

Mara Calvello
Mara Calvello is a Content and Communications Manager at G2. She received her Bachelor of Arts degree from Elmhurst College (now Elmhurst University). Mara writes content highlighting G2 newsroom events and customer marketing case studies, while also focusing on social media and communications for G2. She previously wrote content to support our G2 Tea newsletter, as well as categories on artificial intelligence, natural language understanding (NLU), AI code generation, synthetic data, and more. In her spare time, she's out exploring with her rescue dog Zeke or enjoying a good book.
Nell'attuale ambiente tecnologico in rapida crescita, le aziende dispongono di più dati che mai.
Avere grandi quantità di dati non significa nulla; ciò che conta è cosa fai con quei dati. È qui che entra in gioco l'estrazione dei dati. Essa dà un senso ai dati mentre le aziende lavorano per implementare vari obiettivi e strategie di miglioramento potenziali attraverso il processo di trasformazione dei dati grezzi in intuizioni azionabili. Ci sono molti modi per farlo, e tutto dipende dalle tecniche di data mining che la tua azienda sceglie di utilizzare.
Il data mining è il processo di ricerca e rilevamento di schemi nei dati per ottenere intuizioni rilevanti; le varie tecniche sono il modo in cui si trasforma i dati grezzi in osservazioni accurate.
Tecniche comuni di data mining
Una varietà di tecniche di data mining è spesso necessaria per scoprire intuizioni che si trovano all'interno di grandi set di dati, quindi avrebbe senso sceglierne più di una. Mentre il data mining può segmentare i clienti, può anche aiutare a determinare la fedeltà dei clienti, identificare i rischi, costruire modelli predittivi e molto altro.
La maggior parte, ma non tutte, delle tecniche di data mining rientrano nella categoria dell'analisi statistica o dell'apprendimento automatico, a seconda di come vengono utilizzate. Di seguito, approfondiamo ciascuna tecnica.
Pulizia dei dati
Una tecnica necessaria quando si tratta di data mining è la pulizia dei dati. I dati grezzi devono essere puliti, formattati e analizzati affinché siano utili e applicabili a diversi tipi di metodi analitici. Questa tecnica fa parte di diversi elementi di modellazione dei dati, trasformazione, aggregazione e migrazione.
Come viene utilizzata la pulizia dei dati oggi?
Le aziende utilizzano la pulizia dei dati come primo passo nel processo di data mining perché altrimenti i dati trovati sono inutili e inaffidabili. Deve esserci fiducia nei dati e nei risultati che derivano dall'analisi dei dati, affinché ci sia un passo successivo valido e azionabile. La pulizia dei dati è spesso il primo passo che viene eseguito nel processo di data mining.
Clustering
Una tecnica di data mining è chiamata analisi del clustering, altrimenti nota come tassonomia numerica. Questa tecnica raggruppa essenzialmente grandi quantità di dati in base alle loro somiglianze. Questo mockup mostra come potrebbe apparire un'analisi del clustering.
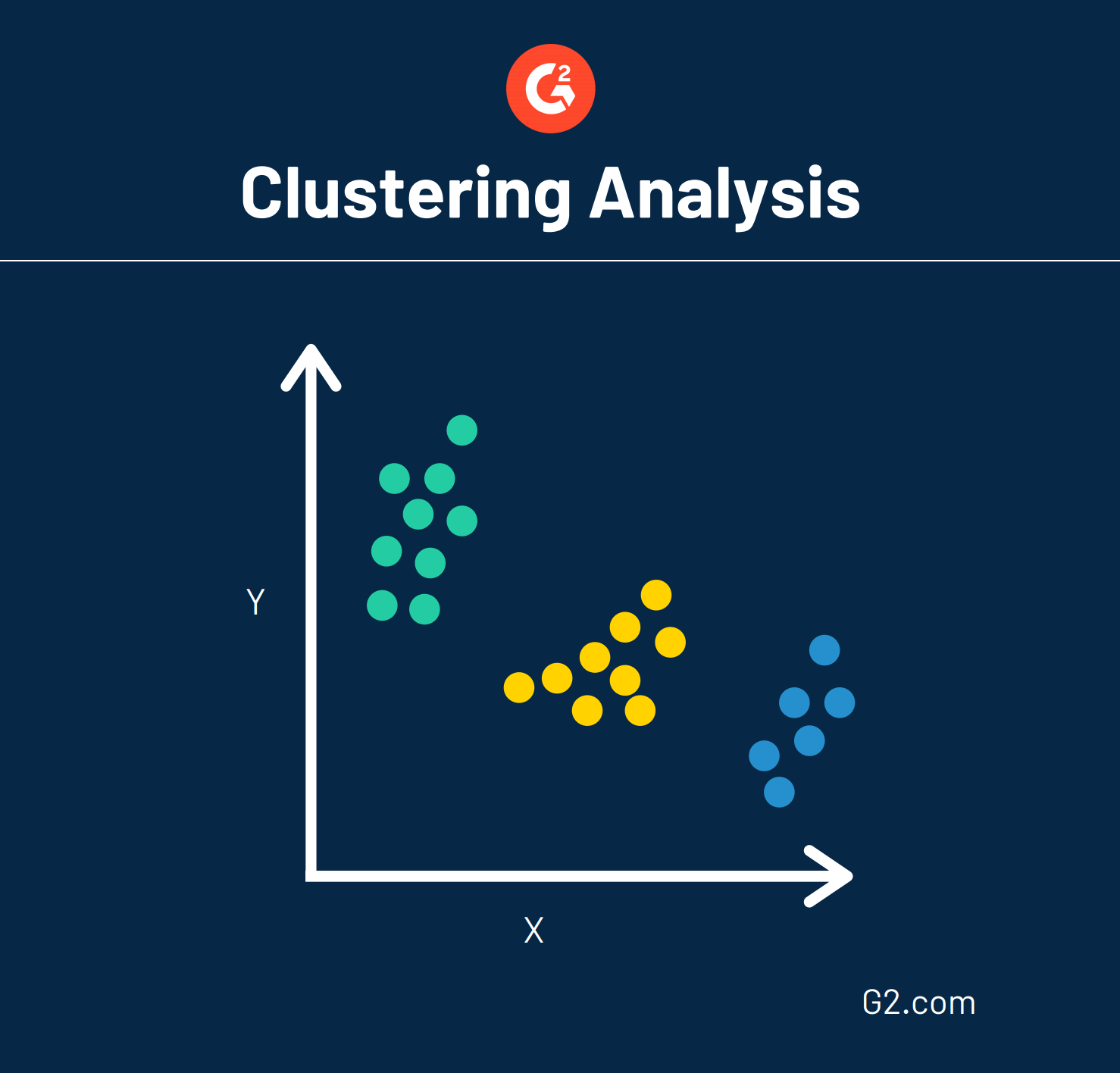
I dati che sono disposti in modo sporadico su un grafico possono essere raggruppati in modi strategici attraverso l'analisi del clustering. Questa analisi può anche fungere da fase di pre-elaborazione, il che significa che i dati sono formattati in modo tale che altre tecniche possano essere facilmente applicate.
