

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.
Vladimir N. Vapnik a développé les algorithmes de machine à vecteurs de support (SVM) pour résoudre les problèmes de classification dans les années 1990. Ces algorithmes trouvent un hyperplan optimal, qui est une ligne dans un plan 2D ou 3D, entre deux catégories de données pour les distinguer.
Les SVM facilitent le processus de l'algorithme d'apprentissage automatique (ML) pour généraliser de nouvelles données tout en faisant des prédictions de classification précises.
De nombreux logiciels de reconnaissance d'image et plateformes de classification de texte utilisent les SVM pour classer les images ou les documents textuels. Mais la portée des SVM va au-delà de cela. Après avoir couvert les fondamentaux, explorons certaines de leurs utilisations plus larges.
Qu'est-ce que les machines à vecteurs de support ?
Les machines à vecteurs de support (SVM) sont des algorithmes d'apprentissage supervisé qui proposent des méthodes de classification d'objets dans un espace n-dimensionnel. Les coordonnées de ces objets sont généralement appelées caractéristiques.
Les SVM tracent un hyperplan pour séparer deux catégories d'objets de sorte que tous les points d'une catégorie d'objets soient d'un côté de l'hyperplan. L'objectif est de trouver le meilleur plan, qui maximise la distance (ou marge) entre deux points dans chaque catégorie. Les points qui tombent sur cette marge sont appelés vecteurs de support. Ces vecteurs de support sont essentiels pour définir l'hyperplan optimal.
Comprendre les machines à vecteurs de support en détail
Les SVM nécessitent un entraînement sur des points étiquetés de catégories spécifiques pour trouver l'hyperplan, ce qui en fait un algorithme d'apprentissage supervisé. L'algorithme résout un problème d'optimisation convexe en arrière-plan pour maximiser la marge avec chaque point de catégorie du bon côté. Sur la base de cet entraînement, il peut attribuer une nouvelle catégorie à un objet.

Source: Visually Explained
Les machines à vecteurs de support sont faciles à comprendre, à mettre en œuvre, à utiliser et à interpréter. Cependant, leur simplicité ne leur est pas toujours bénéfique. Dans certaines situations, il est impossible de séparer deux catégories avec un simple hyperplan. Pour résoudre ce problème, l'algorithme trouve un hyperplan dans l'espace de dimension supérieure avec une technique connue sous le nom de trick du noyau et le projette dans l'espace d'origine.
C'est le trick du noyau qui vous permet d'effectuer ces étapes efficacement.
Vous voulez en savoir plus sur Logiciel de reconnaissance d'image ? Découvrez les produits Reconnaissance d'image.
Qu'est-ce qu'un trick du noyau ?
Dans le monde réel, séparer la plupart des ensembles de données avec un simple hyperplan est difficile car la frontière entre deux classes est rarement plate. C'est là que le trick du noyau intervient. Il permet aux SVM de gérer efficacement les frontières de décision non linéaires sans modifier de manière significative l'algorithme lui-même.
Cependant, choisir cette transformation non linéaire est délicat. Pour obtenir une frontière de décision sophistiquée, vous devez augmenter la dimension de la sortie, ce qui augmente les exigences computationnelles.
Le trick du noyau résout ces deux défis en une seule fois. Il est basé sur une approche où l'algorithme SVM n'a pas besoin de savoir chaque fois que chaque point est mappé sous transformation non linéaire. Il peut travailler avec la façon dont chaque point de données se compare aux autres.
Lors de l'application de la transformation non linéaire, vous prenez le produit intérieur entre F(x) et F(x) prime, connu sous le nom de fonction noyau.
