

Devin Pickell
Devin is a former senior content specialist at G2. Prior to G2, he helped scale early-stage startups out of Chicago's booming tech scene. Outside of work, he enjoys watching his beloved Cubs, playing baseball, and gaming. (he/him/his)
Si vous êtes comme moi, vous aimez la structure, la propreté et la simplicité.
Mais dans certains cas, il est préférable de prendre du recul et de laisser le chaos organisé se dérouler. C'est la base de ce qu'on appelle un lac de données.
Qu'est-ce qu'un lac de données ?
Définition d'un lac de données
Un lac de données est un dépôt pour les données structurées, non structurées et semi-structurées. Les lacs de données sont très différents des entrepôts de données car ils permettent aux données d'être dans leur forme la plus brute sans avoir besoin d'être converties et analysées au préalable.
En termes plus simples, tous les types de données générées par les humains et les machines peuvent être chargés dans un lac de données pour être classifiés et analysés plus tard.
Les entrepôts de données, en revanche, nécessitent que les données soient correctement structurées avant que tout travail puisse être effectué.
Pour mieux comprendre les lacs de données et pourquoi ils sont le candidat optimal pour héberger les big data, il est important de plonger dans ce qui les rend si différents des entrepôts de données.
Vous voulez en savoir plus sur Solutions de stockage de données ? Découvrez les produits Entrepôt de données.
Lac de données vs. entrepôt de données
Les lacs de données et les entrepôts de données sont tous deux des dépôts pour les données. C'est à peu près la seule similitude entre les deux. Maintenant, abordons quelques-unes des principales différences :
- Les lacs de données sont conçus pour prendre en charge tous les types de données, tandis que les entrepôts de données utilisent des données hautement structurées – dans la plupart des cas.
- Les lacs de données stockent toutes les données qui peuvent ou non être analysées à un moment donné dans le futur. Ce principe ne s'applique pas aux entrepôts de données car les données non pertinentes sont généralement éliminées en raison d'un espace de stockage limité.
- L'échelle entre les lacs de données et les entrepôts de données est radicalement différente en raison de nos points précédents. Le soutien de tous les types de données et le stockage de ces données (même si elles ne sont pas immédiatement utiles) signifient que les lacs de données doivent être hautement évolutifs.