Quando si tratta di approcci di clustering, ci sono cinque metodi principali utilizzati dai data scientist:
- Algoritmi di partizionamento: creazione di varie partizioni e successiva valutazione in base a criteri specifici
- Algoritmi gerarchici: creazione di una disposizione gerarchica del set di dati utilizzando criteri specifici
- Basato sulla densità: basato su funzioni di connettività e densità
- Basato su griglia: basato su strutture di granularità a più livelli
- Basato su modello: un modello viene prima ipotizzato per ciascuno dei cluster, quindi viene trovato il miglior adattamento del modello
Insieme a questi approcci di clustering ci sono cinque algoritmi di clustering utilizzati per classificare ciascun punto dati in un gruppo specifico. I punti dati all'interno dello stesso gruppo hanno proprietà o caratteristiche simili.
Questi algoritmi sono:
- Clustering K-Means: raggruppa le osservazioni in cluster in cui ciascun punto dati fa parte del cluster con la media più vicina
- Clustering Mean-Shift: assegna i punti dati ai cluster in modo iterativo spostando i punti verso la modalità. Più comunemente usato nell'elaborazione delle immagini e nella visione artificiale
- Clustering basato sulla densità spaziale delle applicazioni con rumore (DBSCAN): raggruppa insieme punti dati in uno spazio specifico che sono vicini tra loro mentre segna punti anomali specifici in regioni a bassa densità all'interno del cluster. Frequentemente citato nella letteratura scientifica
- Clustering Expectation-Maximization (EM) con modelli di miscela gaussiana (GMM): utilizzato per raggruppare dati non etichettati poiché tiene conto della varianza (larghezza di una curva a campana) per determinare la forma della distribuzione o del cluster
- Clustering gerarchico agglomerativo: lavora per costruire un'analisi gerarchica dei cluster con un approccio "dal basso verso l'alto". Ogni osservazione inizierà nel proprio cluster e le coppie di cluster vengono unite man mano che si sale nella gerarchia
A cosa serve il clustering?
Ci sono alcuni modi per trarre conoscenza dall'analisi del clustering. Le compagnie assicurative possono identificare gruppi di assicurati con richieste medie elevate. Il clustering può essere utilizzato nel marketing per segmentare i clienti in base ai benefici che sperimenteranno acquistando un prodotto specifico.
Un altro esempio di clustering è come i sismologi possono vedere l'origine dell'attività sismica e la forza di ciascun terremoto, quindi applicare tale intuizione per progettare percorsi di evacuazione.
Classificazione
La classificazione è spesso considerata un sottoinsieme del clustering. La classificazione consiste nell'analizzare vari attributi associati a diversi tipi di dati. Quando un'azienda può identificare le caratteristiche principali di questi tipi di dati, può organizzare e classificare meglio tutti i dati correlati.
Questo è un aspetto fondamentale per identificare tipi specifici di dati, come se un'azienda volesse proteggere ulteriormente documenti con informazioni sensibili, come numeri di previdenza sociale o numeri di carte di credito.