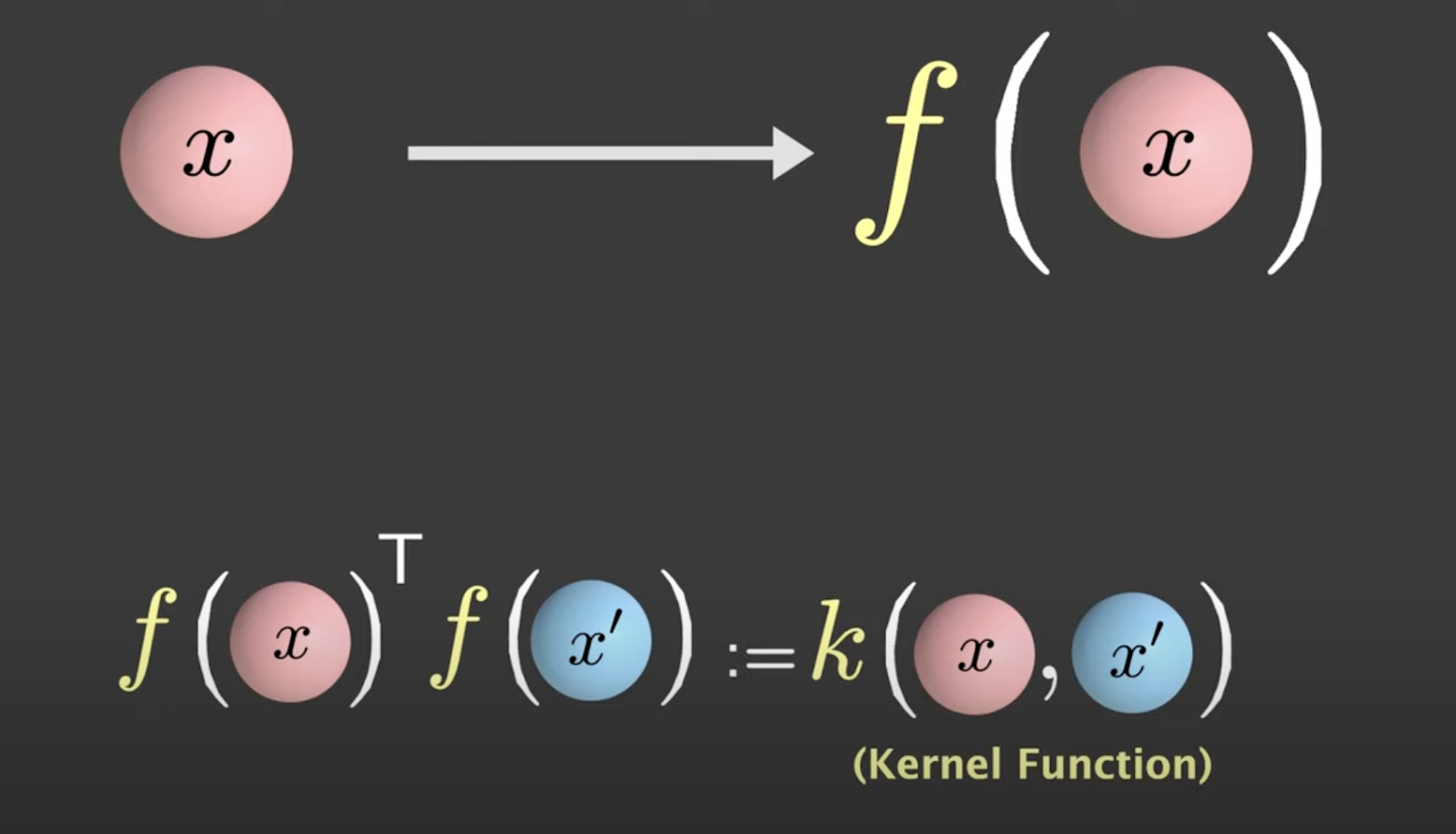
Source: Visually Explained
Cependant, ce noyau linéaire donne une frontière de décision qui peut ou non être suffisante pour séparer les données. Dans de tels cas, vous optez pour une transformation polynomiale correspondant à un noyau polynomial. Cette approche prend en compte les caractéristiques originales de l'ensemble de données ainsi que leurs interactions pour obtenir une frontière de décision plus sophistiquée et courbée.

Source: Visually Explained
Le trick du noyau est bénéfique et ressemble à un code de triche de jeu vidéo. Il est facile de le modifier et de faire preuve de créativité avec les noyaux.
Types de classificateurs de machine à vecteurs de support
Il existe deux types de SVM classifiés : linéaire et noyau.
1. SVM linéaires
Les SVM linéaires sont utilisés lorsque les données n'ont pas besoin de subir de transformations et sont linéairement séparables. Une seule ligne droite peut facilement séparer les ensembles de données en catégories ou classes.
