errore di non risposta: Questo errore si verifica quando gli individui selezionati non partecipano a un sondaggio o studio. Deriva da fattori come mancanza di interesse, difficoltà nel raggiungere i partecipanti o affaticamento da sondaggio e influisce sull'accuratezza dei dati raccolti.
Vantaggi del campionamento dei dati
C'è un motivo per cui il campionamento dei dati è così popolare, poiché ci sono molti vantaggi.
Per cominciare, è utile quando il set di dati che deve essere esaminato è troppo grande per essere analizzato nel suo insieme. Un esempio di questo è l'analisi dei big data, che esamina set di dati grezzi e massicci nel tentativo di scoprire tendenze.
In questi casi, identificare e analizzare un campione rappresentativo di dati è più efficiente e conveniente rispetto a sondare l'intera popolazione o set di dati. Oltre ad essere a basso costo, analizzare un campione di dati richiede meno tempo rispetto ad analizzare l'intera popolazione di dati.
È anche una grande opzione se la tua azienda ha risorse limitate. Studiare l'intera popolazione di dati richiederebbe tempo, denaro e attrezzature varie. Se le risorse sono limitate, il campionamento dei dati è una strategia appropriata da considerare.
Sfide del campionamento dei dati
Alcune sfide o svantaggi del campionamento dei dati potrebbero sorgere durante il processo. Un fattore importante da considerare è la dimensione del campione richiesto e la possibilità di sperimentare un errore di campionamento, oltre al bias del campione.
Quando si approfondisce il campionamento dei dati, un piccolo campione potrebbe rivelare le informazioni più importanti necessarie da un set di dati. Tuttavia, in altri casi, utilizzare un campione grande può aumentare la probabilità di rappresentare accuratamente il dataset nel suo insieme, anche se l'aumento della dimensione del campione può interferire con la manipolazione e l'interpretazione di quei dati.
Per questo motivo, alcuni potrebbero avere difficoltà a selezionare un campione veramente rappresentativo per risultati più affidabili e accurati.
Non esiste un campione gratuito
Almeno, non quando si tratta dei tuoi dati. Indipendentemente dal metodo che scegli, richiederà tempo e sforzo.
Restringi la dimensione della popolazione che vuoi analizzare, rimboccati le maniche e inizia. I numeri solidi di cui la tua azienda ha bisogno per prendere decisioni basate sui dati sono a un campione di distanza!
Hai i tuoi dati, campione e analisi. Vuoi una visione più chiara? Esplora strumenti di visualizzazione dei dati per ottenere migliori intuizioni.
Questo articolo è stato originariamente pubblicato nel 2020. È stato aggiornato con nuove informazioni.

Mara Calvello
Mara Calvello is a Content and Communications Manager at G2. She received her Bachelor of Arts degree from Elmhurst College (now Elmhurst University). Mara writes content highlighting G2 newsroom events and customer marketing case studies, while also focusing on social media and communications for G2. She previously wrote content to support our G2 Tea newsletter, as well as categories on artificial intelligence, natural language understanding (NLU), AI code generation, synthetic data, and more. In her spare time, she's out exploring with her rescue dog Zeke or enjoying a good book.