Rilevamento delle anomalie
Conosciuto anche come rilevamento delle anomalie, questa tecnica di data mining fa forse l'opposto del clustering. Invece di cercare grandi gruppi di dati che potrebbero essere raggruppati insieme, il rilevamento delle anomalie cerca punti dati che sono rari e al di fuori di un gruppo o media stabiliti.
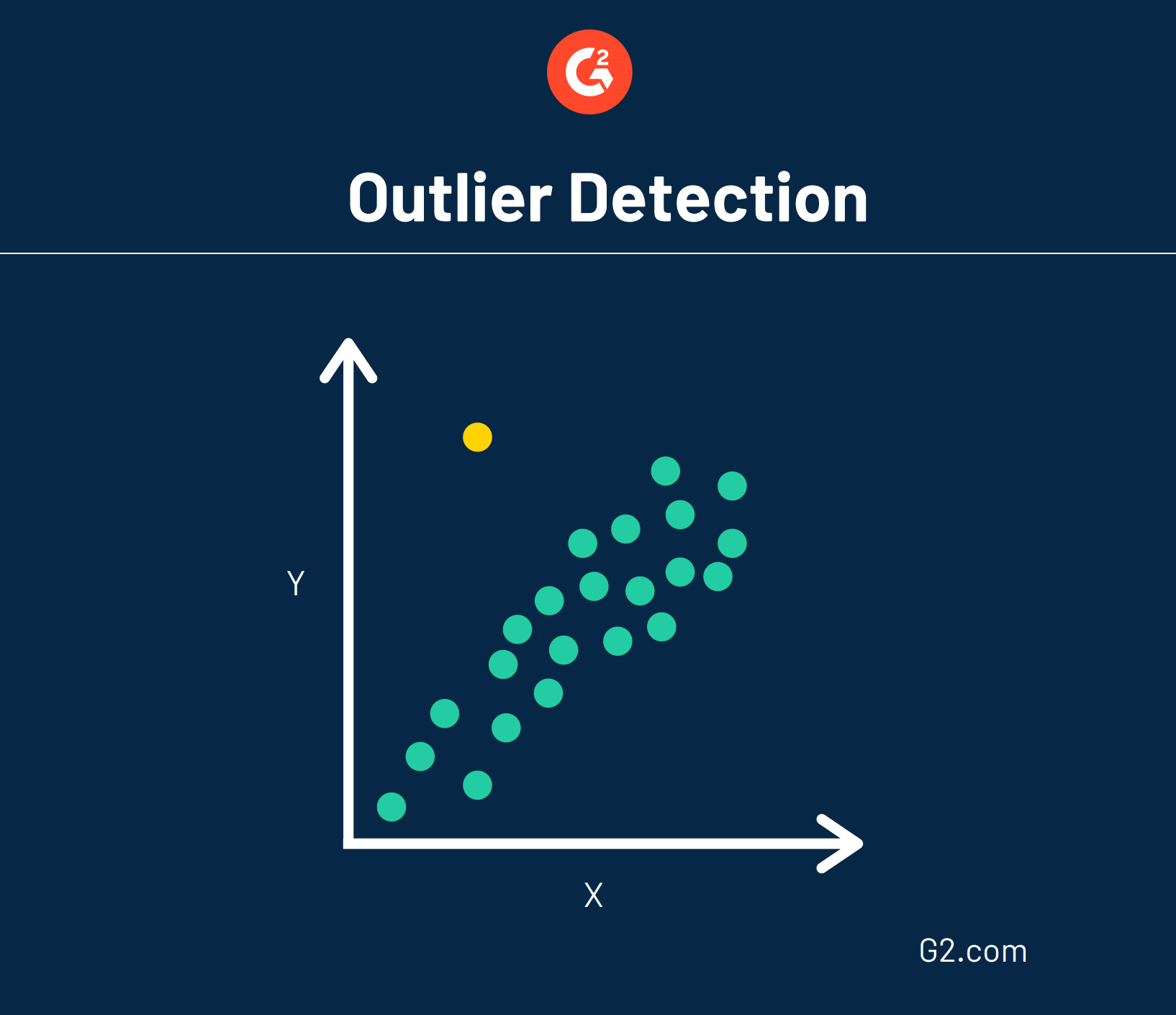
Poiché i dati sono piuttosto casuali, le anomalie non indicano necessariamente una tendenza. Invece, i dati che vanno controcorrente potrebbero indicare che sta accadendo qualcosa di anomalo e richiedono ulteriori analisi.
Una volta che un'azienda o un'organizzazione trova queste stranezze all'interno dei dati, diventa più facile capire perché queste anomalie si verificano e prepararsi per eventuali che potrebbero sorgere in futuro.
Ci sono due tipi di anomalie:
- Univariata: un punto dati che consiste in un valore estremo su una variabile
- Multivariata: una combinazione di punteggi insoliti su almeno due variabili
Di questi due tipi, ci sono quattro tecniche di rilevamento delle anomalie:
- Anomalia numerica: rilevamento delle anomalie in uno spazio unidimensionale
- Z-Score: rilevamento delle anomalie parametrico in uno spazio a una o bassa dimensione
- DBSCAN: rilevamento delle anomalie basato sulla densità in uno spazio a una o più dimensioni
- Isolation Forest: metodo non parametrico per grandi set di dati in uno spazio a una o più dimensioni
A cosa serve il rilevamento delle anomalie?