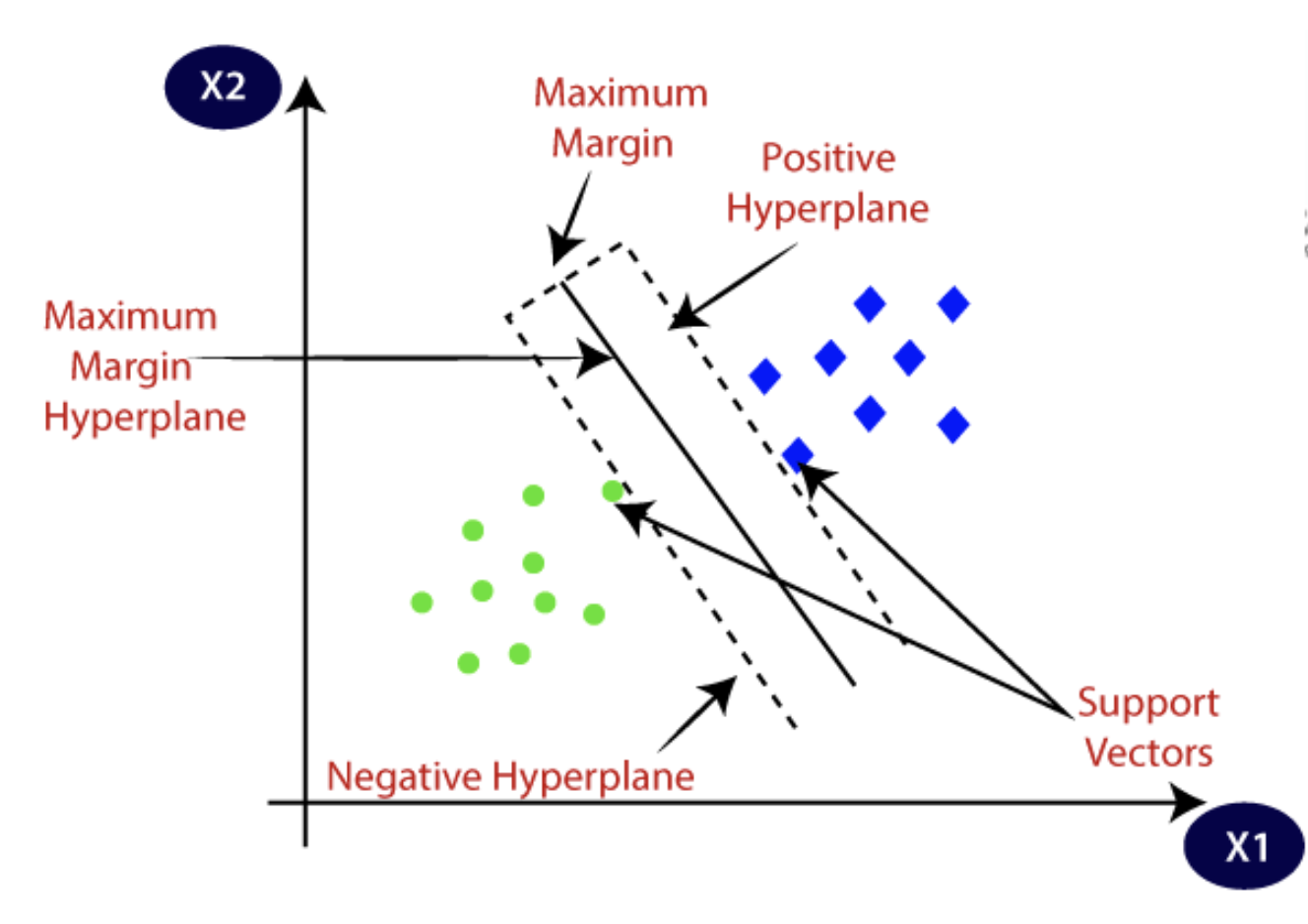
Source: Javatpoint
Étant donné que ces données sont linéairement distinctes, l'algorithme appliqué est connu sous le nom de SVM linéaire, et le classificateur qu'il produit est le classificateur SVM. Cet algorithme est efficace pour les problèmes de classification et d'analyse de régression.
2. SVM non linéaires ou noyau
Lorsque les données ne sont pas linéairement séparables par une ligne droite, un classificateur SVM non linéaire ou noyau est utilisé. Pour les données non linéaires, la classification est effectuée en ajoutant des caractéristiques dans des dimensions supérieures plutôt que de se fier à l'espace 2D.