- Grâce aux métadonnées (données sur les données), les utilisateurs travaillant avec un lac de données peuvent obtenir rapidement un aperçu de base des données. Dans les entrepôts de données, cela nécessite souvent un membre de l'équipe de développement pour accéder aux données – ce qui pourrait créer un goulot d'étranglement.
- Enfin, la gestion intense des données requise pour les entrepôts de données signifie qu'ils sont généralement plus coûteux à entretenir par rapport aux lacs de données.
James Dixon, fondateur et directeur technique de Pentaho, a inventé le terme « lac de données » après avoir fourni une analogie différenciant les lacs de données des entrepôts de données.
« Si vous pensez à un datamart comme à un magasin d'eau en bouteille – nettoyée et emballée et structurée pour une consommation facile – le lac de données est un grand plan d'eau dans un état plus naturel », a déclaré Dixon. « Le contenu du lac de données s'écoule d'une source pour remplir le lac, et divers utilisateurs du lac peuvent venir examiner, plonger ou prendre des échantillons. »
James Dixon
fondateur et directeur technique de Pentaho
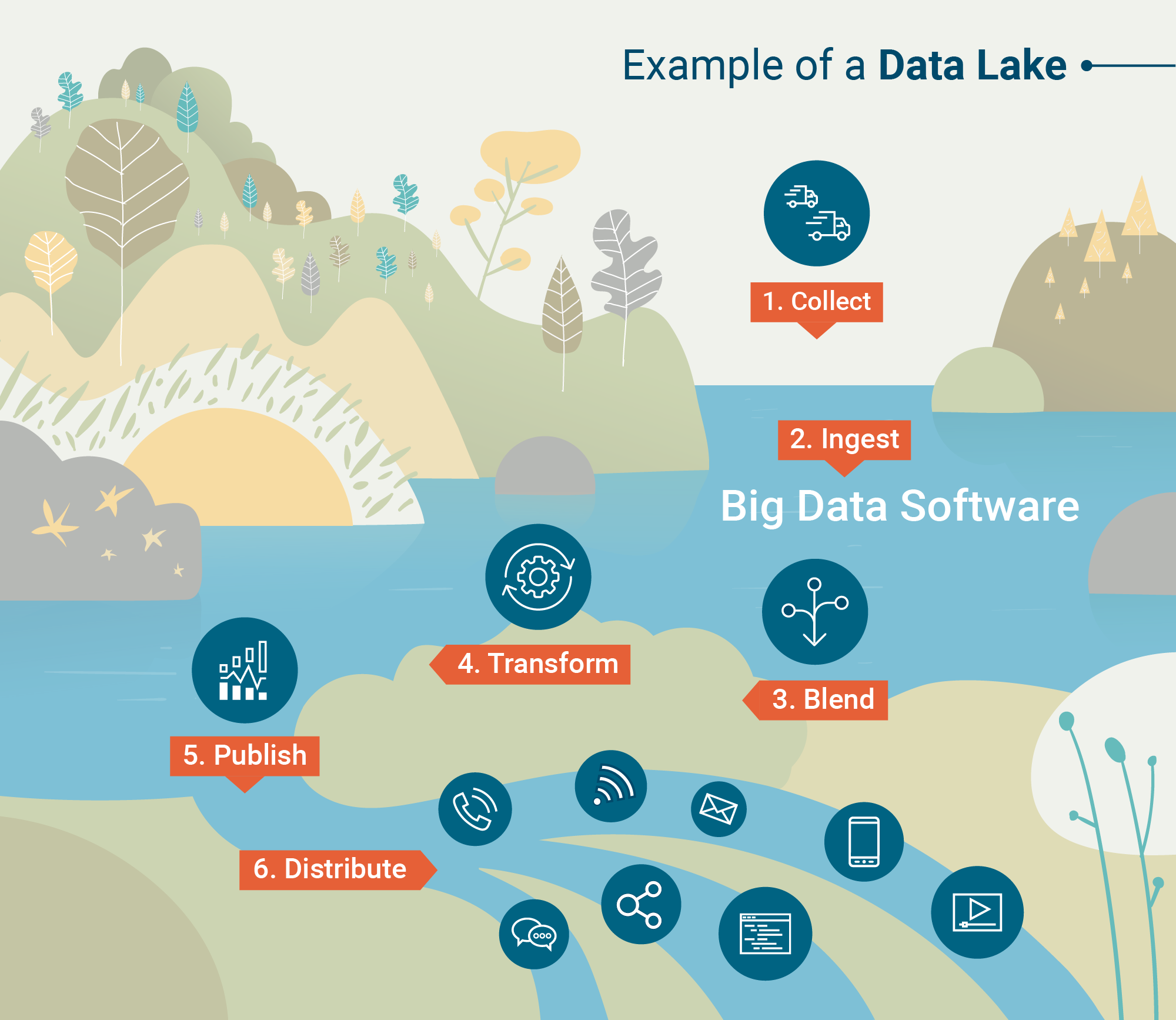
Architecture du lac de données
Alors, comment les lacs de données sont-ils capables de stocker des quantités aussi vastes et diversifiées de données ? Quelle est l'architecture sous-jacente de ces dépôts massifs ?
Les lacs de données sont construits sur un modèle de données schéma à la lecture. Un schéma est essentiellement le squelette d'une base de données décrivant son modèle et comment les données y seront structurées. Pensez à un plan.
Le modèle de données schéma à la lecture signifie que vous pouvez charger vos données dans le lac telles quelles sans avoir à vous soucier de leur structure. Cela permet beaucoup plus de flexibilité.
Les entrepôts de données, en revanche, sont composés de modèles de données schéma à l'écriture. C'est un modèle beaucoup plus traditionnel pour les bases de données.
Chaque ensemble de données, chaque relation et chaque index dans le modèle de données schéma à l'écriture doit être clairement défini à l'avance. Cela limite la flexibilité, surtout lors de l'ajout de nouveaux ensembles de données ou de fonctionnalités qui pourraient potentiellement créer des lacunes dans la base de données.