Il rilevamento delle anomalie è più comunemente utilizzato per rilevare comportamenti fraudolenti. Ad esempio, il rilevamento delle anomalie può identificare attività sospette con carte di credito e attivare una risposta (come il blocco di un account).
In un'epoca in cui gli attacchi informatici sono più robusti e comuni che mai, il rilevamento delle anomalie aiuta a identificare le violazioni dei dati sui siti web in modo che possano essere rapidamente risolte. Questo è chiamato rilevamento delle intrusioni.
Estrazione delle regole di associazione
Cercare gruppi e anomalie sono alcuni modi per estrarre conoscenza, ma un'altra tecnica chiamata estrazione delle regole di associazione esamina come una variabile si relaziona a un'altra mentre scopre un modello nascosto nel set di dati.
I data scientist cercano eventi o attributi specifici che sono altamente correlati con un altro evento o attributo. L'intuizione derivata dall'estrazione delle regole di associazione può anche aiutare le aziende a identificare potenziali correlazioni. Ad esempio, se si verifica l'evento A, allora è probabile che segua l'evento B. Se l'evento A è una tempesta di neve, possiamo supporre che l'evento B, le cancellazioni dei voli, sia probabile che avvenga successivamente. Se ti sono mai stati suggeriti prodotti su un sito di e-commerce in base a ciò che hai nel carrello, allora hai visto l'estrazione delle regole di associazione in azione.
Ad esempio, questo è ciò che Amazon mi consiglia di acquistare in base agli articoli che ho acquistato in passato.

A cosa serve l'estrazione delle regole di associazione?
Walmart ha applicato questa tecnica di data mining in modo impeccabile nel 2004 durante l'uragano Frances. Analizzando i dati delle transazioni e dell'inventario, gli analisti hanno scoperto che le vendite di Pop-Tart alla fragola erano sette volte più alte proprio prima che l'uragano colpisse. Anche la birra è stata rivelata come l'articolo più venduto prima dell'uragano. Con queste informazioni a portata di mano, Walmart si è assicurata di fare scorta. Come Walmart, le piccole e medie imprese possono utilizzare questi dati allo stesso modo.
Regressione
Se un'azienda sta cercando di fare una previsione basata sull'effetto che una variabile ha su altre, potrebbe fare riferimento a una tecnica di data mining chiamata analisi della regressione. Questo metodo di dati identifica e analizza la relazione tra variabili.