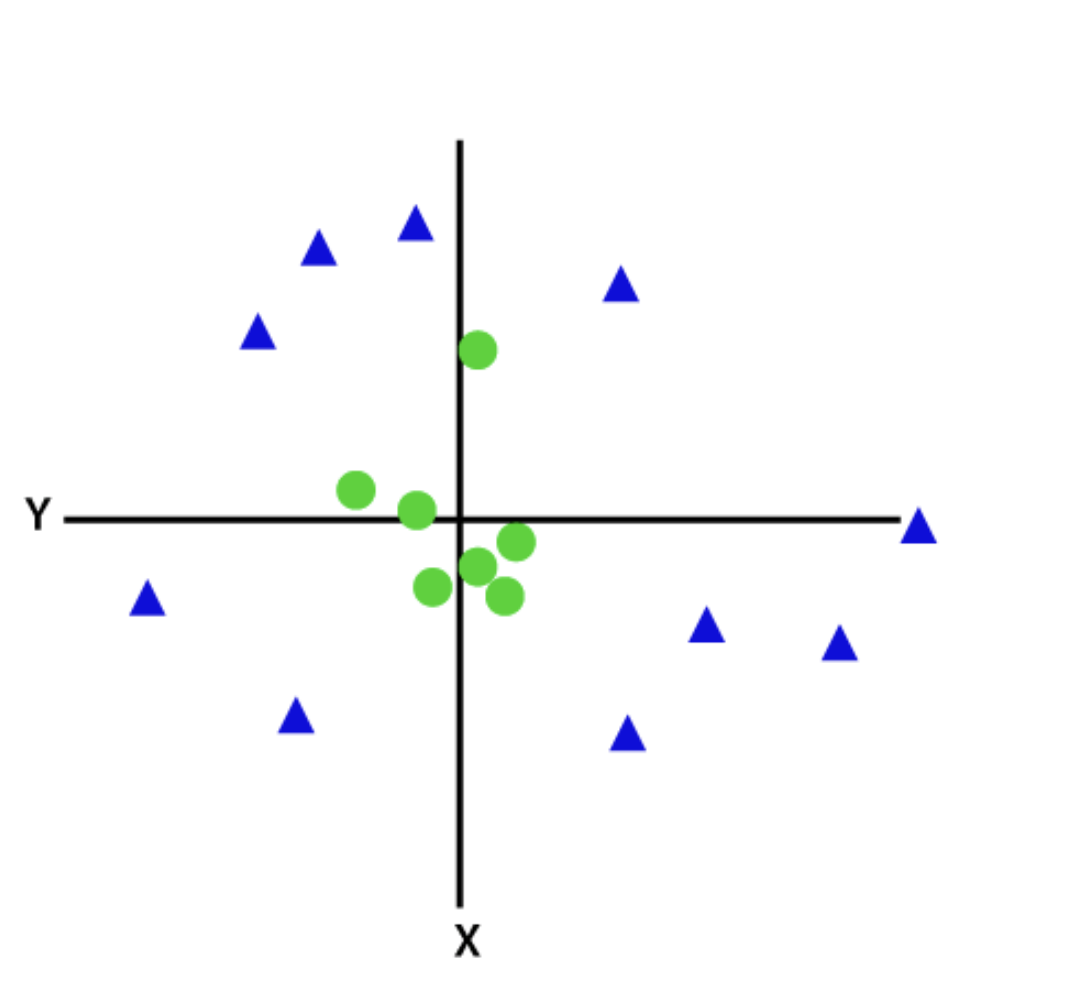
Source: Javatpoint
Après transformation, ajouter un hyperplan qui sépare facilement les classes ou catégories devient facile. Ces SVM sont généralement utilisés pour les problèmes d'optimisation avec plusieurs variables.
La clé des SVM non linéaires est le trick du noyau. En appliquant différentes fonctions noyau telles que le noyau linéaire, polynomial, fonction de base radiale (RDF) ou noyau sigmoïde, les SVM peuvent gérer une grande variété de structures de données. Le choix du noyau dépend des caractéristiques des données et du problème à résoudre.
Comment fonctionne une machine à vecteurs de support ?
L'algorithme de machine à vecteurs de support vise à identifier un hyperplan pour séparer les points de données de différentes classes. Ils ont été potentiellement conçus pour des problèmes de classification binaire mais ont évolué pour résoudre des problèmes multiclasses.
En fonction des caractéristiques des données, les SVM utilisent des fonctions noyau pour transformer les caractéristiques des données en dimensions supérieures, ce qui facilite l'ajout d'un hyperplan séparant les différentes classes d'ensembles de données. Cela se produit grâce à la technique du trick du noyau, où la transformation des données est réalisée de manière efficace et rentable.