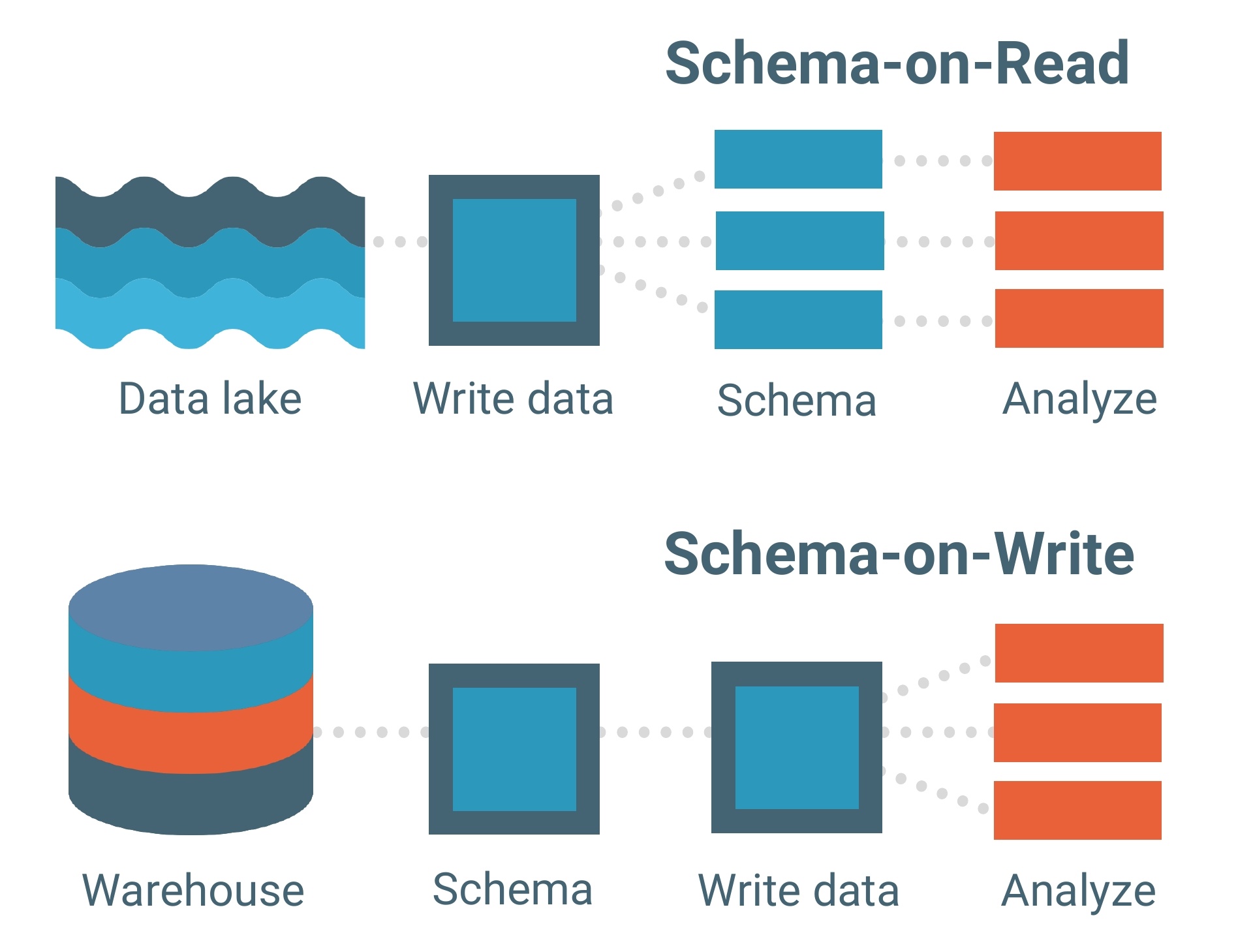
Le modèle de données schéma à la lecture agit comme la colonne vertébrale d'un lac de données, mais le cadre de traitement (ou moteur) est la façon dont les données sont réellement chargées dans un lac.
Ci-dessous sont les deux cadres de traitement qui « ingèrent » les données dans les lacs de données :
- Traitement par lots – Des millions de blocs de données traités sur de longues périodes de temps (heures à jours). La méthode la moins sensible au temps pour traiter les big data.
- Traitement en flux – Petits lots de données traités en temps réel. Le traitement en flux devient de plus en plus précieux pour les entreprises qui exploitent l'analyse en temps réel.

Hadoop, Apache Spark et Apache Storm sont parmi les outils de traitement des big data les plus couramment utilisés qui sont capables de traiter par lots ou en flux.
Certains outils sont particulièrement utiles pour traiter des données non structurées telles que l'activité des capteurs, les images, les publications sur les réseaux sociaux et l'activité des clics sur Internet. D'autres outils privilégient la vitesse de traitement et l'utilité avec les programmes d'apprentissage automatique.