Ricorda: La regressione e l'associazione sono spesso confuse l'una con l'altra. La regressione nell'analisi statistica è l'equazione utilizzata per specificare e associare i dati per due o più variabili. L'associazione è la relazione tra due quantità misurate che le renderà dipendenti o correlate.
A cosa serve la regressione?
In superficie, i dati sono caotici. C'è molto tentativo ed errore coinvolto quando si esamina la relazione tra un set di dati e un altro, specialmente quando un'azienda sta cercando di capire le probabilità degli eventi e fare previsioni. L'analisi della regressione può indirizzare queste previsioni nella giusta direzione.
Un esempio di analisi della regressione nel settore sanitario è l'esame degli effetti che l'indice di massa corporea, o BMI, ha su altre variabili. Si utilizzerebbe anche la regressione per determinare come il prezzo di un prodotto influenzerà il numero di vendite che la tua azienda ha o come la quantità di pioggia influenzerà la crescita delle colture.
Regressione lineare
Un tipo comune di regressione è chiamato regressione lineare.
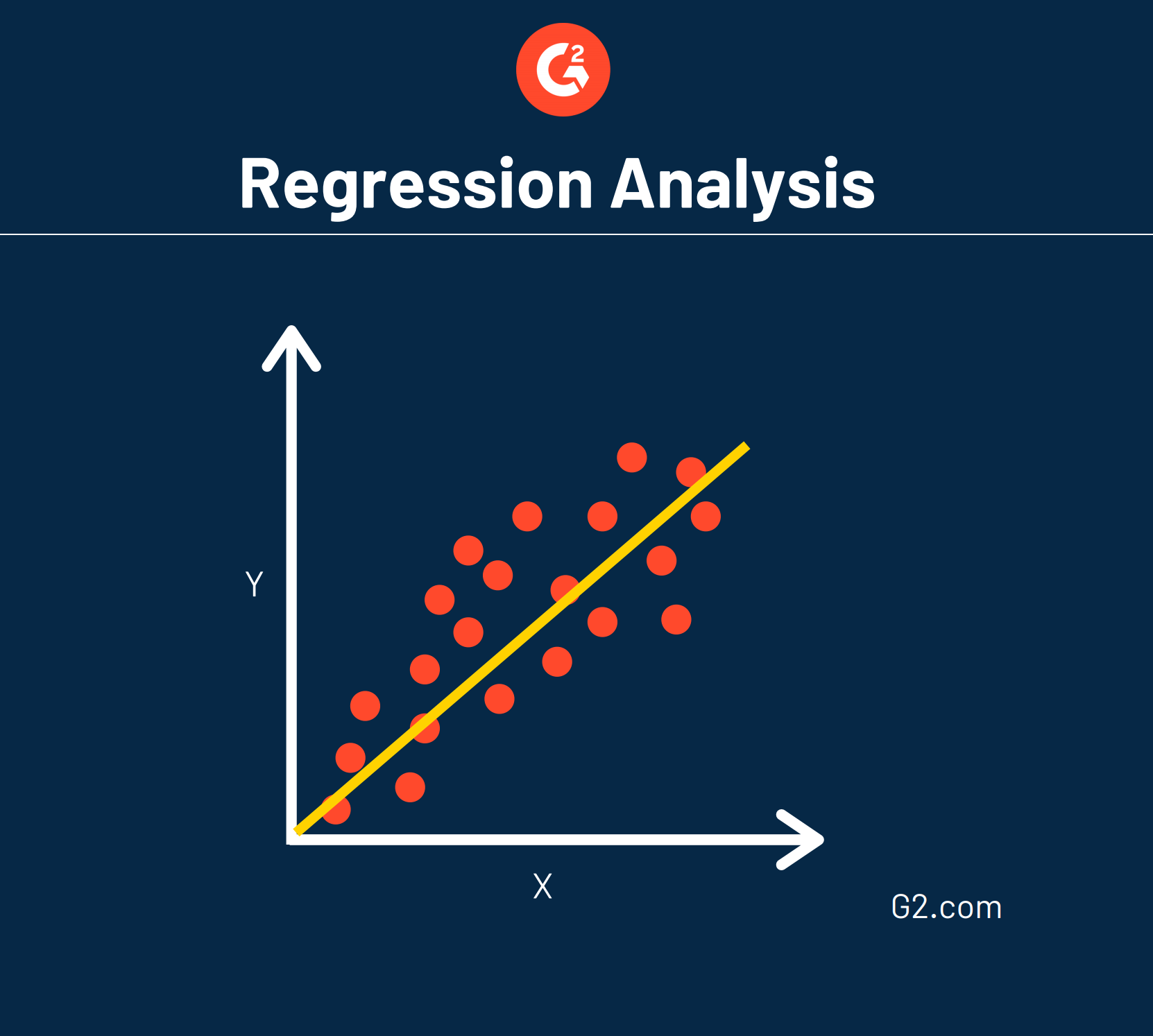
Ciò significa che può essere tracciata una linea retta per mostrare come ciascuna variabile si relaziona l'una con l'altra.
Correlato: Scopri di più sulla regressione, la differenza tra correlazione e regressione, e quando dovresti usare queste due misurazioni statistiche.
Albero decisionale
Una delle tecniche di data mining più visive è chiamata analisi dell'albero decisionale, ed è un metodo popolare per prendere decisioni importanti.
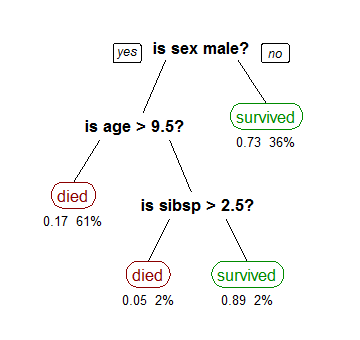
Fonte: Research Gate
Ci sono due tipi di analisi dell'albero decisionale. Uno di essi è chiamato classificazione, che è ciò che vedi nell'esempio sopra determinando se un passeggero sarebbe sopravvissuto sul Titanic. La classificazione è basata sulla logica, utilizzando una varietà di condizioni se/allora o sì/no fino a quando tutti i dati rilevanti sono mappati.
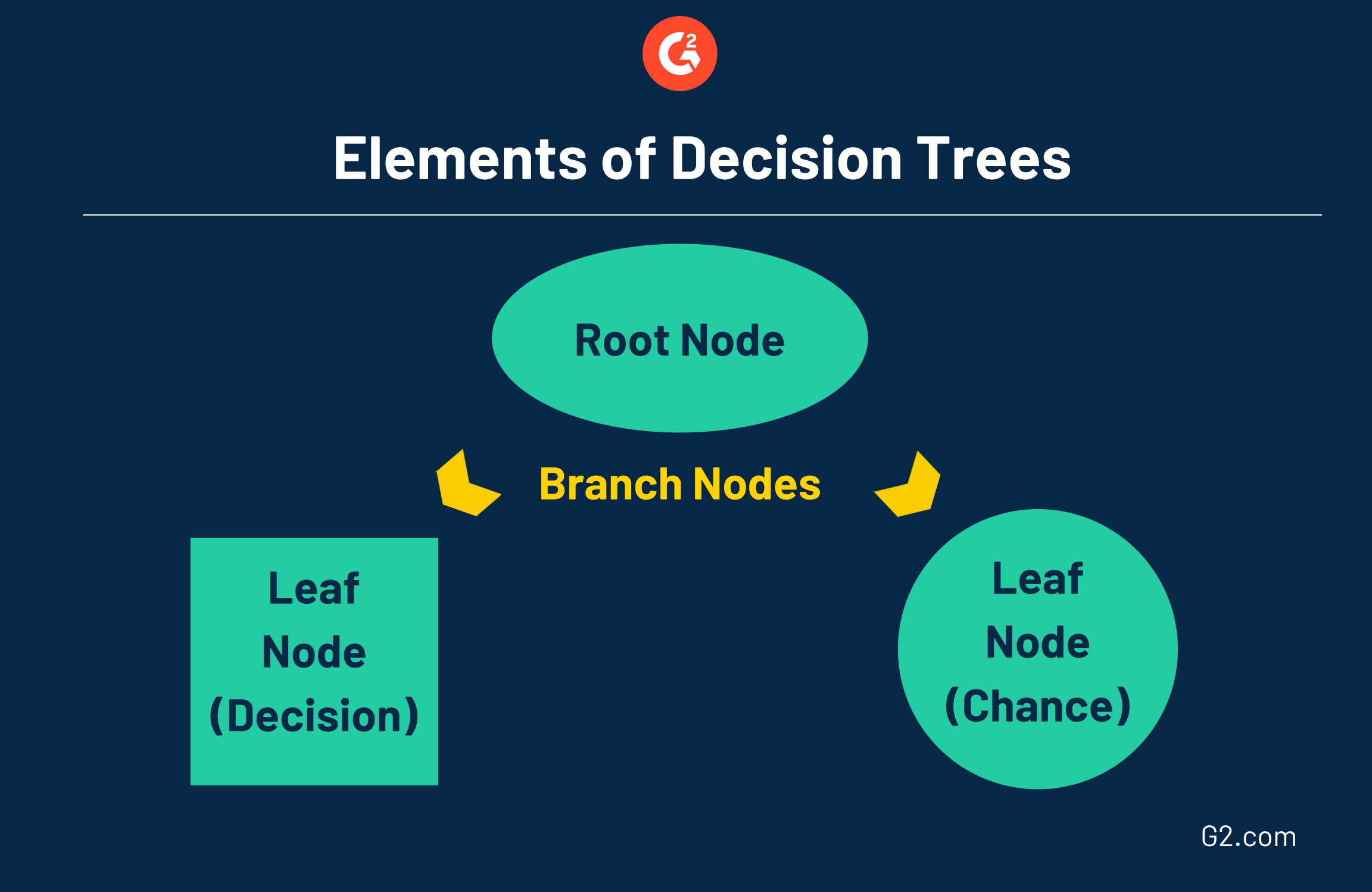
Questi alberi consistono in tre diversi elementi:
- Nodo radice: il nodo di livello superiore che rappresenta l'obiettivo o la decisione finale che stai cercando di prendere.
- Rami: che si diramano dalla radice, i rami rappresentano diverse opzioni o corsi d'azione, che sono comunemente rappresentati da una freccia.
- Nodo foglia: attaccato alla fine dei rami, i nodi foglia rappresentano i possibili risultati per ciascuna azione. Un nodo quadrato indica che è necessaria un'altra decisione, mentre un nodo foglia circolare indica un evento casuale o un risultato sconosciuto.