Pour comprendre comment fonctionne un SVM, nous devons examiner comment un classificateur SVM est construit. Cela commence par diviser les données. Divisez vos données en un ensemble d'entraînement et un ensemble de test. Cela vous aidera à identifier les valeurs aberrantes ou les données manquantes. Bien que cela ne soit pas techniquement nécessaire, c'est une bonne pratique.
Ensuite, vous pouvez importer un module SVM pour n'importe quelle bibliothèque. Scikit-learn est une bibliothèque Python populaire pour les machines à vecteurs de support. Elle offre une implémentation SVM efficace pour les tâches de classification et de régression. Commencez par entraîner vos échantillons sur le classificateur et prédire les réponses. Comparez l'ensemble de test et les données prédites pour comparer la précision pour l'évaluation des performances.
Il existe d'autres métriques d'évaluation que vous pouvez utiliser, comme :
- F1-score calcule combien de fois un modèle a fait une prédiction correcte sur l'ensemble du jeu de données. Il combine les scores de précision et de rappel d'un modèle.
- Score de précision mesure la fréquence à laquelle un modèle d'apprentissage automatique prédit correctement la classe positive.
- Rappel évalue la fréquence à laquelle un modèle ML identifie les vrais positifs parmi tous les échantillons positifs réels dans le jeu de données.
Ensuite, vous pouvez ajuster les hyperparamètres pour améliorer les performances d'un modèle SVM. Vous obtenez les hyperparamètres en itérant sur différents noyaux, valeurs gamma et régularisation, ce qui vous aide à trouver la combinaison la plus optimale.
Applications des machines à vecteurs de support
Les SVM trouvent des applications dans plusieurs domaines. Regardons quelques exemples de SVM appliqués à des problèmes du monde réel.
- Estimation de la résistance de la surface du sol : Calculer la liquéfaction du sol est essentiel dans la conception de structures de génie civil, en particulier dans les zones sujettes aux tremblements de terre. Les SVM aident à prédire si la liquéfaction se produit ou non dans le sol en créant des modèles qui incluent plusieurs variables pour évaluer la résistance du sol.
- Problème de géosondage : Les SVM aident à suivre la structure en couches de la planète. Les propriétés de régularisation de la formulation de vecteur de support sont appliquées au problème inverse de géosondage. Ici, les résultats estiment les variables ou paramètres qui les ont produits. Le processus implique des fonctions linéaires et des modèles algorithmiques de vecteur de support séparant les données électromagnétiques.
- Détection de l'homologie à distance des protéines : Les modèles SVM utilisent des fonctions noyau pour détecter les similitudes dans les séquences de protéines basées sur les séquences d'acides aminés. Cela aide à catégoriser les protéines en paramètres structurels et fonctionnels, ce qui est important en biologie computationnelle.
- Détection faciale et classification des expressions : Les SVM classent les structures faciales des non-faciales. Ces modèles analysent les pixels et classent les caractéristiques en caractéristiques faciales ou non faciales. À la fin, le processus crée une frontière de décision carrée autour de la structure faciale en fonction de l'intensité des pixels.
- Catégorisation de texte et reconnaissance de l'écriture manuscrite : Ici, chaque document porte un score comparé à une valeur seuil, ce qui facilite sa classification dans la catégorie pertinente. Pour reconnaître l'écriture manuscrite, les modèles SVM sont d'abord entraînés avec des données d'entraînement sur l'écriture manuscrite, puis ils séparent l'écriture humaine et informatique en fonction du score.
- Détection de stéganographie : Les SVM aident à garantir que les images numériques ne sont pas contaminées ou altérées par quiconque. Ils séparent chaque pixel et les stockent dans différents ensembles de données que les SVM analysent plus tard.
Résoudre les problèmes de classification avec précision
Les machines à vecteurs de support aident à résoudre les problèmes de classification tout en faisant des prédictions précises. Ces algorithmes peuvent facilement gérer des données linéaires et non linéaires, ce qui les rend adaptés à diverses applications, de la classification de texte à la reconnaissance d'image.
De plus, les SVM réduisent le surapprentissage, qui se produit lorsque le modèle apprend trop des données d'entraînement, affectant ses performances sur de nouvelles données. Ils se concentrent sur les points de données importants, appelés vecteurs de support, les aidant à fournir des résultats fiables et précis.
En savoir plus sur les modèles d'apprentissage automatique et comment les entraîner.
Édité par Monishka Agrawal