Une fois que les données sont traitées et ingérées dans le lac de données, il est temps de les utiliser.
À quoi servent les lacs de données ?
Les entrepôts de données reposent sur la structure et les données propres, tandis que les lacs de données permettent aux données d'être dans leur forme la plus naturelle. Cela est dû au fait que les outils d'analyse avancés et les logiciels de fouille de données prennent les données brutes et les transforment en informations utiles.
Analyse des big data
L'analyse des big data plongera dans un lac de données dans le but de découvrir des modèles, des tendances du marché et des préférences des clients pour aider les entreprises à faire des prédictions éclairées plus rapidement. Cela se fait à travers quatre analyses différentes.
- Analyse descriptive – Une analyse rétrospective examinant « où » un problème a pu se produire pour une entreprise. La plupart des analyses de données aujourd'hui sont en fait descriptives car elles peuvent être générées rapidement.
- Analyse diagnostique – Une autre analyse rétrospective examinant « pourquoi » un problème spécifique a pu se produire pour une entreprise. C'est légèrement plus approfondi que l'analyse descriptive.
- Analyse prédictive – Lorsque les logiciels d'IA et d'apprentissage automatique sont appliqués, cette analyse peut fournir à une organisation des modèles prédictifs de ce qui pourrait se produire ensuite. En raison de la complexité de la génération d'analyses prédictives, elle n'est pas encore largement adoptée.
- Analyse prescriptive – L'avenir de l'analyse des big data est l'analyse prescriptive qui non seulement aide dans les efforts de prise de décision mais peut même être capable de fournir à une organisation un ensemble de réponses. Il y a un très haut niveau d'utilisation de l'apprentissage automatique avec ces analyses.
Fouille de données
La fouille de données est définie comme « la découverte de connaissances dans les bases de données », et c'est ainsi que les data scientists découvrent des modèles et des vérités auparavant invisibles à travers divers modèles.
Par exemple, une analyse de regroupement est un type de technique de fouille de données qui peut être appliquée à un ensemble dans un lac de données. Cela regroupera de grandes quantités de données en fonction de leurs similitudes.
Grâce aux outils de visualisation des données, la fouille de données aide à clarifier la nature chaotique des formes de données non structurées et brutes.
Défis des lacs de données
Les lacs de données peuvent être flexibles, évolutifs et rapides à charger, mais cela a un prix.
L'ingestion de données non structurées nécessite un manque de gouvernance des données et de processus qui garantissent que les bonnes données sont examinées. Pour la plupart des entreprises – en particulier celles qui n'ont pas encore adopté les big data – avoir des données non organisées et non nettoyées n'est pas une option.
Une mauvaise utilisation des métadonnées ou des processus pour garder le lac de données sous contrôle peut en fait conduire à quelque chose appelé un marais de données. Vous n'iriez pas nager dans un marais, n'est-ce pas ?
Il y a aussi la question de la sécurité des données.
Les lacs de données sont un concept assez nouveau en informatique, ce qui signifie que certains des outils sont encore en train de résoudre les problèmes de sécurité. L'un de ces problèmes est de s'assurer que seules les bonnes personnes ont accès aux données sensibles chargées dans le lac.
Mais comme toute nouvelle technologie, ces problèmes se résoudront avec le temps.
| CONSEIL : Prêt à plonger plus profondément dans le monde des données ? Apprenez les bases de la gestion des données de référence (MDM) et pourquoi elle est importante pour les entreprises. |
Le rôle des lacs de données avec les big data
Malgré certains des défis des lacs de données, le fait demeure que plus de 80 % de toutes les données sont non structurées. À mesure que de plus en plus d'entreprises se tournent vers les big data pour de futures opportunités, l'application des lacs de données augmentera.
Les données non structurées comme les publications sur les réseaux sociaux, les enregistrements d'appels téléphoniques et l'activité des clics contiennent des informations précieuses qui ne peuvent pas être retenues dans les entrepôts de données.
Alors que les entrepôts de données sont forts en structure et en sécurité, les big data doivent simplement être non confinées pour pouvoir s'écouler librement dans les lacs de données.
Consultez notre guide complet sur les données structurées vs non structurées pour une explication plus approfondie ou lisez sur l'importance de l'ingénierie des big data.