L'altro albero decisionale è chiamato regressione, che viene utilizzato quando la decisione target è un valore numerico. Ad esempio, la regressione potrebbe essere utilizzata per determinare il valore di una casa. Entrambi gli alberi decisionali possono essere eseguiti attraverso programmi di apprendimento automatico.
Non sei sicuro di quale software di apprendimento automatico utilizzare per eseguire il tuo albero decisionale? Dai un'occhiata a centinaia di recensioni imparziali offerte gratuitamente da G2!
Un albero decisionale consente a un utente di comprendere chiaramente come gli input dei dati influenzano gli output. Quando più di un albero decisionale viene combinato per un'analisi predittiva, questo diventa ciò che è noto come foresta casuale. Quando un modello di foresta casuale diventa troppo complesso, viene definito una tecnica di apprendimento automatico a scatola nera perché è difficile comprendere i loro output basati sugli input.
Predizione
Come suggerisce il nome, la predizione o l'analisi predittiva utilizza una combinazione di altre tecniche di data mining, come il clustering e la classificazione, per analizzare eventi o istanze passate nella giusta sequenza per prevedere un evento futuro.
Nella maggior parte dei casi, riconoscere e comprendere le tendenze storiche è sufficiente per caricare una previsione accurata di ciò che potrebbe accadere in futuro. Ci sono molti approcci all'analisi predittiva, dall'apprendimento automatico all'intelligenza artificiale. Tuttavia, la previsione accurata non dipende da queste due tecniche; può anche essere determinata utilizzando vari algoritmi.
A cosa serve la predizione?
Molte organizzazioni utilizzano la predizione per ottenere informazioni su quali tendenze accadranno successivamente all'interno dei loro dati. Come il rilevamento delle anomalie, l'analisi predittiva può anche rilevare frodi, vulnerabilità zero-day e minacce persistenti. Un esempio specifico è come Staples ha utilizzato la predizione per analizzare il comportamento e fornire un quadro completo dei loro clienti, il che ha portato a un aumento del 137% del ROI.
Visualizzazione dei dati
La visualizzazione dei dati lavora per fornire agli utenti ulteriori intuizioni sulle loro informazioni utilizzando grafici e diagrammi in tempo reale per comprendere meglio gli obiettivi di performance. Questa tecnica è popolare perché la visualizzazione dei dati è in grado di consumare dati da qualsiasi fonte attraverso caricamenti di file, interrogazioni di database e connettori di applicazioni.
Come viene utilizzata la visualizzazione dei dati oggi?
Grazie ai dashboard creati utilizzando software di visualizzazione dei dati, trovare varie intuizioni, tendenze e KPI nei dati è più facile che mai. Molti di questi strumenti forniscono funzionalità di trascinamento e rilascio e altre capacità non tecniche, in modo che l'utente aziendale medio possa costruire i dashboard necessari.
Questo tipo di software è utilizzato da dirigenti di livello C e team nei settori delle vendite, del marketing, del servizio clienti e delle risorse umane. Ad esempio, i membri del tuo team di vendita utilizzerebbero questo software per monitorare i numeri di fatturato sugli affari che hanno chiuso, mentre i team di marketing utilizzano questi strumenti per analizzare il traffico web, le campagne email e le impressioni sui social media.
Correlato: Scopri di più sui 67 tipi di visualizzazioni dei dati che la tua azienda può utilizzare per vedere il quadro generale.
Reti neurali
L'apprendimento neurale è un tipo specifico di modello di apprendimento automatico e tecnica statistica che viene spesso utilizzato in combinazione con l'intelligenza artificiale e l'apprendimento profondo, e sono alcuni dei modelli di apprendimento automatico più accurati che utilizziamo oggi.
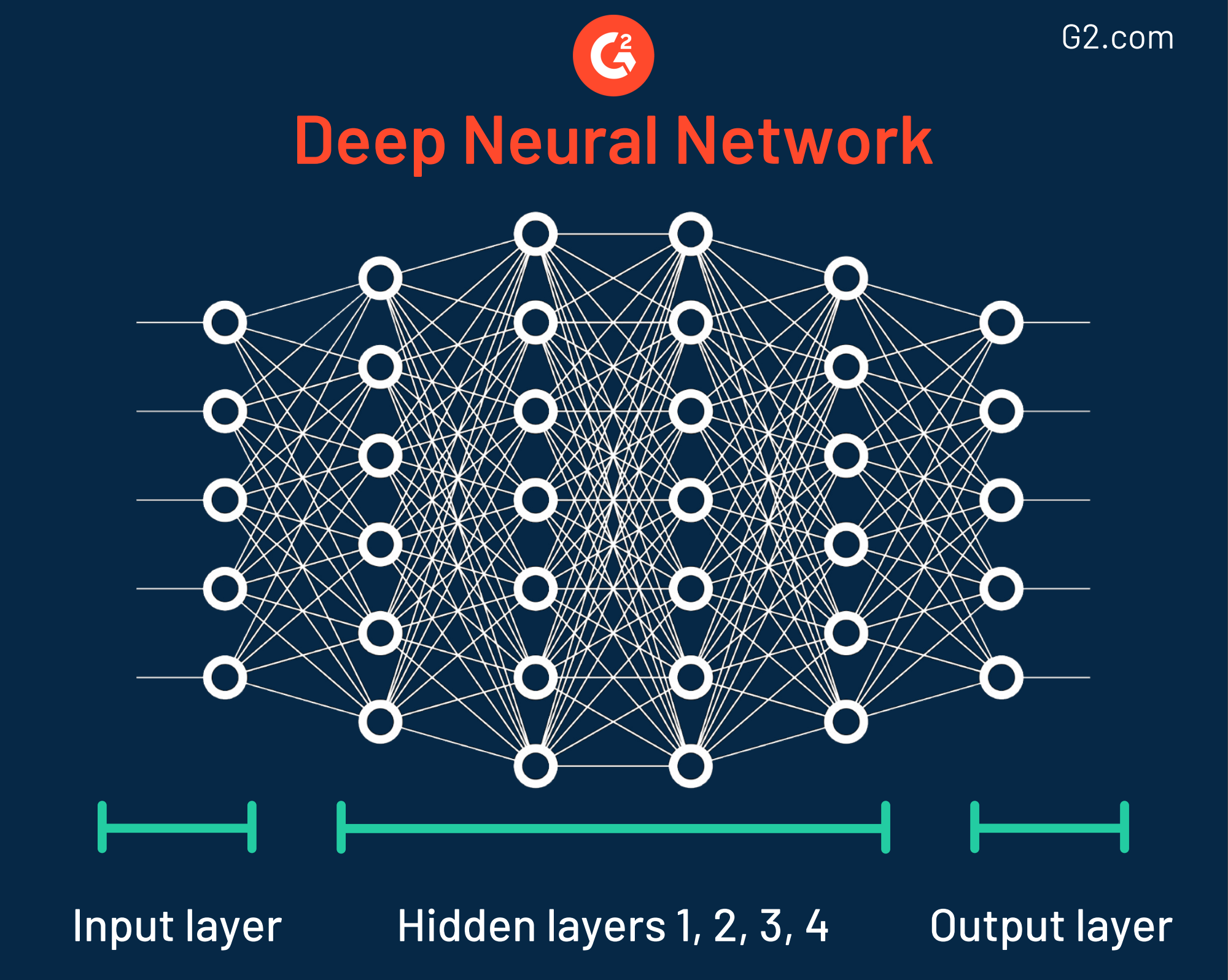
Questa tecnica di data mining è stata chiamata così quando è stata scoperta negli anni '40 perché ha diversi strati, tutti simili ai modi in cui i neuroni lavorano nel cervello umano. Nonostante la sua accuratezza, le organizzazioni che utilizzano reti neurali dovrebbero essere consapevoli del fatto che alcuni di questi modelli sono estremamente complessi, il che rende difficile comprendere come viene determinato l'output.
Infatti, alcune reti neurali sono così incredibilmente intricate che hanno fino a 150 strati nascosti. Ogni strato gioca un ruolo chiave nel scomporre le caratteristiche dei dati grezzi. Questo è formalmente chiamato estrazione delle caratteristiche.
Come vengono utilizzate le reti neurali oggi?
Le reti neurali con solo pochi strati sono utilizzate in banche e uffici postali per riconoscere gli stili di scrittura a mano. Questo è utile quando si incassano assegni con il tuo telefono cellulare.
Reti neurali più complesse con molti strati sono attualmente utilizzate per sviluppare auto senza conducente. Estrarre elementi dalla strada, riconoscere le strisce pedonali e i segnali stradali, e comprendere i modelli di movimento di altri veicoli sono solo alcuni dei molti tipi di dati grezzi che vengono scomposti pezzo per pezzo in reti neurali complesse.
Analisi delle componenti principali
La tecnica di data mining analisi delle componenti principali (PCA) viene utilizzata per illustrare connessioni nascoste tra variabili di input mentre crea nuove variabili che visualizzano le stesse informazioni catturate utilizzando dati originali ma con meno variabili. Essenzialmente, questo metodo combina informazioni correlate per formare un numero minore di variabili chiamate "componenti principali" che rappresentano la maggior parte della varianza nei dati.
Lo scopo di ridurre il numero di variabili, pur trasmettendo la stessa quantità di informazioni, è che gli analisti dei dati possano migliorare l'accuratezza dei modelli di data mining supervisionati. Essenzialmente, rende i tuoi dati facili da esplorare e visualizzare.
Come viene utilizzata l'analisi delle componenti principali oggi?
La PCA è più comunemente utilizzata da coloro che lavorano nel settore finanziario da coloro che conducono e analizzano vari tassi di interesse. Coloro che lavorano con le azioni e il mercato azionario utilizzano anche la PCA per determinare quali azioni scambiare e quando.
Tracciamento dei modelli
Quando si tratta di tecniche di data mining, il tracciamento dei modelli è una delle fondamentali. Il tracciamento dei modelli comporta l'identificazione e il monitoraggio delle tendenze e dei modelli nei dati per fare una presunzione intelligente e calcolata sugli esiti aziendali.
Quando viene utilizzato il tracciamento dei modelli oggi?
Supponiamo che un'organizzazione identifichi una tendenza nei propri dati di vendita e la utilizzi come punto di partenza per capitalizzare su un'intuizione specifica. Se i dati mostrano che un certo prodotto sta vendendo meglio di altri per un particolare demografico, potrebbero decidere di utilizzare quei dati per creare prodotti o servizi simili. Allo stesso modo, potrebbero scegliere di rifornire meglio il prodotto originale per quel demografico.
Data warehousing
Conosciuto anche come data warehousing aziendale, il data warehousing comporta l'archiviazione di dati strutturati in sistemi di gestione di database relazionali in modo che possano essere analizzati per l'uso di report e business intelligence. Le tecniche di data mining e data warehousing di oggi utilizzano entrambi i data warehouse cloud per un'archiviazione più sicura di queste intuizioni.
Le informazioni archiviate in questi magazzini possono essere utilizzate per:
- Ottimizzazione delle strategie di produzione: confrontare le vendite di prodotti trimestralmente o annualmente per gestire i portafogli e riposizionare i prodotti
- Analisi dei clienti: esaminare più a fondo le preferenze di acquisto dei clienti, i cicli di budget, i tempi di acquisto e altro
- Analisi delle operazioni: aiutare ad analizzare le operazioni aziendali, le relazioni con i clienti e come stabilire connessioni ambientali adeguate
Come viene utilizzato il data warehousing oggi?
I settori degli investimenti e delle assicurazioni utilizzano il data warehousing per analizzare i modelli di dati, le tendenze dei clienti e per monitorare i movimenti del mercato. Coloro che lavorano nel retail utilizzano i data warehouse per monitorare gli articoli, i modelli di acquisto dei clienti, le promozioni e per determinare la politica dei prezzi.
Scopri l'ignoto
Utilizzare la giusta tecnica di data mining è sicuro di fornire intuizioni senza precedenti nella tua ricchezza di dati. Man mano che la tecnologia diventa più avanzata, il data mining continuerà a crescere e a trovare intuizioni più approfondite.
Rimboccati le maniche e immergiti a fondo in ciò che i tuoi dati ti stanno mostrando; potresti essere sorpreso da ciò che trovi.
Porta tutta questa conoscenza un passo avanti e scopri l'analisi aziendale e come può essere utilizzata per raggiungere il successo.